Article source: qubits
 Image source: Generated by Unbounded AI
Image source: Generated by Unbounded AI
The OpenAI palace fight drama has just ended, and it will immediately set off another uproar!
Reuters revealed that before Altman was fired, several researchers wrote warning letters to the board of directors that may have triggered the whole incident:
The next-generation AI model, internally named Q (pronounced Q-Star), is too powerful and advanced to threaten humanity.
Q* is led by the central figure of this storm, Chief Scientist Ilya Sutskever.
People quickly linked Altman’s previous remarks at the APEC summit:
There have been four times in OpenAI’s history, most recently in the last few weeks, when I was in the room when we pushed through the veil of ignorance and reached the frontier of discovery, which was the highest honor of my career. ”
 Q* may have the following core characteristics that are considered a key step on the road to AGI or superintelligence.
Q* may have the following core characteristics that are considered a key step on the road to AGI or superintelligence.
- Break through the limitations of human data and can produce huge amounts of training data by yourself
- Ability to learn and improve independently
The news quickly sparked a huge discussion, and Musk also asked with a link.
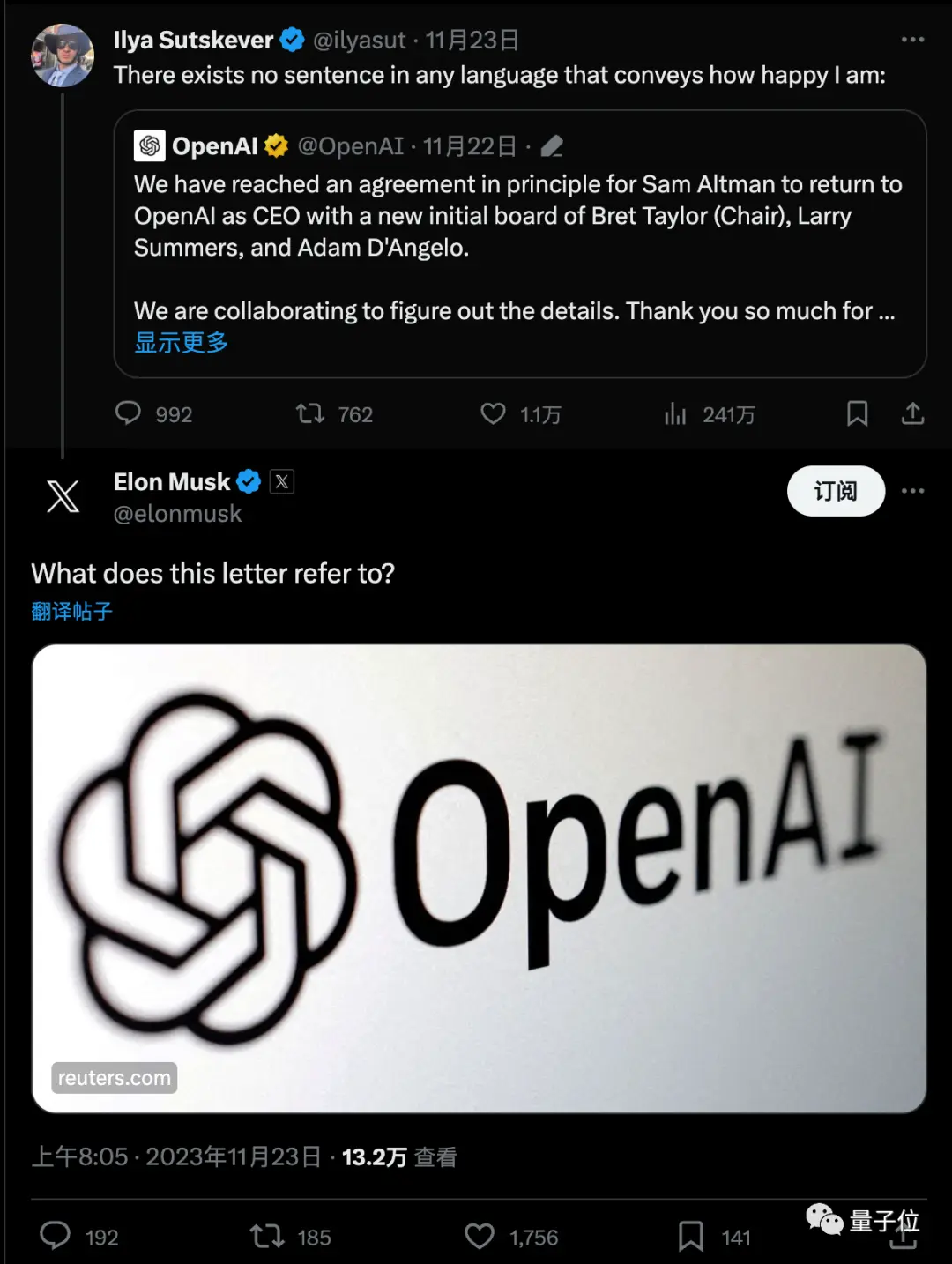 The latest meme is that, seemingly overnight, people have gone from being experts on the board of directors of Ultraman and OpenAI to Q* experts.
