OpenAI神秘新模型Q*曝光,太強大讓董事會警惕,或是奧特曼被開除導火索
文章來源:量子位
 圖片來源:由無界 AI生成
圖片來源:由無界 AI生成
OpenAI宮鬥大戲剛剛落幕,馬上又掀起另一場軒然大波!
路透社曝光,在奧特曼被解僱之前,幾位研究人員給董事會寫的警告信可能是整個事件導火索:
內部名為Q (發音為Q-Star)*的下一代AI模型,過於強大和先進,可能會威脅人類。
Q*正是由這場風暴的中心人物,首席科學家Ilya Sutskever主導。
人們迅速把奧特曼此前在APEC峰會上的發言聯繫在了一起:
OpenAI歷史上已經有過四次,最近一次就是在過去幾周,當我們推開無知之幕並抵達探索發現的前沿時,我就在房間里,這是職業生涯中的最高榮譽。 ”
 Q*可能有以下幾個核心特性,被認為是通往AGI或超級智慧的關鍵一步。
Q*可能有以下幾個核心特性,被認為是通往AGI或超級智慧的關鍵一步。
- 突破了人類數據的限制,可以自己生產巨量訓練數據
- 有自主學習和自我改進的能力
這則消息迅速引發了巨大討論,馬斯克也帶著連結來追問。
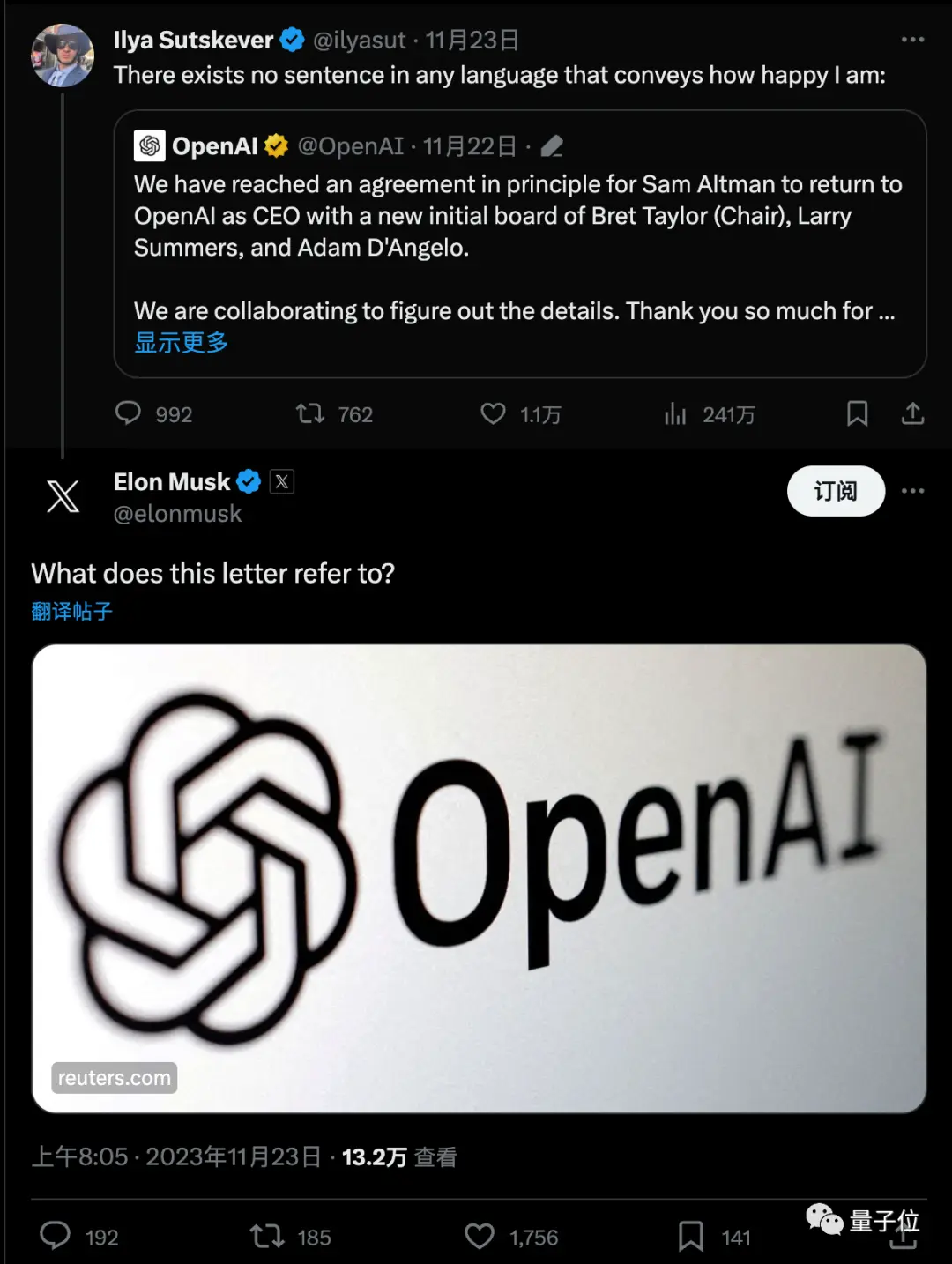 最新的梗圖則是,好像一夜之間,人們都從研究奧特曼和OpenAI董事會的專家,變成了Q*專家。
最新的梗圖則是,好像一夜之間,人們都從研究奧特曼和OpenAI董事會的專家,變成了Q*專家。

突破數據限制
根據來自The Information的最新消息,Q*的前身是GPT-Zero,這個專案由Ilya Sutskever發起,名字致敬了DeepMind的Alpha-Zero。
Alpha-Zero無需學習人類棋譜,通過自己跟自己博弈來掌握下圍棋。
GPT-Zero讓下一代AI模型不用依賴互聯網上抓取的文本或圖片等真實世界數據,而是使用合成數據訓練。
2021年,GPT-Zero正式立項,此後並未有太多直接相關的消息傳出。
但就在幾周前,Ilya在一次訪談中提到:
