Source: Wall Street Insights
On March 16, 2026, NVIDIA GTC 2026 officially opened, with Founder and CEO Jensen Huang delivering the keynote speech.
At this event, regarded as the “AI Industry’s Annual Pilgrimage,” Huang explained NVIDIA’s transformation from a “chip company” to an “AI infrastructure and factory company.” Confronted with market concerns about sustained performance and growth potential, Huang detailed the underlying business logic driving future expansion—“Token Factory Economics.”

Extremely Optimistic Performance Guidance: “At Least $1 Trillion in Demand by 2027”
Over the past two years, global AI computing demand has exploded exponentially. As large models evolve from “perception” and “generation” to “reasoning” and “action (task execution),” the consumption of computing power has surged sharply. Addressing market concerns about order and revenue ceilings, Huang provided very strong expectations.
In his speech, Huang stated plainly:
Around this time last year, I mentioned we saw a high-confidence demand of $500 billion, covering Blackwell and Rubin through 2026. Now, right here, right now, I see at least $1 trillion in demand by 2027.

Huang’s trillion-dollar forecast once boosted NVIDIA’s stock price by over 4.3%.
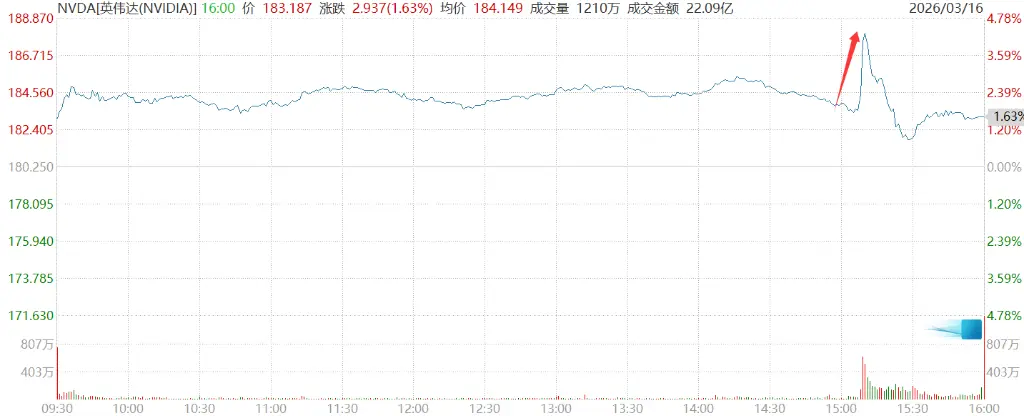
Moreover, he added further commentary on this figure:
Is this reasonable? That’s what I’m about to discuss. In fact, we might even be undersupplied. I am certain that actual computational demand will be much higher than this.
Huang pointed out that NVIDIA’s current systems have proven themselves as the world’s “lowest-cost infrastructure.” Because NVIDIA can run nearly all AI models across various domains, this versatility allows the $1 trillion investment from customers to be fully utilized and to maintain a long lifecycle.
Currently, 60% of NVIDIA’s business comes from the top five hyperscale cloud providers, while the remaining 40% is widely distributed across sovereign clouds, enterprises, industrial sectors, robotics, and edge computing.
Token Factory Economics: Power per Watt Determines Business Vitality
To justify the $1 trillion demand, Huang introduced a new business mindset to global CEOs. He emphasized that future data centers will no longer be mere file storage warehouses but “factories” producing Tokens (the fundamental units of AI output).

Huang stressed:
Every data center, every factory, by definition, is limited by power. A 1GW (gigawatt) factory will never become 2GW—this is a physical and atomic law. Under fixed power, whoever achieves the highest tokens per watt will have the lowest production cost.
