最近、オープンソースのAIインテリジェントエージェントフレームワークであるOpenClawの継続的な盛り上がりに伴い、重要な問題が浮上してきた。それは、果たしてどの大規模言語モデルが「ロブスター」を駆動する最強の「脳」なのかということである。この課題に対して、Kilo AIチームが作成したPinchBenchランキングは、その創始者の推薦もあり、非常に注目を集めている。このランキングは、成功率、速度、価格の三つの観点から、世界中の主流モデルのOpenClaw適合度をリアルタイムで評価している。この最新の順位は、単なる性能テストにとどまらず、AIインテリジェントエージェントが「使える」から「使いやすい」へと進化する過程における構造的変化を映し出している。## モデル適合の評価基準に何が起きているのか?従来のモデル評価は、知識質問応答や論理推論能力に焦点を当ててきたが、PinchBenchの登場は評価基準の根本的な転換を示している。現在の核心的な変化は、評価の焦点が、実世界のワークフローを模擬し、実行できる能力、すなわち「エージェント能力テスト」へと移行していることである。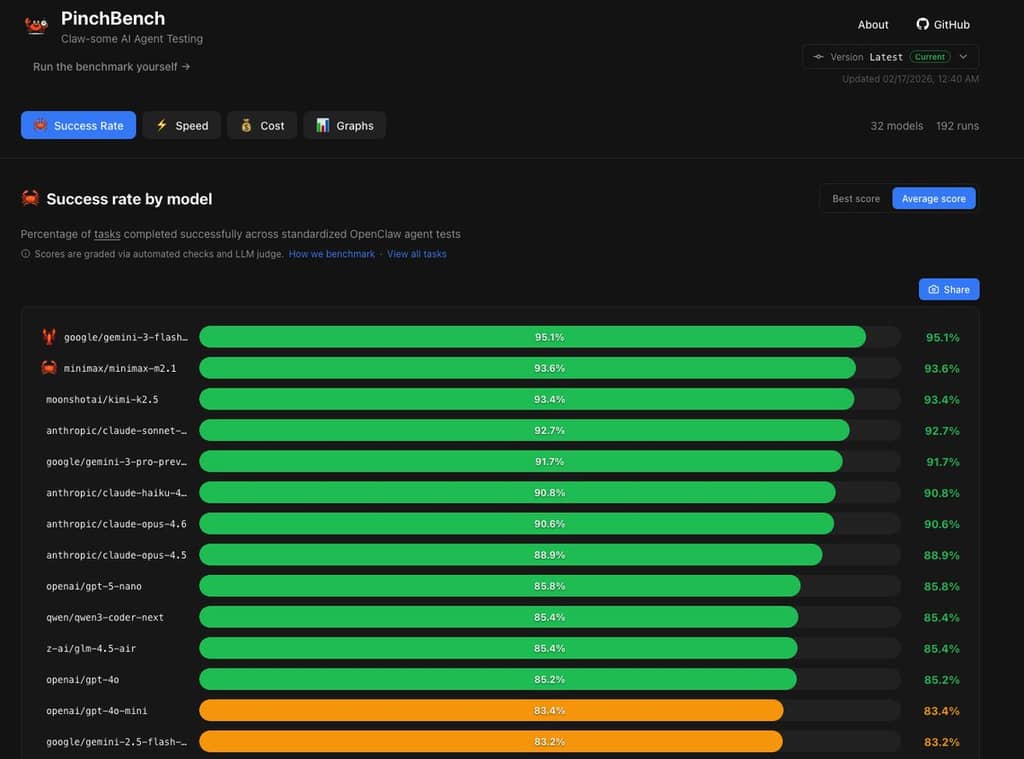2026年3月9日までの最新データによると、タスク成功率の観点では、GoogleのGemini 3 Flashが95.1%でトップに立ち、国産モデルも好調で、MiniMax M2.1とKimi K2.5がそれぞれ93.6%、93.4%の成功率で続いている。この順位変動は、業界の関心が単なる理解能力から、複雑な環境でツールを呼び出し、多段階の操作を完遂するエンジニアリング能力へとシフトしていることを示している。## 異なるモデルのパフォーマンス差を生むメカニズムは何か?適合率の差を生む根本的なメカニズムは、「ツール呼び出し」や「ワークフロー計画」をネイティブにサポートするモデルの能力にある。OpenClawは、ハートビートメカニズムを利用してエージェントが環境を自主的にスキャンし、タスクを実行する仕組みだ。これには、基盤となるモデルが高信頼性の関数呼び出し能力と構造化された出力能力を備えている必要がある。例えば、MiniMax M2.5が速度ランキングでトップに立ったのは、推論効率に関するアーキテクチャ面での最適化により、エンドツーエンドのタスク実行時間を大幅に短縮したことによる。一方、汎用能力の高いモデルの適合率が低いのは、エージェントに必要なリアルタイムAPI呼び出しや多段階計画に特化した最適化を行っていないことに起因している。## 高い適合率の背後にある構造的コストは何か?極限まで適合率と速度を追求すると、もう一つの次元で犠牲を払う必要がある。それは、経済コストだ。データによると、成功率トップのGemini 3 Flashとコストパフォーマンス重視のモデルとの間には大きな価格差が存在する。現在、軽量シナリオ向けのGPT-5-nanoは、1百万トークンあたり0.05ドルと低価格だが、国内モデルのMiniMax M2.1は、そのコストが前者の約3倍に相当する。このことは、構造的なトレードオフを示している。