不談太多細節,我只想說數據限制是可以被克服的,進步仍將繼續。
 在GPT-Zero的基礎上,由Jakub Pachocki和Szymon Sidor開發出了Q*。
在GPT-Zero的基礎上,由Jakub Pachocki和Szymon Sidor開發出了Q*。
兩人都是OpenAI早期成員,也都是第一批宣佈要跟著奧特曼去微軟的成員。
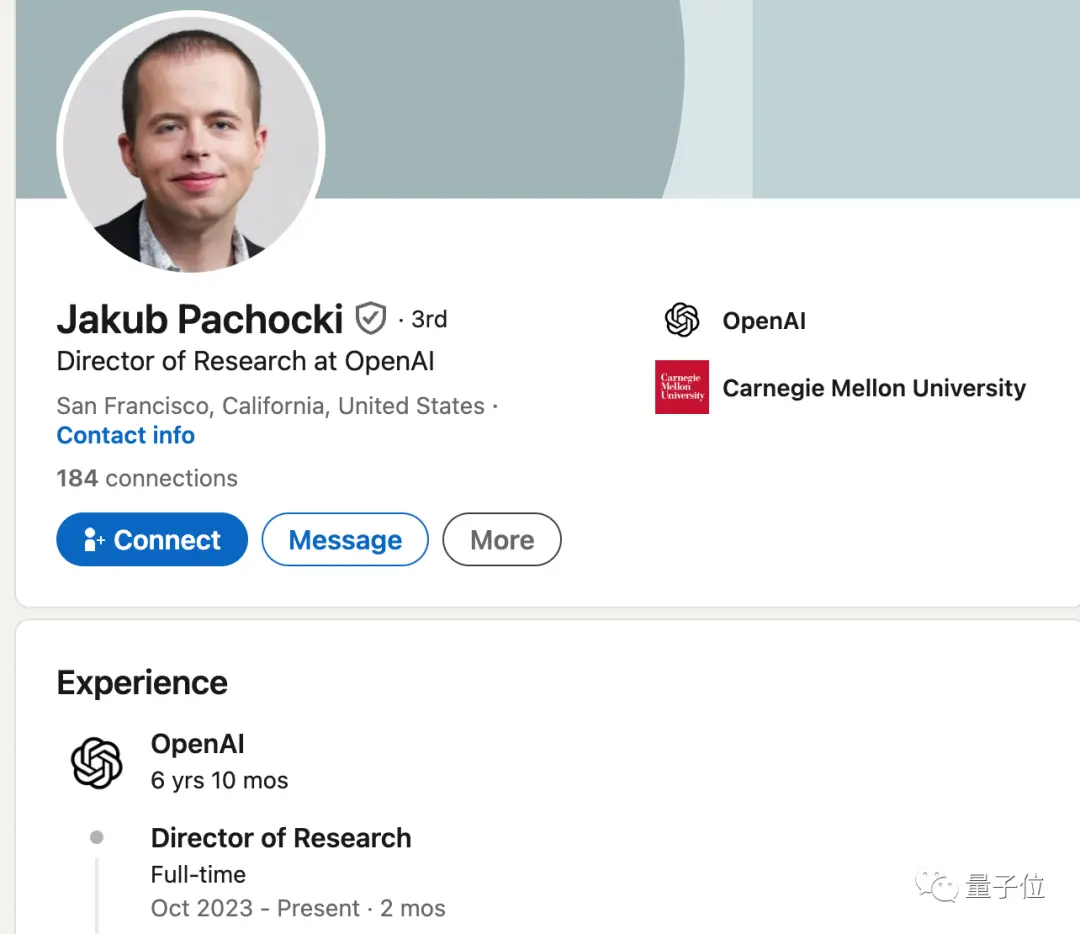
 Jakub Pachocki上個月剛剛晉陞研究總監,過去很多突破包括Dota 2專案和GPT-4的預訓練,他都是核心貢獻者。
Jakub Pachocki上個月剛剛晉陞研究總監,過去很多突破包括Dota 2專案和GPT-4的預訓練,他都是核心貢獻者。
 Szymon Sidor同樣參與過Dota 2專案,個人簡介是“正在造AGI,一行代碼接一行代碼”。
Szymon Sidor同樣參與過Dota 2專案,個人簡介是“正在造AGI,一行代碼接一行代碼”。
