AI投資の主たるストーリーは構造的な移行を経験している。モルガン・スタンレーの最新調査は、AIが「コンテンツ生成」から「タスクの自動実行」へと進化するにつれ、次のAIインフラの増分論理は「単一チップの演算能力競争」から「フルスタックシステムエンジニアリング」へと拡大すると指摘している。GPUは依然としてコアだが、もはや予算やプレミアムを独占しない。追風取引台によると、モルガン・スタンレーのリサーチ部アナリストShawn Kimはレポートで直接次のように書いている。「エージェントAIは、計算からオーケストレーションへの構造的変化を示している。」エージェントのワークフローにおいて、CPU側のオーケストレーション時間は総遅延の50%から90%を占めることがあり、これにより2030年までにCPUの新たな市場規模は325億ドルから600億ドルに拡大し、サーバーCPUの総TAMは825億ドルから1100億ドルに押し上げられると推定されている。**同時に、DRAM、ABF基板、ウエハー受託製造、ストレージ、コネクタおよびパッシブ部品などのセクターは、「脇役」から新たなボトルネックと利益のプールへと飛躍する。**これにより、2030年には追加で15〜45EBのDRAM需要が生まれ、2027年の全産業年間供給の26%から77%に相当する規模となる。この判断は市場にとって次の意味を持つ:AIの資本支出の恩恵を受けるのは少数のチップ大手から、世界全体のサプライチェーン全体へと拡散し、次の超過収益は、最初にボトルネックとなり、かつ迅速な増産が最も難しい「エネーブルメント段階」のセクターからより多くもたらされる可能性が高い。ボトルネックが異なる段階へと移行するにつれ、AIバリューチェーンの重み付けも変化していく。「生成」から「行動」へ:エージェントはボトルネックを計算能力からオーケストレーションへと推移させる------------------------生成型AIの典型的なワークフローは比較的シンプルだ:ユーザーリクエストが到達すると、CPUが少量の前処理を行い、GPUがトークン生成を担当し、その後結果を返す。全体のリンクにおいて、GPUは絶対的な主役であり、CPUは補助的な役割にとどまる。一方、エージェントの動作ロジックは全く異なる。タスクを完了させるために、システムは計画、検索、外部ツールやAPIの呼び出し、実行、反省と反復など複数のステップを経る必要があり、多くの「コントロールプレーン」機能も関与する。モルガンの核心的結論は、エージェントがもたらすのは「より重い」単一推論ではなく、より多くのステップ、より多くの状態、より多くの調整であり、これらの作業は本質的にCPUの方が適しているということだ。これにより、二つの直接的な結果が生じる:一つは、クラスター全体でのCPUとGPUの比率が体系的に上昇すること。もう一つは、DRAMが「容量の設定項目」から「性能とスループットの中核システムコンポーネント」へと格上げされることだ。データセンターのボトルネックは、ますますメモリ帯域幅、データの搬送、相互接続の遅延、システムレベルの調整に集中し、単なるGPUの演算能力だけではなくなる。CPU比率の再評価:"1:12"から"1:2"へ、さらには逆転へ----------------------------過去には、「1つのCPUが約12個のGPUをサポートする」というのがAIサーバーの典型的なアーキテクチャだった。しかし、レポートは、エージェントワークフローの長期化、ツール呼び出しやコンテキスト管理の複雑化に伴い、この比率が急速に縮小していると指摘している。