The latest meme is that, seemingly overnight, people have gone from being experts on the board of directors of Ultraman and OpenAI to Q* experts.

Breaking Data Limits
According to the latest news from The Information, Q’* was formerly known as GPT-Zero, a project initiated by Ilya Sutskever, with a name that pays homage to DeepMind’s Alpha-Zero.
Alpha-Zero doesn’t need to learn human chess games, but learns to play Go by playing against himself.
GPT-Zero enables next-generation AI models to be trained using synthetic data instead of relying on real-world data such as text or images scraped from the internet.
In 2021, GPT-Zero was officially established, and there has not been much directly related news since then.
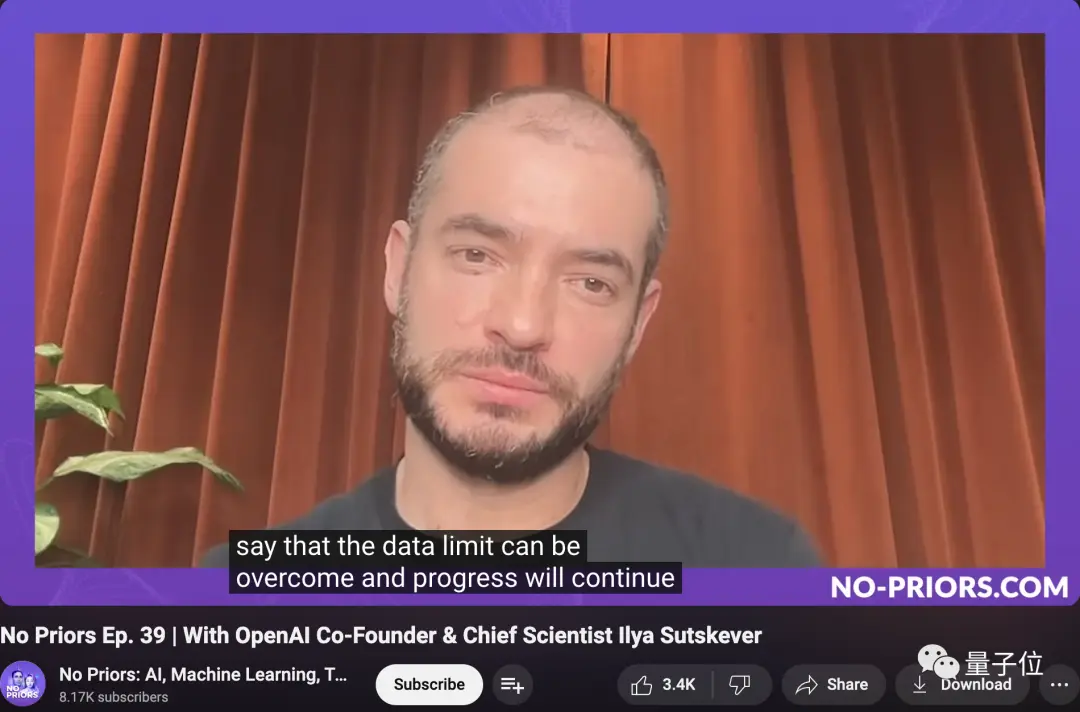
But just a few weeks ago, Ilya mentioned in an interview:
Without going into too much detail, I just want to say that data limitations can be overcome and progress will continue.
 Based on GPT-Zero, Q* was developed by Jakub Pachocki and Szymon Sidor.
