GateUser-40a7d570
現在、コンテンツはありません
GateUser-40a7d570
素晴らしい給料日、ありがとうエロン、これは馬たちにまっすぐ行きます
原文表示
- 報酬
- いいね
- コメント
- リポスト
- 共有
たった2回のクリックで人生を変える取引が可能です
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
悲しい馬の事実
馬はほとんどの映画館に入ることができず、それが彼らの映画知識を大きく制限している
原文表示馬はほとんどの映画館に入ることができず、それが彼らの映画知識を大きく制限している
- 報酬
- いいね
- コメント
- リポスト
- 共有
おはようございます、シドニーから
原文表示
- 報酬
- いいね
- コメント
- リポスト
- 共有
Xの最新情報を追っています。
ハンタウイルスについて心配する必要がありますか?
原文表示ハンタウイルスについて心配する必要がありますか?
- 報酬
- いいね
- コメント
- リポスト
- 共有
- 報酬
- いいね
- コメント
- リポスト
- 共有
- 報酬
- いいね
- コメント
- リポスト
- 共有
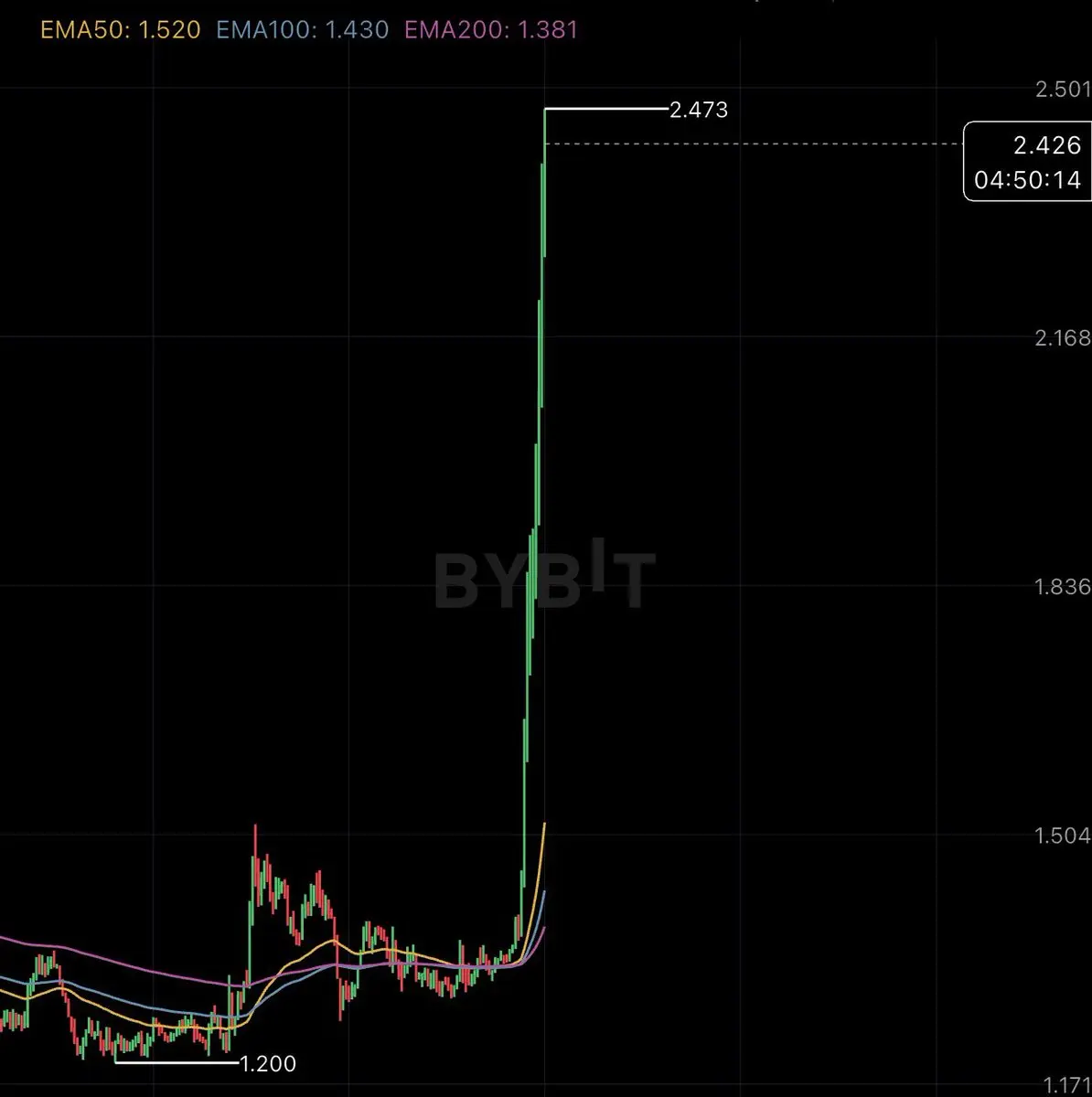
偽のプライバシーコインが高騰しています
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
- 報酬
- いいね
- コメント
- リポスト
- 共有
報告されたインフレーション vs 実際のインフレーション
原文表示

- 報酬
- いいね
- コメント
- リポスト
- 共有
朝のコーヒー代を株式50%、現金50%で支払う
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
大きな週が待っています。おはようございます
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
小行星を送ってください
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
時々、もし私がそんなに多くの馬を所有していなかったら、どんな生活を送っているだろうかと考えることがあります。
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
- 報酬
- いいね
- コメント
- リポスト
- 共有
RBAはちょうどキャッシュレートを4.35%に引き上げました。これで3回連続の引き上げです。
2025年に行われたすべての利下げは帳消しになっています。
Westpacは、6月と8月にさらに2回の利上げを予測しており、レートは4.85%に達します。これはオーストラリアが2008年以来見たことのない水準です。
3月のCPIは2月の3.7%から4.6%に上昇し、燃料とエネルギーが大部分の原因です。
戦争により石油価格が上昇し、そのコストが今や私たちの食料品、交通費、家賃に反映されています。
私たちは実質的に戦争の代償を住宅ローンの返済を通じて支払っています。100万ドルのローンは、2026年初めと比べて月額453ドル余分にかかります。
オーストラリア人はパンデミックの最悪期にはもっと楽観的でした。今の方が、90年代初頭の不況よりも消費者にとって悪化しています。
私たちはスタグフレーションの状態にあり、インフレと失業率が同時に上昇しています。
原文表示2025年に行われたすべての利下げは帳消しになっています。
Westpacは、6月と8月にさらに2回の利上げを予測しており、レートは4.85%に達します。これはオーストラリアが2008年以来見たことのない水準です。