NVIDIAのロードマップを例にとると、最新の推定では、Rubinプラットフォーム付近でCPUとGPUの比率はすでに1:2に近づいている。もしRubin Ultraなどのよりアグレッシブな進化形態に進むと、2つのCPUに対して1つのGPUの逆転構成もあり得る。単に1:12から1:8に改善しただけでも、**超大規模展開においては、CPUの絶対的な需要量は大きく跳ね上がる。**この方向性が成立すれば、CPUの需要弾力性は「サーバー出荷に追随する」から「エージェントの複雑さに追随する」へと変化し、CPU需要の成長はより構造的なものとなり、従来のハードウェアの更新周期の延長だけではなくなる。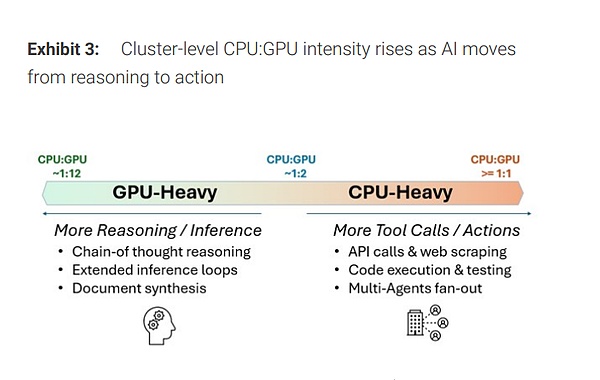CPU TAMの再計算:2030年825億〜1100億ドル、増分はオーケストレーションから----------------------------------モルガン・スタンレーは、「システム層別化」アプローチを採用し、エージェントによるCPUの機会を従来のサーバーの更新サイクルから切り離し、三つの独立した分析枠組みを構築している。> * **ヘッドノードCPU**> > GPUシステムに近いラック制御層に対応し、2030年までに世界で約500万個のAIアクセラレータ、各アクセラレータに2つの高性能CPU、平均販売価格約5000ドルと仮定すると、約500億ドルのTAMに相当。> > * **オーケストレーションCPU**> > エージェントのオーケストレーションに新たに必要となる部分をカバーし、計画・スケジューリング、ツールチェーン、RAGパイプライン、KVキャッシュやベクトルライブラリに関わるメモリサービス、戦略や可観測性などを含む。追加で1000万〜1500万個のCPU、ASP約3000ドルと仮定し、300億〜450億ドルのTAMに。> > * **その他のCPU**> > ストレージノードや一部ネットワークノードなどを含み、約25億〜150億ドルに相当。> > * 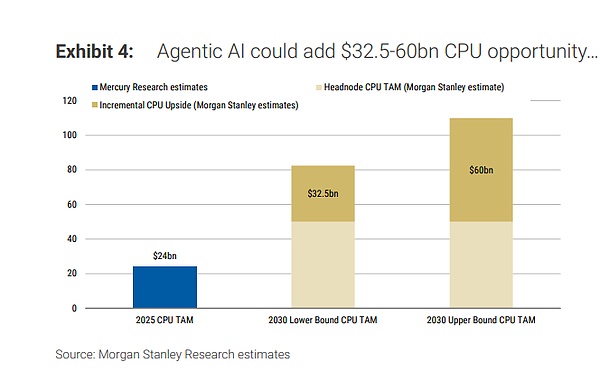これら三つを合計すると、2030年のサーバーCPUの総TAMは約825億〜1100億ドルとなり、そのうちエージェントによる増分は約325億〜600億ドル。全体の見積もりの基準は、2030年の世界のAIデータセンターインフラ販売額が約1.2兆ドルと見積もる(2025年は約2420億ドル)という判断に基づいている。レポートはまた、「上方修正スイッチ」を示しており、NVIDIAの見解によると、2030年のAIインフラ販売額が3兆ドルや5兆ドルに達した場合、CPUのTAM範囲は全体的に2060億〜2750億ドル、あるいは3440億〜4580億ドルに引き上げられる可能性がある。**これはあくまで予測の一つだが、「AI工場」の規模拡大がCPU需要をシステム的に拡大させることを示唆している。**メモリが脇役から主役へ:2030年に追加されるDRAM需要は15〜45EB-----------------------------エージェントの真の差別化は、推論能力だけでなく、「持続可能なコンテキストと記憶」にもある。継続的なコンテキスト、KVキャッシュ、中間状態のツール呼び出し、並列エージェントのワークセットは、CPU側のDRAMにとってはHBMの機能的な延長線上にある。計算モデルはシンプルで明快だ:追加されるDRAM需要は、新たにオーケストレーション用CPUの数に、1CPUあたりの平均DRAM構成を掛けたものに等しい。二つの仮定は、追加の1000万個のオーケストレーションCPUと、各CPUに約1.5TBのDRAMを搭載、または楽観的に1500万個のCPUと各3TBとする。