 在路透社的消息中,提到給Q*提供龐大的計算資源,能夠解決某些數學問題。 雖然目前數學能力僅達到小學水準,但讓研究者對未來的成功非常樂觀。
在路透社的消息中,提到給Q*提供龐大的計算資源,能夠解決某些數學問題。 雖然目前數學能力僅達到小學水準,但讓研究者對未來的成功非常樂觀。
另外還提到了OpenAI成立了“AI科學家”新團隊,由早期的“Code Gen”和“Math Gen”兩個團隊合併而來,正在探索優化提高AI的推理能力,並最終開展科學探索。
三種猜測
關於Q*到底是什麼沒有更具體的消息傳出,但一些人從名字猜測可能與Q-Learning有關。
Q-Learning可以追溯到1989年,是一種無模型強化學習演算法,不需要對環境建模,即使對帶有隨機因素的轉移函數或者獎勵函數也無需特別改動就可以適應。
與其他強化學習演算法相比,Q-Learning專注於學習每個狀態-行動對的價值,以決定哪個動作在長期會帶來最大的回報,而不是直接學習行動策略本身。
第二種猜測是與OpenAI在5月發佈的通過「過程監督」而不是「結果監督」解決數學問題有關。
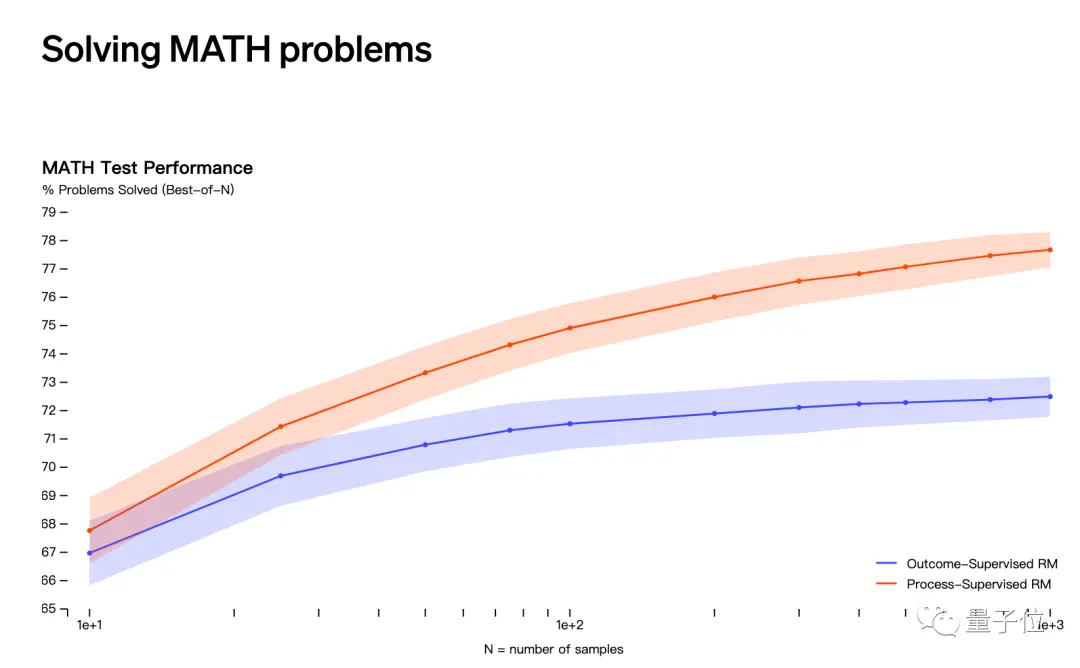 但這一研究成果的貢獻清單中並未出現Jakub Pachocki和Szymon Sidor的名字。
但這一研究成果的貢獻清單中並未出現Jakub Pachocki和Szymon Sidor的名字。
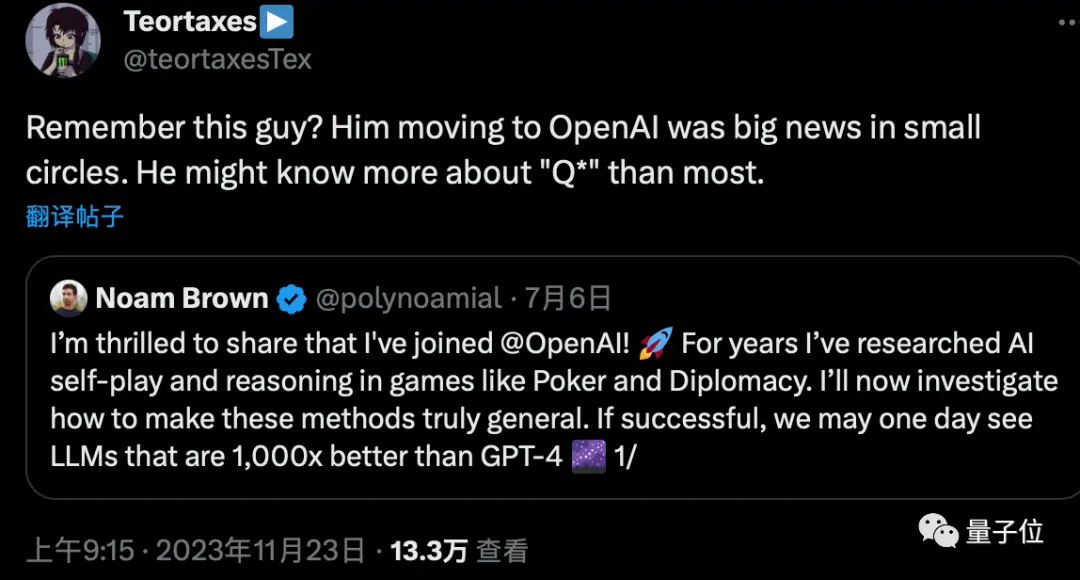
 另外有人猜測,7月份加入OpenAI的「德撲AI之父」Noam Brown也可能與這個項目有關。
另外有人猜測,7月份加入OpenAI的「德撲AI之父」Noam Brown也可能與這個項目有關。
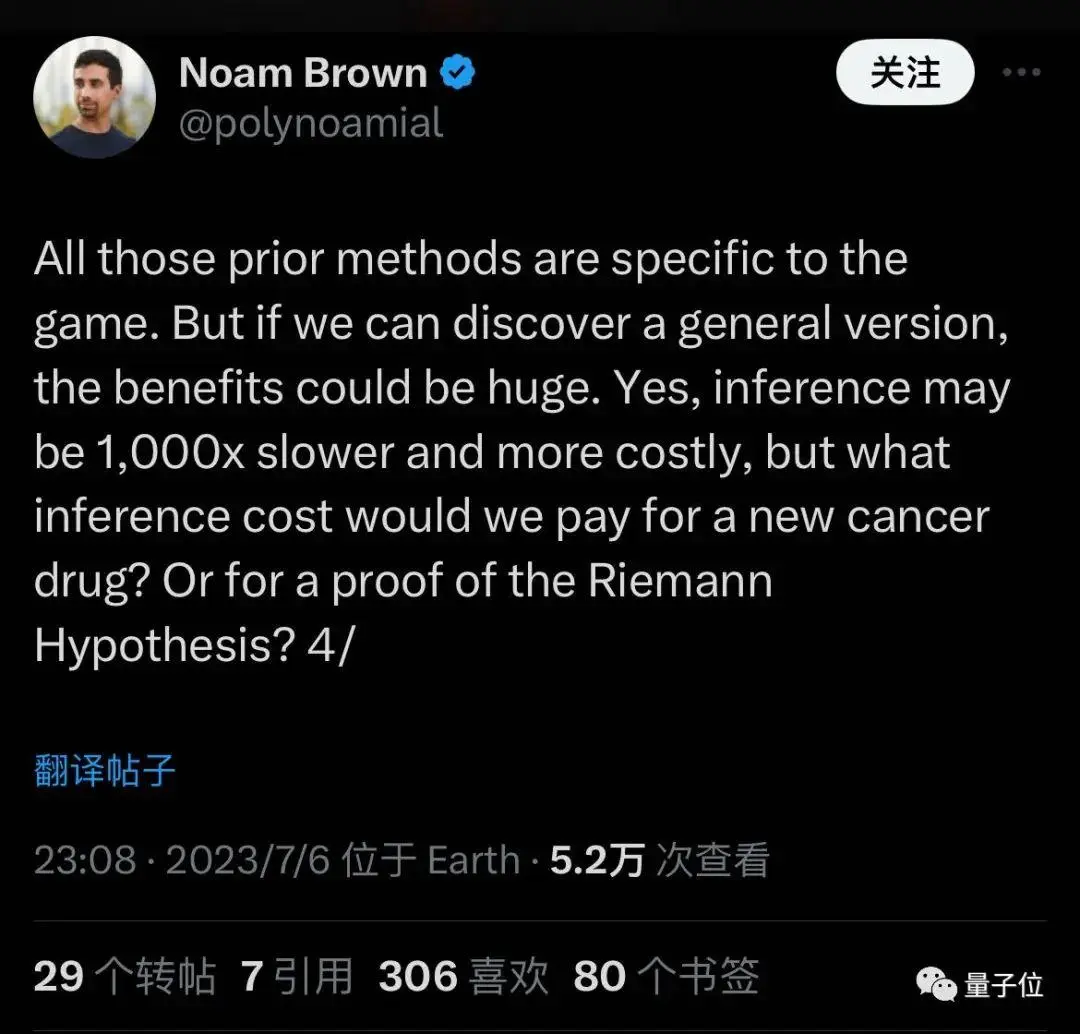
 他在加入時曾表示要把過去只適用於遊戲的方法通用化,推理可能會慢1000被成本也更高,但可能發現新藥物或證明數學猜想。