Based on GPT-Zero, Q* was developed by Jakub Pachocki and Szymon Sidor.
Both of them were early members of OpenAI, and they were also the first members to announce that they would follow Ultraman to Microsoft.
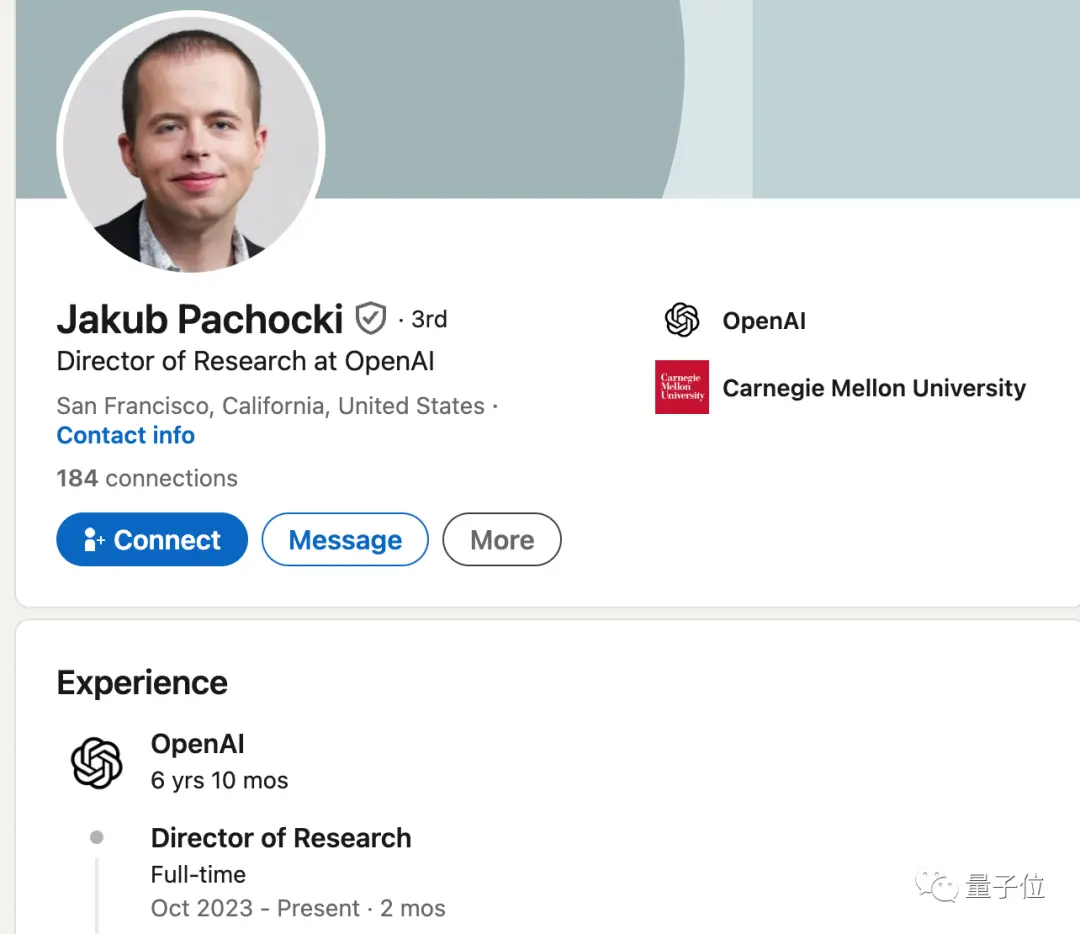
 Jakub Pachocki, who was promoted to Director of Research last month, has been a core contributor to many of his past breakthroughs, including the Dota 2 project and GPT-4 pre-training.
Jakub Pachocki, who was promoted to Director of Research last month, has been a core contributor to many of his past breakthroughs, including the Dota 2 project and GPT-4 pre-training.
 Szymon Sidor has also worked on the Dota 2 project, and his bio is “building AGI, line by line”.
Szymon Sidor has also worked on the Dota 2 project, and his bio is “building AGI, line by line”.
 In the Reuters message, it was mentioned that Q* was given huge computing resources to be able to solve certain mathematical problems. Although the current mathematical ability is only at the elementary school level, the researchers are very optimistic about future success.