これにより、2030年にエージェントがもたらす追加のDRAM需要は15〜45EBに達し、2027年のDRAM産業の年間供給の26%〜77%に相当する。周期的な見通しとして、レポートはまた、市場構造の変数も指摘している。多くのメモリサプライヤーが大口顧客と3〜5年の長期契約(LTA)を交渉しており、これが価格下落のペースを緩め、2027年前の収益見通しを高める可能性がある。「メモリ層がAIシステムのコアな収益化経路になりつつある」—ホスト側のDRAM、メモリインターフェースチップ、CXL拡張、SSD/HDD階層ストレージも、より持続可能な価値の受け皿となる。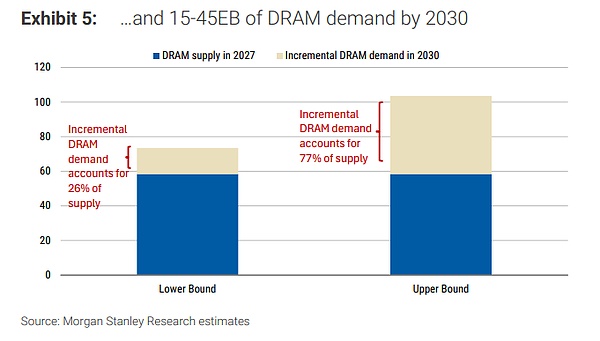供給が逼迫するセクターほど価格決定権を持つ:ABF基板、受託製造、エネーブルメントコンポーネント--------------------------真に超過収益の潜在性を持つのは、「生産能力の拡大が遅く、検証サイクルが長い」エネーブルメント段階のセクターだ。レポートは以下のサプライチェーンを特定している。**ABF基板:**このAI駆動のABF上昇サイクルは今後十年末まで続く可能性があり、2026〜2027年頃に供給不足のリスクが存在する。単に「CPU TAMの拡大」だけでも、2030年のABF需要を5%〜10%上方修正できる。サーバー用CPUのABF基板市場は2030年に約47億ドルに達し、CPUによる増分需要は約12億ドルと見積もられる。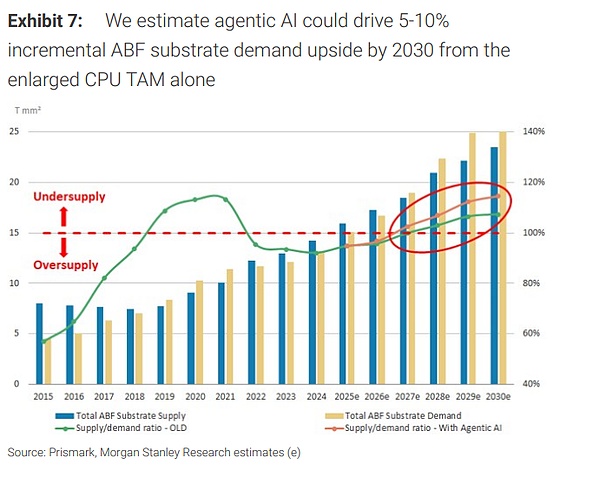**ウエハー受託製造(特に先進プロセス):**CPUの受託製造市場は2026年に約330億ドル、2028年には約370億ドルに拡大。TSMCは、CPUの受託製造におけるシェアを2026年の約70%から2028年には約75%に引き上げる見込み。さらに、Intelは2027年後半からサーバー用CPUの外部委託をTSMCに開始する可能性がある。**BMCとメモリインターフェース:**AspeedはCPUサーバーのBMCの主要な恩恵を受けると強調されており、市場シェアは約70%。新世代のAST2700プラットフォームはASPを40%〜50%引き上げる余地がある。Montageは「メモリインターコネクト」バリューチェーンに位置し、世界の収益シェアは約36.8%。**CPUソケットとパッシブ部品:**レポートはLotesとFITをCPUソケットの直接的なマッピングとし、100万個のCPU需要増加ごとにLotesの収益は約0.6%、FITは約0.2%増加と推定(ソケット口径のみ計算)。パッシブ部品については、「1台の汎用サーバーあたり約30ドルのMLCC内容量」を簡略化仮定とし、2030年に追加の5億ドルのMLCC需要増を見積もる。これは当時のグローバルMLCC市場の約2%〜3%に相当。CPUは最も明確な増分だが、「エネーブルメント段階」の方がより好まれる---------------------レポートは、エージェントのワークロード増加がAMDのクラウドシェアに構造的な追い風をもたらすことを認めつつも、AMDとIntelの両者に対しては「イコールウェイト」の評価を維持し、NVIDIAやBroadcomなど、「資本支出とトークン成長がより直接的に収益に反映される」銘柄を通じてエージェントテーマを追跡することを推奨している。同時に、評価の制約も重要な考慮点として挙げている。