Huang categorized future AI services into the following business tiers:
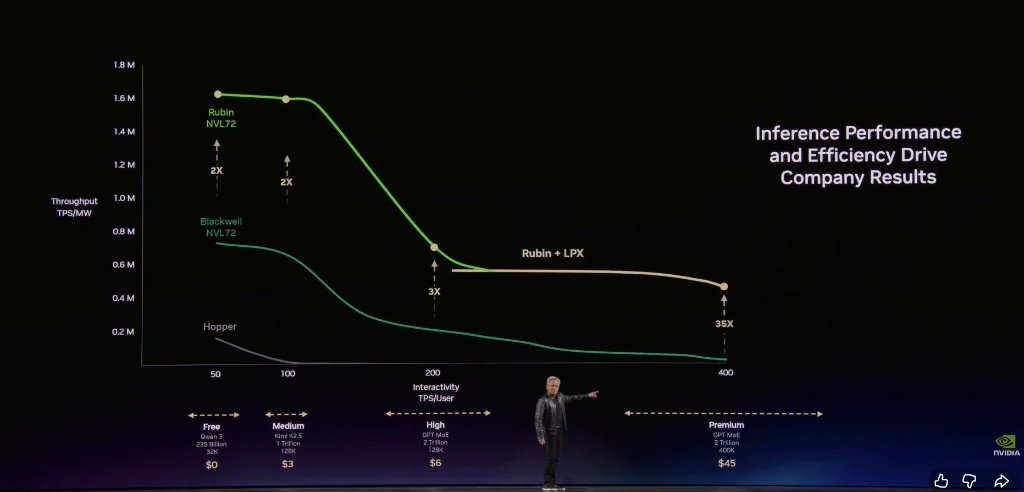
Free Tier (high throughput, low speed)
Intermediate Tier (~$3 per million tokens)
Advanced Tier (~$6 per million tokens)
High-Speed Tier (~$45 per million tokens)
Ultra-High-Speed Tier (~$150 per million tokens)
He noted that as models grow larger and context lengths extend, AI becomes smarter, but token generation rates slow down. Huang explained:
In this Token Factory, your throughput and token generation speed will directly translate into your precise revenue next year.
Huang emphasized that NVIDIA’s architecture enables customers to achieve extremely high throughput at the free tier, while at the highest inference tier, performance can be improved by an astonishing 35 times.
Vera Rubin Achieves 350x Acceleration in Two Years; Groq Fills the Speedy Inference Gap
Under physical limits, NVIDIA introduced its most complex AI computing system to date—Vera Rubin. Huang stated:
When I mentioned Hopper, I would hold up a chip—very cute. But when I mention Vera Rubin, everyone thinks of the entire system. In this fully liquid-cooled system, eliminating traditional cables, racks that once took two days to install now take only two hours.
Huang pointed out that through extreme end-to-end hardware-software co-design, Vera Rubin has achieved remarkable data leaps within the same 1GW data center:
In just two years, we increased token generation rate from 22 million to 700 million per second—a 350-fold increase. Moore’s Law during the same period only offers about 1.5 times improvement.
To address bandwidth bottlenecks under ultra-fast inference conditions (e.g., 1000 tokens/sec), NVIDIA unveiled its final solution integrating the acquired company Groq: asymmetric separation inference. Huang explained:
These two processors are fundamentally different. Groq chips have 500MB of SRAM, while a Rubin chip has 288GB of memory.

Huang noted that NVIDIA’s Dynamo software system delegates the massive compute and memory-intensive “Pre-fill” (preloading) phase to Vera Rubin, while the latency-sensitive “Decoding” phase is handled by Groq. He also offered enterprise compute configuration suggestions:
If your workload mainly involves high throughput, use 100% Vera Rubin; if you have substantial high-value token generation needs, allocate about 25% of your data center capacity to Groq.
It is revealed that Samsung-licensed Groq LP30 chips are in mass production, expected to ship in Q3, while the first Vera Rubin rack is already running on Microsoft Azure cloud.
Additionally, regarding optical interconnect technology, Huang showcased the world’s first mass-produced co-packaged optical (CPO) switch Spectrum X, calming market concerns over the “copper retreat, optical advance” route:
We need more copper cable capacity, more optical chip capacity, and more CPO capacity.
Agent Ends Traditional SaaS; “Annual Token Budget + Salary” Becomes Silicon Valley Standard
Beyond hardware barriers, Huang dedicated significant attention to the revolution in AI software and ecosystems, especially the explosion of Agents (intelligent entities).
He described the open-source project OpenClaw as “the most popular open-source project in human history,” surpassing what Linux achieved over 30 years in just a few weeks. Huang directly stated that OpenClaw is essentially the “operating system” for agent computers.
Huang asserted:
Every SaaS (Software as a Service) company will become an AaaS (Agent-as-a-Service) company. Undoubtedly, to securely deploy these agents capable of accessing sensitive data and executing code, NVIDIA has introduced the enterprise-grade NeMo Claw reference design, adding policy engines and privacy routers.