他在加入時曾表示要把過去只適用於遊戲的方法通用化,推理可能會慢1000被成本也更高,但可能發現新藥物或證明數學猜想。
符合傳言中「需要巨大計算資源」和「能解決一定數學問題」的描述。
 雖然更多的都還是猜測,但合成數據和強化學習是否能把AI帶到下一個階段,已經成了業內討論最多的話題之一。
雖然更多的都還是猜測,但合成數據和強化學習是否能把AI帶到下一個階段,已經成了業內討論最多的話題之一。
英偉達科學家范麟熙認為,合成數據將提供上萬億高品質的訓練token,關鍵問題是如何保持品質並避免過早陷入瓶頸。
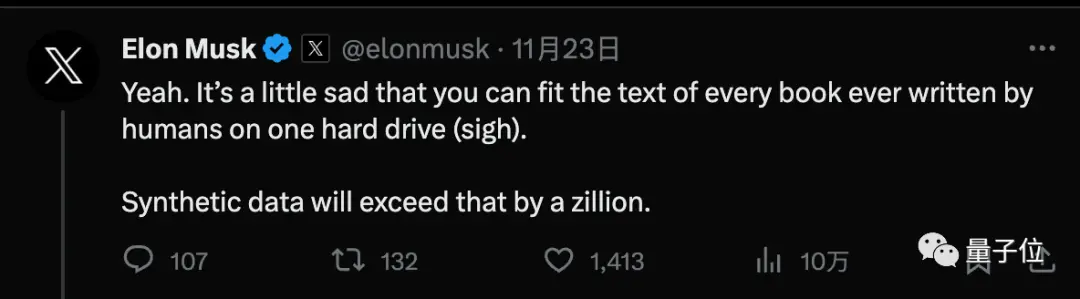
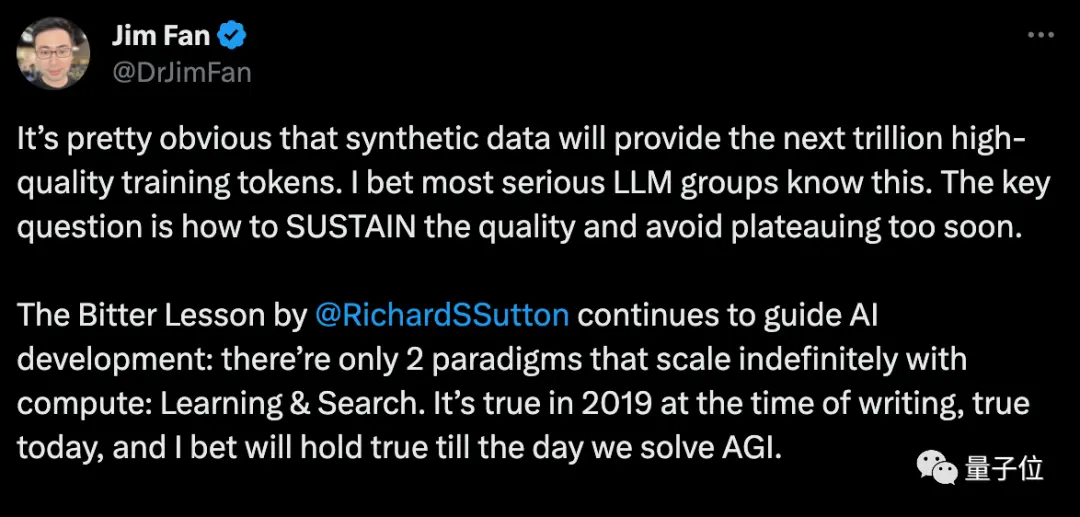 馬斯克同意這個看法,並提到人類所寫的每一本書只需一個硬碟就能裝下,合成數據將遠遠超出這個規模。
馬斯克同意這個看法,並提到人類所寫的每一本書只需一個硬碟就能裝下,合成數據將遠遠超出這個規模。