よりマクロな枠組みから見ると、このレポートの核心的価値は、AI投資のパラダイムを「ポイントの演算能力競争」から「システムの効率とボトルネックの経済学」へとアップグレードしている点にある:**GPUはエンジン、CPUはトランスミッションとコントロールシステム、メモリとインターコネクトは油路とシャーシ——単点の極致も重要だが、規模の経済を決定するのは車全体の協調性だ。**産業チェーンにとって、これはAI投資の超過収益源がより分散し、長期化することを意味する。単に「最強GPU」からだけではなく、エージェントのワークフローにおいて最初にボトルネックとなり、かつ迅速な増産が最も難しい段階のセクターからもたらされる。継続的に追跡できる高頻度の指標には、新プラットフォームのBOMにおけるCPU数とメモリ構成の上方修正幅、クラウド事業者の長期契約締結ペース、ABF基板と先進プロセスの生産能力の稼働率の動向などが含まれる。
インテリジェントエージェントの台頭後、
AI全体の価値チェーンの分布が変わった。
AI投資の主たるストーリーは構造的な移行を経験している。モルガン・スタンレーの最新調査は、AIが「コンテンツ生成」から「タスクの自動実行」へと進化するにつれ、次のAIインフラの増分論理は「単一チップの演算能力競争」から「フルスタックシステムエンジニアリング」へと拡大すると指摘している。GPUは依然としてコアだが、もはや予算やプレミアムを独占しない。
追風取引台によると、モルガン・スタンレーのリサーチ部アナリストShawn Kimはレポートで直接次のように書いている。「エージェントAIは、計算からオーケストレーションへの構造的変化を示している。」エージェントのワークフローにおいて、CPU側のオーケストレーション時間は総遅延の50%から90%を占めることがあり、これにより2030年までにCPUの新たな市場規模は325億ドルから600億ドルに拡大し、サーバーCPUの総TAMは825億ドルから1100億ドルに押し上げられると推定されている。
**同時に、DRAM、ABF基板、ウエハー受託製造、ストレージ、コネクタおよびパッシブ部品などのセクターは、「脇役」から新たなボトルネックと利益のプールへと飛躍する。**これにより、2030年には追加で15〜45EBのDRAM需要が生まれ、2027年の全産業年間供給の26%から77%に相当する規模となる。
この判断は市場にとって次の意味を持つ:AIの資本支出の恩恵を受けるのは少数のチップ大手から、世界全体のサプライチェーン全体へと拡散し、次の超過収益は、最初にボトルネックとなり、かつ迅速な増産が最も難しい「エネーブルメント段階」のセクターからより多くもたらされる可能性が高い。ボトルネックが異なる段階へと移行するにつれ、AIバリューチェーンの重み付けも変化していく。
「生成」から「行動」へ:エージェントはボトルネックを計算能力からオーケストレーションへと推移させる
生成型AIの典型的なワークフローは比較的シンプルだ:ユーザーリクエストが到達すると、CPUが少量の前処理を行い、GPUがトークン生成を担当し、その後結果を返す。全体のリンクにおいて、GPUは絶対的な主役であり、CPUは補助的な役割にとどまる。
一方、エージェントの動作ロジックは全く異なる。タスクを完了させるために、システムは計画、検索、外部ツールやAPIの呼び出し、実行、反省と反復など複数のステップを経る必要があり、多くの「コントロールプレーン」機能も関与する。モルガンの核心的結論は、エージェントがもたらすのは「より重い」単一推論ではなく、より多くのステップ、より多くの状態、より多くの調整であり、これらの作業は本質的にCPUの方が適しているということだ。