最高のタスク完遂率を追求する開発者は、より高い推論コストを受け入れる必要があり、逆に予算を抑えたい場合は、成功率や速度を犠牲にしなければならない。この「性能とコスト」のバランスは、エージェントの規模拡大に伴う導入障壁となっている。## この適合パターンはWeb3や暗号業界に何をもたらすのか?暗号業界にとって、高適合率モデルの登場は、「AIインテリジェントエージェント経済」の実現を加速させている。OpenClawの設計思想は、暗号の精神と高度に一致している。すなわち、ユーザーが自らエージェントを所有し、許可不要でリソースを呼び出せる仕組みだ。現在、x402決済プロトコルやERC-8004アイデンティティ標準と連携し、高適合率のエージェントは、自律的な支払い、相互雇用、チェーン上の信用構築を実現できる。これにより、MiniMaxやKimiといったモデルがPinchBench上でタスク実行能力を証明すれば、開発者はこれらの「脳」を基盤に、DeFiやデータマーケットにおいて独立して動作するオンチェーン経済主体を構築できる。適合率の高さは、これら暗号インテリジェントエージェントの「生産性」を直接左右する。## 今後のモデル適合率の進化はどこに向かうのか?未来を見据えると、モデル適合率の競争は、単なる「タスク完遂率」だけにとどまらず、多様化・動的な方向へと進化するだろう。一つは、ランキング自体がリアルタイムで更新され続けるため、モデルのバージョンアップに伴い順位が頻繁に変動し、追い越しの余地が残されていることだ。もう一つは、オープンソースコミュニティのPinchBenchツールの普及により、開発者は特定の垂直シナリオ(例:データ分析、コンテンツ制作)向けにカスタムテストセットを作成できることだ。推測されるのは、将来的には「適合率」が高度に分化し、汎用的な万能モデルは存在せず、各々が特定のスキルツリーに特化した「エキスパートモデル」が台頭することだ。## 現在のランキングのリスクと制約は何か?現行の適合率ランキングを参考にする際には、複数のリスクに注意が必要だ。第一に、技術的な側面では、プロンプトインジェクション攻撃が依然として安全上の盲点であり、高成功率のモデルでも、経済シナリオにおいて悪意のある指示に操られ、資産損失を招く可能性がある。第二に、評価タスクの制約も無視できない。PinchBenchは現在、約23の実際のタスクを含むが、すべての長尾(ロングテール)アプリケーションを網羅しているわけではない。第三に、速度と成功率の両方が高いことは、過学習のリスクも潜んでいる。特定のテストセットで高いパフォーマンスを示す一方で、実環境では汎化能力が不足している可能性がある。最後に、安全性のリスクも客観的に存在し、工信部門はOpenClawの不適切な設定により高いセキュリティリスクがあることを指摘している。これらは、モデルの実用性を評価する際に考慮すべき重要なポイントだ。## まとめPinchBenchが公開したOpenClawモデル適合率ランキングは、単なる現状の成績表にとどまらず、AIインテリジェントエージェント産業の動向を示す風向計である。