For ordinary professionals, this transformation is also imminent. Huang depicted the future workplace:
In the future, every engineer in our company will have an annual token budget. Their base annual salary might be hundreds of thousands of dollars, and I will allocate roughly half of that amount as token quota, enabling them to achieve 10x efficiency. This has become the new hiring leverage in Silicon Valley: how many tokens are in your offer?
He further predicted that each company will be both a token user (for engineers) and a token producer (serving clients). The significance of OpenClaw is comparable to HTML or Linux.
NVIDIA’s Open Model Initiative
Regarding custom agents, NVIDIA offers cutting-edge models:
Nemotron Large Language Model Cosmos World Foundation Model GROOT General Humanoid Robot Model BioNeMo Digital Biology Phys-AI Physics
In every domain, NVIDIA remains at the forefront, committed to continuous iteration—Nemotron 3 will be succeeded by Nemotron 4, Cosmos 1 by Cosmos 2, and Groq will also evolve to its second generation.
Nemotron 3 ranks among the top three global models in OpenClaw, at the forefront. Nemotron 3 Ultra will be the most powerful foundational model ever, supporting sovereign AI development across nations.
Today, NVIDIA announced the formation of the Nemotron Alliance, investing billions of dollars to advance AI foundational model R&D. Members include BlackForest Labs, Cursor, LangChain, Mistral, Perplexity, Reflection, Sarvam (India), Thinking Machines (Mira Murati’s lab), among others. Many enterprise software companies are joining, integrating NVIDIA’s intelligent agent AI tools and NeMo Claw reference design into their products.
Physical AI and Robotics
Digital agents act within the digital realm—coding, data analysis; while physical AI embodies intelligent agents—robots.
This GTC showcased 110 robots, nearly covering all global robot R&D firms. NVIDIA provides three computers (training, simulation, onboard) and a complete software stack with AI models.
In autonomous driving, the “ChatGPT moment” has arrived. Today, four new partners joined NVIDIA’s RoboTaxi Ready platform: BYD, Hyundai, Nissan, Geely, with an annual output of 18 million vehicles. Alongside previous partners Mercedes-Benz, Toyota, GM, the lineup is expanding. We also announced a major collaboration with Uber to deploy and connect RoboTaxi-ready vehicles in multiple cities.
In industrial robotics, companies like ABB, Universal Robotics, KUKA are collaborating with us to integrate physical AI models with simulation systems, advancing deployment on manufacturing lines worldwide.
In telecommunications, Caterpillar and T-Mobile are also involved. Future wireless base stations will evolve from mere communication nodes into NVIDIA Aerial AI RAN—an intelligent edge computing platform capable of real-time traffic sensing and beamforming adjustments for energy efficiency.
Special Segment: Olaf the Robot Debuts
(Play Disney Olaf robot demo video)
Huang: Snowman appears! Newton is running smoothly! Omniverse is working perfectly! Olaf, how are you?
Olaf: I’m so happy to see you.
Huang: Yes, because I gave you a computer—Jetson!
Olaf: What’s that?
Huang: Right inside your belly.
Olaf: That’s amazing.
Huang: You learned to walk in Omniverse.
Olaf: I like walking. It’s much better than riding a reindeer and gazing at the beautiful sky.
Huang: That’s thanks to physics simulation—based on NVIDIA Warp’s Newton solver, developed jointly with Disney and DeepMind, enabling you to adapt to the real physical world.
Olaf: I was just about to say that.
Huang: That’s your smartness. I am a snowman, not a snowball.
Huang: Can you imagine? The future Disney parks—where all these robot characters roam freely. Honestly, I thought you’d be taller. I’ve never seen such a short snowman.
Olaf: (noncommittal)
Huang: Come help me finish today’s speech, okay?
Olaf: Great!
Summary of the Keynote
Huang: Today, we discussed the following core themes:
- The arrival of reasoning inflection point: reasoning has become the most critical AI workload, tokens are the new commodity, and inference performance directly impacts revenue.
- The AI factory era: data centers have evolved from file storage to token factories; future companies will measure competitiveness by “AI factory efficiency.”
- The Agent revolution: OpenClaw has ushered in the era of intelligent agents—enterprise IT is transitioning from tools to agents, and every company needs an OpenClaw strategy.
- Physical AI and robotics: embodied intelligence is scaling, with autonomous driving, industrial robots, and humanoid robots forming the next major opportunity.
Thank you all, enjoy GTC!