In the Reuters message, it was mentioned that Q* was given huge computing resources to be able to solve certain mathematical problems. Although the current mathematical ability is only at the elementary school level, the researchers are very optimistic about future success.
In addition, it was mentioned that OpenAI has established a new team of “AI scientists”, which is a merger of the two teams of “Code Gen” and “Math Gen” in the early days, and is exploring and optimizing to improve the reasoning ability of AI, and eventually carry out scientific exploration.
Three Guesses
There is no more specific word out about what exactly Q* is, but some have speculated from the name that it may have something to do with Q-Learning.
Q-Learning, which dates back to 1989, is a model-free reinforcement learning algorithm that does not require modeling of the environment, even for transfer functions with random factors or reward functions, and can be adapted without special changes.
In contrast to other reinforcement learning algorithms, Q-Learning focuses on learning the value of each state-action pair to decide which action will bring the greatest return in the long run, rather than directly learning the action strategy itself.
The second guess has to do with OpenAI’s release in May that it solves math problems through “process supervision” rather than “result supervision”.
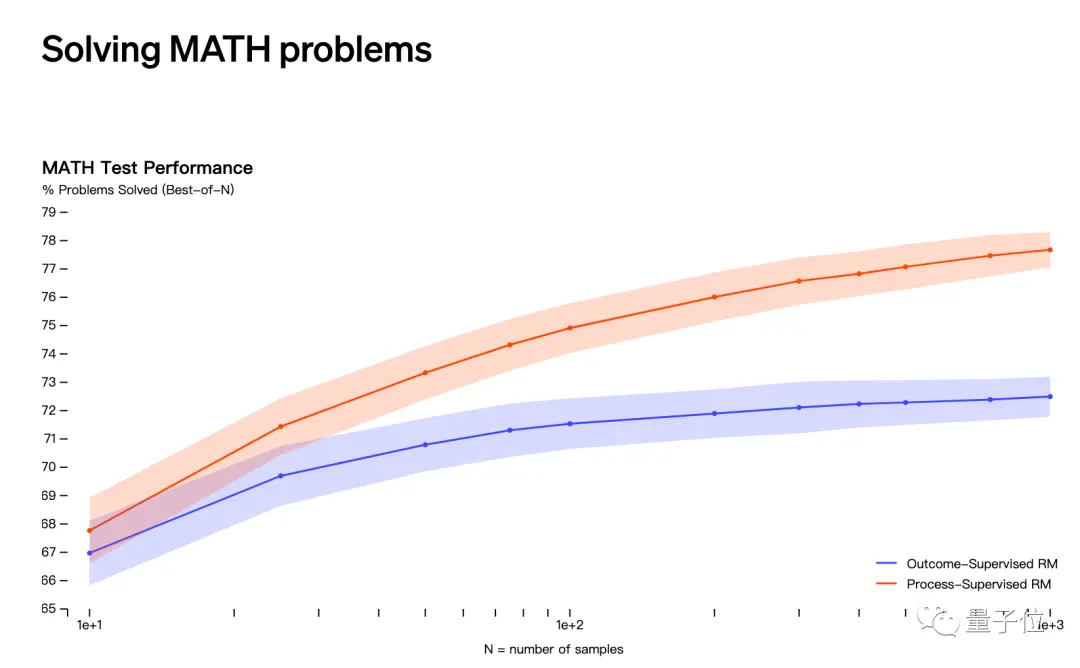 However, the names of Jakub Pachocki and Szymon Sidor do not appear in the list of contributors to this study.
However, the names of Jakub Pachocki and Szymon Sidor do not appear in the list of contributors to this study.
 There is also speculation that Noam Brown, the “father of Depo AI” who joined OpenAI in July, may also be involved in the project.
There is also speculation that Noam Brown, the “father of Depo AI” who joined OpenAI in July, may also be involved in the project.
 When he joined, he said that he wanted to generalize the methods that used to be only applicable to games, and that reasoning might be 1000 times slower and more expensive, but might discover new drugs or prove mathematical conjectures.
When he joined, he said that he wanted to generalize the methods that used to be only applicable to games, and that reasoning might be 1000 times slower and more expensive, but might discover new drugs or prove mathematical conjectures.
It is in line with the rumored descriptions of “requiring huge computing resources” and “being able to solve certain mathematical problems”.