それは、GeminiからMiniMax、Kimiといった国内外のモデルが、実タスクの実行能力においてどのように階層化されているかを明確に示すとともに、高性能の裏に高コストが伴う現実も露呈している。暗号業界にとって、このランキングは、自律的なインテリジェントエージェント経済が概念から実践へと進展しつつあることを示唆している。モデルのタスク完遂効率は、チェーン上のビジネスのスピードを左右する。こうしたトレンドを受け入れる一方で、開発者は性能、コスト、安全の微妙なバランスを冷静に見極める必要がある。
PinchBench ランキング発表:OpenClaw モデル適合率ランキングが示すAIインテリジェントの新たな局面
最近、オープンソースのAIインテリジェントエージェントフレームワークであるOpenClawの継続的な盛り上がりに伴い、重要な問題が浮上してきた。それは、果たしてどの大規模言語モデルが「ロブスター」を駆動する最強の「脳」なのかということである。この課題に対して、Kilo AIチームが作成したPinchBenchランキングは、その創始者の推薦もあり、非常に注目を集めている。このランキングは、成功率、速度、価格の三つの観点から、世界中の主流モデルのOpenClaw適合度をリアルタイムで評価している。この最新の順位は、単なる性能テストにとどまらず、AIインテリジェントエージェントが「使える」から「使いやすい」へと進化する過程における構造的変化を映し出している。
モデル適合の評価基準に何が起きているのか?
従来のモデル評価は、知識質問応答や論理推論能力に焦点を当ててきたが、PinchBenchの登場は評価基準の根本的な転換を示している。現在の核心的な変化は、評価の焦点が、実世界のワークフローを模擬し、実行できる能力、すなわち「エージェント能力テスト」へと移行していることである。
2026年3月9日までの最新データによると、タスク成功率の観点では、GoogleのGemini 3 Flashが95.1%でトップに立ち、国産モデルも好調で、MiniMax M2.1とKimi K2.5がそれぞれ93.6%、93.4%の成功率で続いている。この順位変動は、業界の関心が単なる理解能力から、複雑な環境でツールを呼び出し、多段階の操作を完遂するエンジニアリング能力へとシフトしていることを示している。
異なるモデルのパフォーマンス差を生むメカニズムは何か?
適合率の差を生む根本的なメカニズムは、「ツール呼び出し」や「ワークフロー計画」をネイティブにサポートするモデルの能力にある。OpenClawは、ハートビートメカニズムを利用してエージェントが環境を自主的にスキャンし、タスクを実行する仕組みだ。これには、基盤となるモデルが高信頼性の関数呼び出し能力と構造化された出力能力を備えている必要がある。例えば、MiniMax M2.5が速度ランキングでトップに立ったのは、推論効率に関するアーキテクチャ面での最適化により、エンドツーエンドのタスク実行時間を大幅に短縮したことによる。一方、汎用能力の高いモデルの適合率が低いのは、エージェントに必要なリアルタイムAPI呼び出しや多段階計画に特化した最適化を行っていないことに起因している。
高い適合率の背後にある構造的コストは何か?