これにより、二つの直接的な結果が生じる:一つは、クラスター全体でのCPUとGPUの比率が体系的に上昇すること。もう一つは、DRAMが「容量の設定項目」から「性能とスループットの中核システムコンポーネント」へと格上げされることだ。データセンターのボトルネックは、ますますメモリ帯域幅、データの搬送、相互接続の遅延、システムレベルの調整に集中し、単なるGPUの演算能力だけではなくなる。
CPU比率の再評価:"1:12"から"1:2"へ、さらには逆転へ
過去には、「1つのCPUが約12個のGPUをサポートする」というのがAIサーバーの典型的なアーキテクチャだった。しかし、レポートは、エージェントワークフローの長期化、ツール呼び出しやコンテキスト管理の複雑化に伴い、この比率が急速に縮小していると指摘している。
NVIDIAのロードマップを例にとると、最新の推定では、Rubinプラットフォーム付近でCPUとGPUの比率はすでに1:2に近づいている。もしRubin Ultraなどのよりアグレッシブな進化形態に進むと、2つのCPUに対して1つのGPUの逆転構成もあり得る。単に1:12から1:8に改善しただけでも、超大規模展開においては、CPUの絶対的な需要量は大きく跳ね上がる。
この方向性が成立すれば、CPUの需要弾力性は「サーバー出荷に追随する」から「エージェントの複雑さに追随する」へと変化し、CPU需要の成長はより構造的なものとなり、従来のハードウェアの更新周期の延長だけではなくなる。
CPU TAMの再計算:2030年825億〜1100億ドル、増分はオーケストレーションから
モルガン・スタンレーは、「システム層別化」アプローチを採用し、エージェントによるCPUの機会を従来のサーバーの更新サイクルから切り離し、三つの独立した分析枠組みを構築している。
これら三つを合計すると、2030年のサーバーCPUの総TAMは約825億〜1100億ドルとなり、そのうちエージェントによる増分は約325億〜600億ドル。全体の見積もりの基準は、2030年の世界のAIデータセンターインフラ販売額が約1.2兆ドルと見積もる(2025年は約2420億ドル)という判断に基づいている。
レポートはまた、「上方修正スイッチ」を示しており、NVIDIAの見解によると、2030年のAIインフラ販売額が3兆ドルや5兆ドルに達した場合、CPUのTAM範囲は全体的に2060億〜2750億ドル、あるいは3440億〜4580億ドルに引き上げられる可能性がある。これはあくまで予測の一つだが、「AI工場」の規模拡大がCPU需要をシステム的に拡大させることを示唆している。
メモリが脇役から主役へ:2030年に追加されるDRAM需要は15〜45EB
エージェントの真の差別化は、推論能力だけでなく、「持続可能なコンテキストと記憶」にもある。継続的なコンテキスト、KVキャッシュ、中間状態のツール呼び出し、並列エージェントのワークセットは、CPU側のDRAMにとってはHBMの機能的な延長線上にある。
計算モデルはシンプルで明快だ:追加されるDRAM需要は、新たにオーケストレーション用CPUの数に、1CPUあたりの平均DRAM構成を掛けたものに等しい。二つの仮定は、追加の1000万個のオーケストレーションCPUと、各CPUに約1.5TBのDRAMを搭載、または楽観的に1500万個のCPUと各3TBとする。これにより、2030年にエージェントがもたらす追加のDRAM需要は15〜45EBに達し、2027年のDRAM産業の年間供給の26%〜77%に相当する。
周期的な見通しとして、レポートはまた、市場構造の変数も指摘している。多くのメモリサプライヤーが大口顧客と3〜5年の長期契約(LTA)を交渉しており、これが価格下落のペースを緩め、2027年前の収益見通しを高める可能性がある。「メモリ層がAIシステムのコアな収益化経路になりつつある」—ホスト側のDRAM、メモリインターフェースチップ、CXL拡張、SSD/HDD階層ストレージも、より持続可能な価値の受け皿となる。