 While more speculation is still being made, whether synthetic data and reinforcement learning can take AI to the next level has become one of the most discussed topics in the industry.
While more speculation is still being made, whether synthetic data and reinforcement learning can take AI to the next level has become one of the most discussed topics in the industry.
Nvidia scientist Fan Linxi believes that synthetic data will provide trillions of high-quality training tokens, and the key question is how to maintain quality and avoid falling into bottlenecks prematurely.
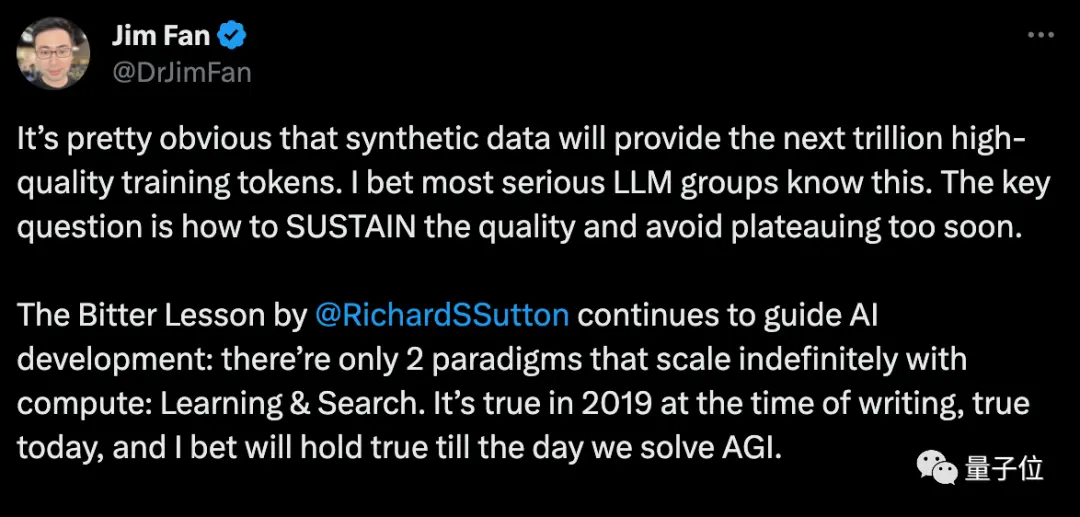 Musk agrees, mentioning that every book written by a human can fit on a hard drive, and synthetic data will be far beyond that.
Musk agrees, mentioning that every book written by a human can fit on a hard drive, and synthetic data will be far beyond that.
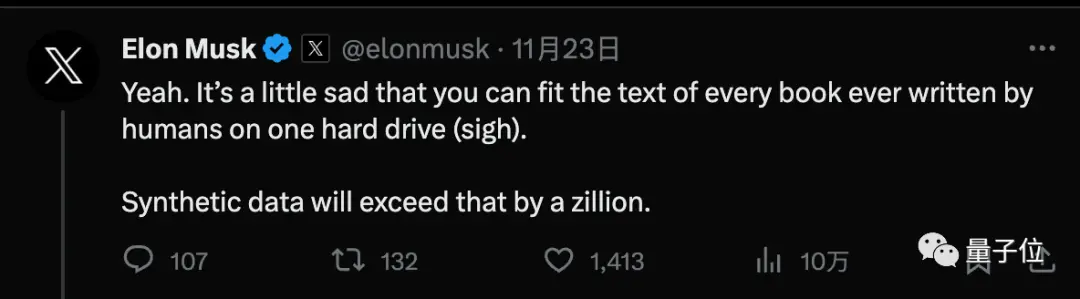 But LeCun, one of the Turing Award triumvirate, argues that more synthetic data is a stopgap measure, and that AI will ultimately need to learn with very little data, just like humans or animals.
But LeCun, one of the Turing Award triumvirate, argues that more synthetic data is a stopgap measure, and that AI will ultimately need to learn with very little data, just like humans or animals.