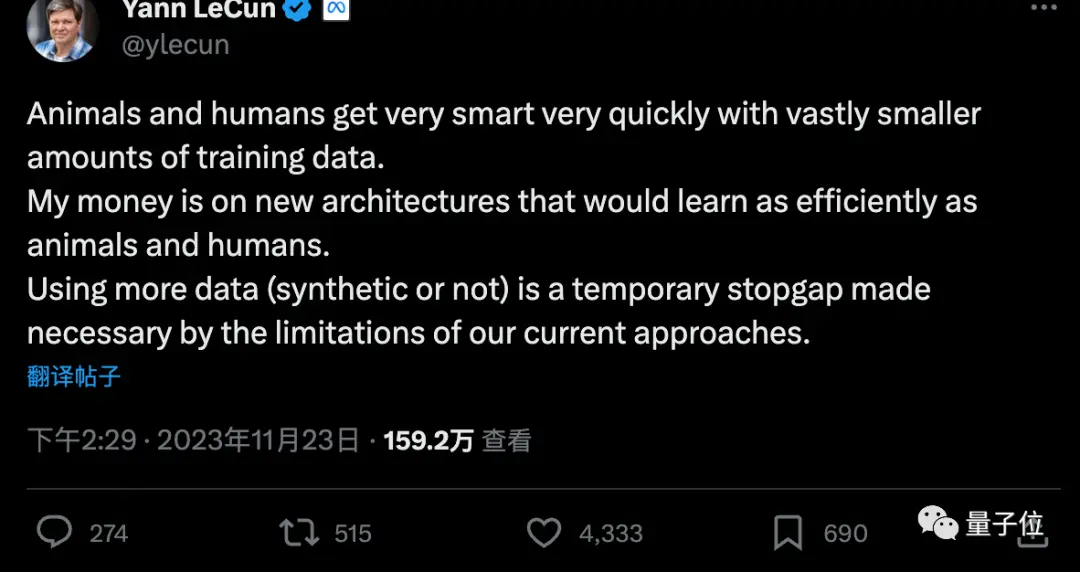
 但圖靈獎三巨頭中的LeCun認為,更多合成數據只是權宜之計,最終還是需要讓AI像人類或動物一樣只需極少數據就能學習。
但圖靈獎三巨頭中的LeCun認為,更多合成數據只是權宜之計,最終還是需要讓AI像人類或動物一樣只需極少數據就能學習。
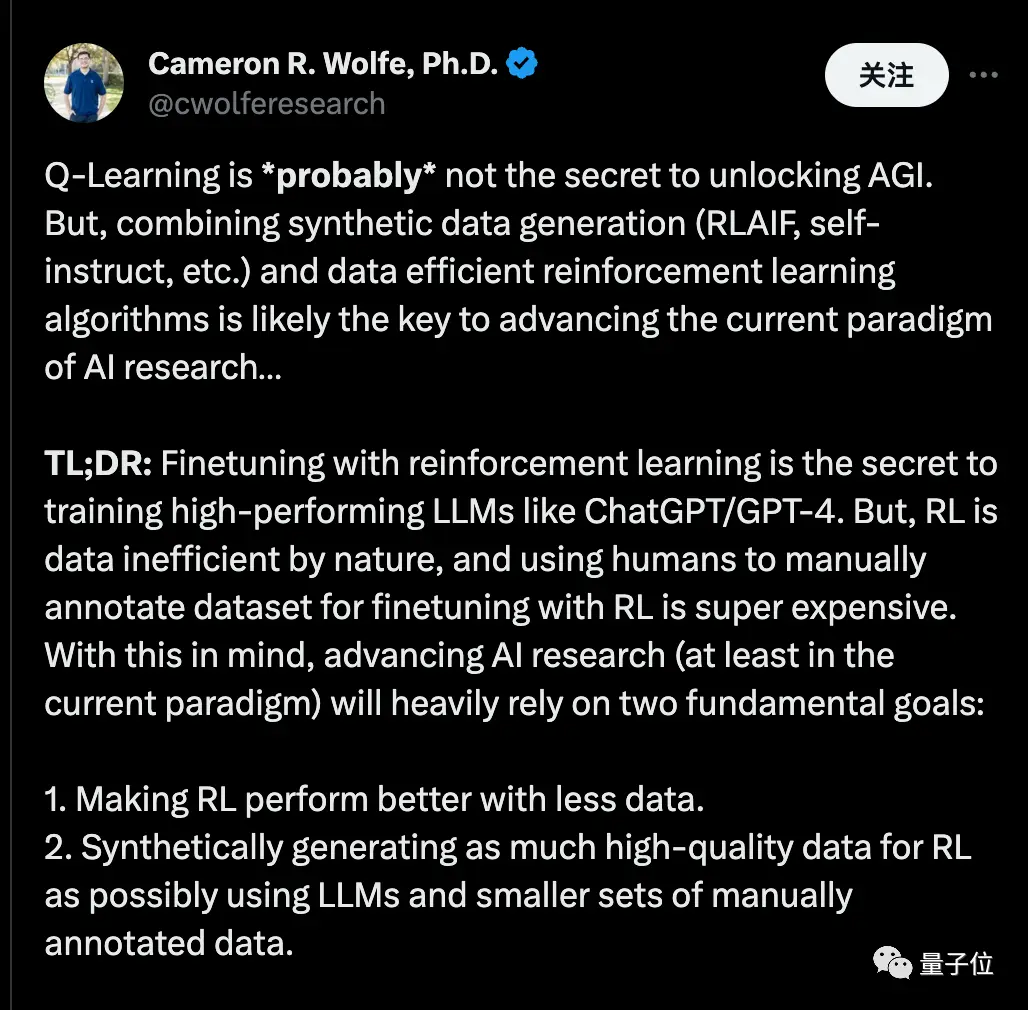
 萊斯大學博士Cameron R. Wolfe表示,Q-Learning可能並不是解鎖AGI的秘訣。
萊斯大學博士Cameron R. Wolfe表示,Q-Learning可能並不是解鎖AGI的秘訣。
但將「合成數據」與「數據高效的強化學習演算法」相結合,可能正是推進當前人工智慧研究範式的關鍵。
他表示,通過強化學習微調是訓練高性能大模型(如ChatGPT/GPT-4)的秘訣。 但強化學習本質上數據低效,使用人工手動標註數據集進行強化學習微調非常昂貴。 考慮到這一點,推進AI研究(至少在當前範式中)將嚴重依賴於兩個基本目標:
- 讓強化學習在更少數據下表現更好。
- 盡可能使用大模型和少量人工標註數據合成生成高質量數據。
… 如果我們堅持使用Decoder-only Transformer的預測下一個token範式(即預訓練 -> SFT -> RLHF)… 這兩種方法結合將使每個人都可以使用尖端的訓練技術,而不僅僅是擁有大量資金的研究團隊!
還有一件事
OpenAI內部目前還沒有人對Q*的消息發表回應。
但奧特曼剛剛透露與留在董事會的Quora創始人Adam D’Angelo進行了幾個小時的友好談話。
 看來無論Adam D’Angelo是否像大家猜測的那樣是這次事件的幕後黑手,現在都達成和解了。
看來無論Adam D’Angelo是否像大家猜測的那樣是這次事件的幕後黑手,現在都達成和解了。
參考連結:
[1]
[2]
[3]
[4]
[5]
[6]