供給が逼迫するセクターほど価格決定権を持つ:ABF基板、受託製造、エネーブルメントコンポーネント
真に超過収益の潜在性を持つのは、「生産能力の拡大が遅く、検証サイクルが長い」エネーブルメント段階のセクターだ。レポートは以下のサプライチェーンを特定している。
**ABF基板:**このAI駆動のABF上昇サイクルは今後十年末まで続く可能性があり、2026〜2027年頃に供給不足のリスクが存在する。単に「CPU TAMの拡大」だけでも、2030年のABF需要を5%〜10%上方修正できる。サーバー用CPUのABF基板市場は2030年に約47億ドルに達し、CPUによる増分需要は約12億ドルと見積もられる。
**ウエハー受託製造(特に先進プロセス):**CPUの受託製造市場は2026年に約330億ドル、2028年には約370億ドルに拡大。TSMCは、CPUの受託製造におけるシェアを2026年の約70%から2028年には約75%に引き上げる見込み。さらに、Intelは2027年後半からサーバー用CPUの外部委託をTSMCに開始する可能性がある。
**BMCとメモリインターフェース:**AspeedはCPUサーバーのBMCの主要な恩恵を受けると強調されており、市場シェアは約70%。新世代のAST2700プラットフォームはASPを40%〜50%引き上げる余地がある。Montageは「メモリインターコネクト」バリューチェーンに位置し、世界の収益シェアは約36.8%。
**CPUソケットとパッシブ部品:**レポートはLotesとFITをCPUソケットの直接的なマッピングとし、100万個のCPU需要増加ごとにLotesの収益は約0.6%、FITは約0.2%増加と推定(ソケット口径のみ計算)。パッシブ部品については、「1台の汎用サーバーあたり約30ドルのMLCC内容量」を簡略化仮定とし、2030年に追加の5億ドルのMLCC需要増を見積もる。これは当時のグローバルMLCC市場の約2%〜3%に相当。
CPUは最も明確な増分だが、「エネーブルメント段階」の方がより好まれる
レポートは、エージェントのワークロード増加がAMDのクラウドシェアに構造的な追い風をもたらすことを認めつつも、AMDとIntelの両者に対しては「イコールウェイト」の評価を維持し、NVIDIAやBroadcomなど、「資本支出とトークン成長がより直接的に収益に反映される」銘柄を通じてエージェントテーマを追跡することを推奨している。同時に、評価の制約も重要な考慮点として挙げている。
よりマクロな枠組みから見ると、このレポートの核心的価値は、AI投資のパラダイムを「ポイントの演算能力競争」から「システムの効率とボトルネックの経済学」へとアップグレードしている点にある:GPUはエンジン、CPUはトランスミッションとコントロールシステム、メモリとインターコネクトは油路とシャーシ——単点の極致も重要だが、規模の経済を決定するのは車全体の協調性だ。
産業チェーンにとって、これはAI投資の超過収益源がより分散し、長期化することを意味する。単に「最強GPU」からだけではなく、エージェントのワークフローにおいて最初にボトルネックとなり、かつ迅速な増産が最も難しい段階のセクターからもたらされる。継続的に追跡できる高頻度の指標には、新プラットフォームのBOMにおけるCPU数とメモリ構成の上方修正幅、クラウド事業者の長期契約締結ペース、ABF基板と先進プロセスの生産能力の稼働率の動向などが含まれる。