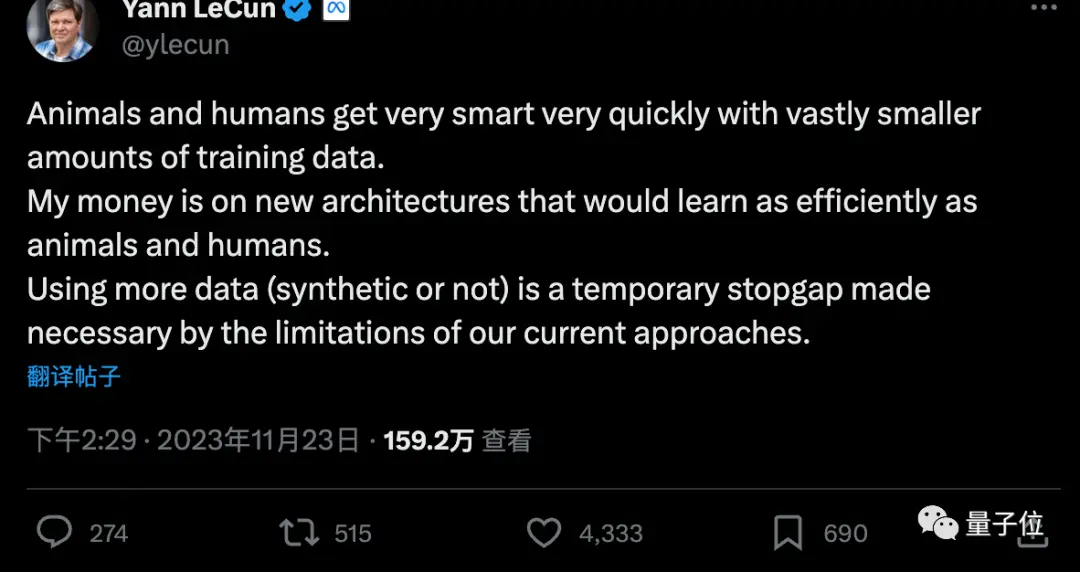 Cameron R. Wolfe, Ph.D. at Rice University, said Q-Learning may not be the secret to unlocking AGI.
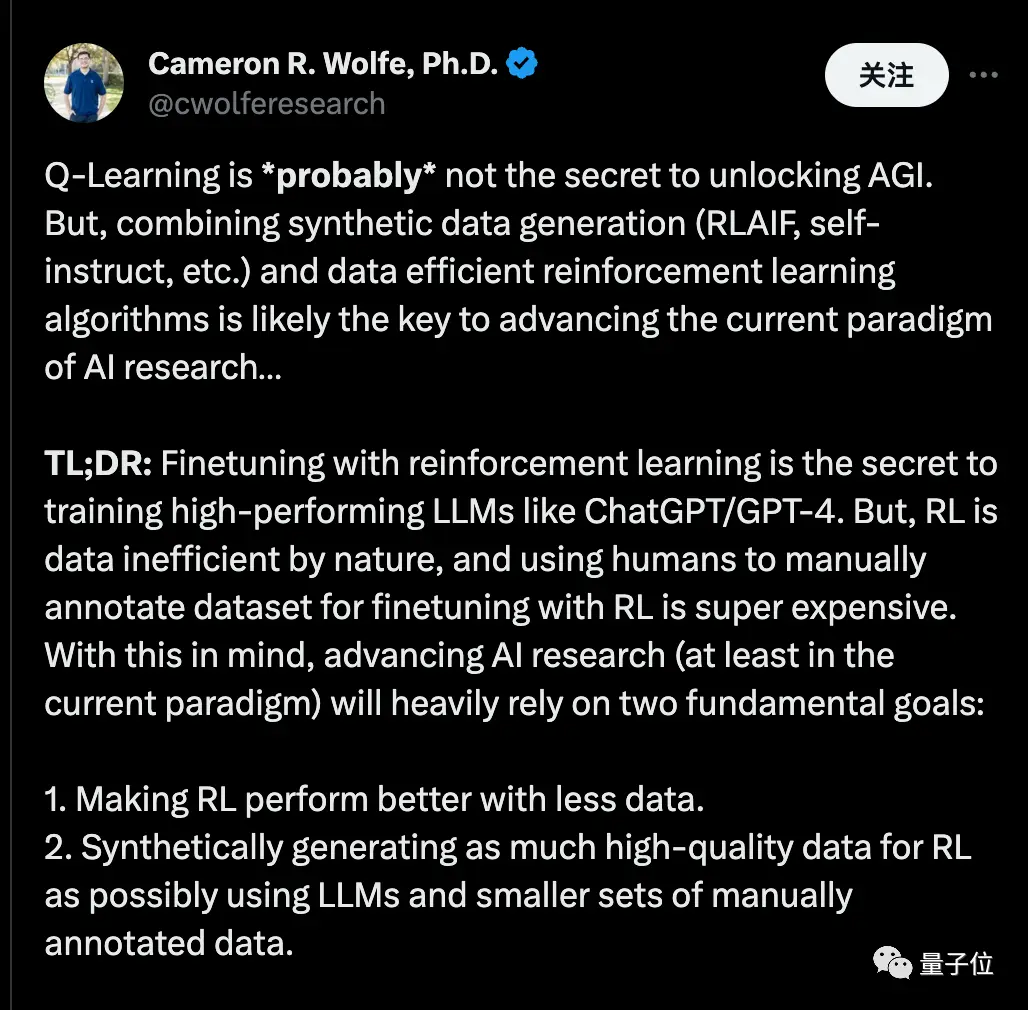
Cameron R. Wolfe, Ph.D. at Rice University, said Q-Learning may not be the secret to unlocking AGI.