極限まで適合率と速度を追求すると、もう一つの次元で犠牲を払う必要がある。それは、経済コストだ。データによると、成功率トップのGemini 3 Flashとコストパフォーマンス重視のモデルとの間には大きな価格差が存在する。現在、軽量シナリオ向けのGPT-5-nanoは、1百万トークンあたり0.05ドルと低価格だが、国内モデルのMiniMax M2.1は、そのコストが前者の約3倍に相当する。このことは、構造的なトレードオフを示している。最高のタスク完遂率を追求する開発者は、より高い推論コストを受け入れる必要があり、逆に予算を抑えたい場合は、成功率や速度を犠牲にしなければならない。この「性能とコスト」のバランスは、エージェントの規模拡大に伴う導入障壁となっている。
この適合パターンはWeb3や暗号業界に何をもたらすのか?
暗号業界にとって、高適合率モデルの登場は、「AIインテリジェントエージェント経済」の実現を加速させている。OpenClawの設計思想は、暗号の精神と高度に一致している。すなわち、ユーザーが自らエージェントを所有し、許可不要でリソースを呼び出せる仕組みだ。現在、x402決済プロトコルやERC-8004アイデンティティ標準と連携し、高適合率のエージェントは、自律的な支払い、相互雇用、チェーン上の信用構築を実現できる。これにより、MiniMaxやKimiといったモデルがPinchBench上でタスク実行能力を証明すれば、開発者はこれらの「脳」を基盤に、DeFiやデータマーケットにおいて独立して動作するオンチェーン経済主体を構築できる。適合率の高さは、これら暗号インテリジェントエージェントの「生産性」を直接左右する。
今後のモデル適合率の進化はどこに向かうのか?
未来を見据えると、モデル適合率の競争は、単なる「タスク完遂率」だけにとどまらず、多様化・動的な方向へと進化するだろう。一つは、ランキング自体がリアルタイムで更新され続けるため、モデルのバージョンアップに伴い順位が頻繁に変動し、追い越しの余地が残されていることだ。もう一つは、オープンソースコミュニティのPinchBenchツールの普及により、開発者は特定の垂直シナリオ(例:データ分析、コンテンツ制作)向けにカスタムテストセットを作成できることだ。推測されるのは、将来的には「適合率」が高度に分化し、汎用的な万能モデルは存在せず、各々が特定のスキルツリーに特化した「エキスパートモデル」が台頭することだ。
現在のランキングのリスクと制約は何か?
現行の適合率ランキングを参考にする際には、複数のリスクに注意が必要だ。第一に、技術的な側面では、プロンプトインジェクション攻撃が依然として安全上の盲点であり、高成功率のモデルでも、経済シナリオにおいて悪意のある指示に操られ、資産損失を招く可能性がある。第二に、評価タスクの制約も無視できない。PinchBenchは現在、約23の実際のタスクを含むが、すべての長尾(ロングテール)アプリケーションを網羅しているわけではない。第三に、速度と成功率の両方が高いことは、過学習のリスクも潜んでいる。特定のテストセットで高いパフォーマンスを示す一方で、実環境では汎化能力が不足している可能性がある。最後に、安全性のリスクも客観的に存在し、工信部門はOpenClawの不適切な設定により高いセキュリティリスクがあることを指摘している。これらは、モデルの実用性を評価する際に考慮すべき重要なポイントだ。
まとめ
PinchBenchが公開したOpenClawモデル適合率ランキングは、単なる現状の成績表にとどまらず、AIインテリジェントエージェント産業の動向を示す風向計である。それは、GeminiからMiniMax、Kimiといった国内外のモデルが、実タスクの実行能力においてどのように階層化されているかを明確に示すとともに、高性能の裏に高コストが伴う現実も露呈している。暗号業界にとって、このランキングは、自律的なインテリジェントエージェント経済が概念から実践へと進展しつつあることを示唆している。モデルのタスク完遂効率は、チェーン上のビジネスのスピードを左右する。こうしたトレンドを受け入れる一方で、開発者は性能、コスト、安全の微妙なバランスを冷静に見極める必要がある。