3月のCPIは2月の3.7%から4.6%に上昇し、燃料とエネルギーが大部分の原因です。
戦争により石油価格が上昇し、そのコストが今や私たちの食料品、交通費、家賃に反映されています。
私たちは実質的に戦争の代償を住宅ローンの返済を通じて支払っています。100万ドルのローンは、2026年初めと比べて月額453ドル余分にかかります。
オーストラリア人はパンデミックの最悪期にはもっと楽観的でした。今の方が、90年代初頭の不況よりも消費者にとって悪化しています。
私たちはスタグフレーションの状態にあり、インフレと失業率が同時に上昇しています。
- 報酬
- いいね
- コメント
- リポスト
- 共有
RBAはちょうどキャッシュレートを4.35%に引き上げました。これで3回連続の引き上げです。
2025年に行われたすべての利下げは帳消しになっています。
Westpacは6月と8月にさらに2回の利上げを予測しており、レートは4.85%に達します。これはオーストラリアが2008年以来見たことのない水準です。
3月のCPIは2月の3.7%から4.6%に上昇し、燃料とエネルギーが大部分の原因です。
戦争により石油価格が上昇し、そのコストが今や私たちの食料品、交通費、家賃に反映されています。
私たちは実質的に戦争の代償を住宅ローンの返済を通じて支払っています。100万ドルのローンは、2026年初めと比べて月額453ドル余分にかかります。
オーストラリア人はパンデミックの最悪期にはもっと楽観的でした。今の方が、90年代初頭の不況よりも消費者にとって悪化しています。
私たちはスタグフレーションの中にあり、インフレと失業率が同時に上昇しています。
原文表示2025年に行われたすべての利下げは帳消しになっています。
Westpacは6月と8月にさらに2回の利上げを予測しており、レートは4.85%に達します。これはオーストラリアが2008年以来見たことのない水準です。
3月のCPIは2月の3.7%から4.6%に上昇し、燃料とエネルギーが大部分の原因です。
戦争により石油価格が上昇し、そのコストが今や私たちの食料品、交通費、家賃に反映されています。
私たちは実質的に戦争の代償を住宅ローンの返済を通じて支払っています。100万ドルのローンは、2026年初めと比べて月額453ドル余分にかかります。
オーストラリア人はパンデミックの最悪期にはもっと楽観的でした。今の方が、90年代初頭の不況よりも消費者にとって悪化しています。
私たちはスタグフレーションの中にあり、インフレと失業率が同時に上昇しています。
- 報酬
- いいね
- コメント
- リポスト
- 共有
GME/ebayの取引が意味を持つ唯一の方法は、彼らが株を徹底的に買い上げる場合です
おそらく、買い増しのサインです
原文表示おそらく、買い増しのサインです
- 報酬
- いいね
- コメント
- リポスト
- 共有
GameStopは$56b を買収するために入札しています。GMEのニュース前の時価総額は118億ドルでした。
買い手はターゲットの4分の1の規模です。
ライアン・コーエンは、クロージングから12ヶ月以内に20億ドルの年間節約を見つける必要がある取引のために$20b の債務資金調達を確保しました。
本当にこれが承認されるのか気になっています。
買い手はターゲットの4分の1の規模です。
ライアン・コーエンは、クロージングから12ヶ月以内に20億ドルの年間節約を見つける必要がある取引のために$20b の債務資金調達を確保しました。
本当にこれが承認されるのか気になっています。
GME9.16%
- 報酬
- いいね
- コメント
- リポスト
- 共有
ミーム市場が戻ってきたようだ。
みんな何を買っている?
原文表示みんな何を買っている?
- 報酬
- いいね
- コメント
- リポスト
- 共有