But combining “synthetic data” with “data-efficient reinforcement learning algorithms” may be the key to advancing the current AI research paradigm.
He said that fine-tuning through reinforcement learning is the secret to training high-performance large models, such as ChatGPT/GPT-4. However, reinforcement learning is inherently data-inefficient, and it is very expensive to fine-tune reinforcement learning using manually labeled datasets by humans. With this in mind, advancing AI research (at least in the current paradigm) will rely heavily on two fundamental goals:
- Make reinforcement learning perform better with less data.
- Synthesize and generate high-quality data using large models and a small amount of manually annotated data whenever possible.
… If we stick to the prediction of the next token paradigm (i.e. pre-trained -> SFT -> RLHF) using Decoder-only Transformer… The combination of these two methods will give everyone access to cutting-edge training techniques, not just research teams with a lot of money!
One More Thing
No one within OpenAI has yet responded to Q’s message.
But Altman has just revealed that he had a few hours of friendly conversation with Quora founder Adam D’Angelo, who remained on the board.
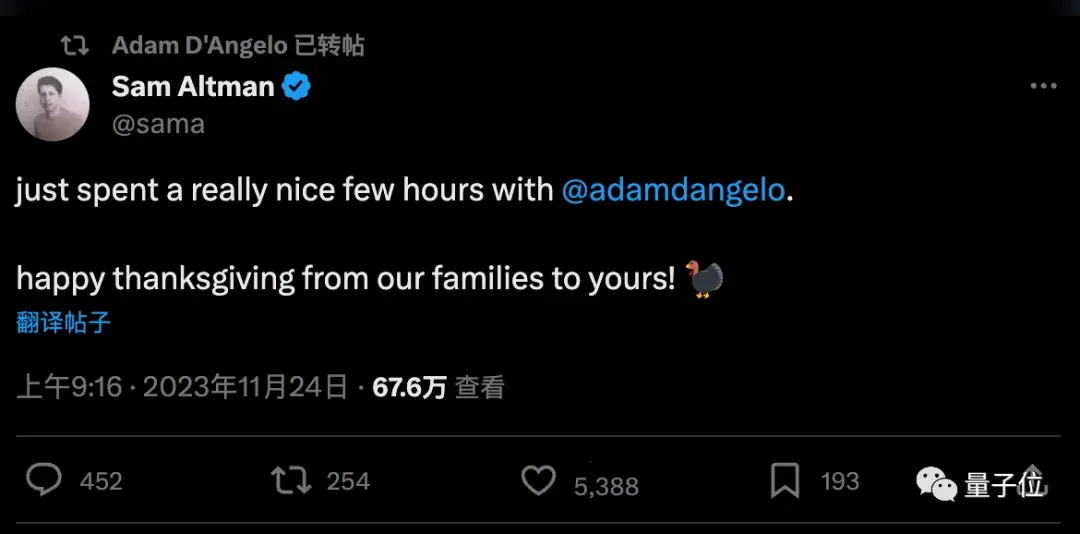 It seems that whether or not Adam D’Angelo was behind the incident, as everyone had speculated, has now reached a settlement.
It seems that whether or not Adam D’Angelo was behind the incident, as everyone had speculated, has now reached a settlement.
Reference Links:
[1]
[2]
[3]
[4]
[5]
[6]