OpenAIの謎の新モデルQ*が暴露され、取締役会が警戒するほど強力で、ウルトラマン追放の導火線もなかった
巴比特_
記事のソース: 量子ビット
 画像出典:Unbounded AIによって生成
画像出典:Unbounded AIによって生成
OpenAIの宮廷ファイトドラマが終わったばかりで、すぐに別の騒動を引き起こします!
ロイターは、アルトマンが解雇される前に、何人かの研究者が取締役会に警告書を書いていたことを明らかにし、それが事件全体の引き金になった可能性があると報じた。
社内でQ(Q-Starと発音)と名付けられた次世代AIモデルは、人類を脅かすにはあまりにも強力で高度です。
Q*を率いるのは、この嵐の中心人物であるチーフサイエンティストのイリヤ・スツケヴァーです。
人々はすぐに、APECサミットでのアルトマンの以前の発言を結びつけた。
OpenAIの歴史の中で4回ありましたが、最近ではここ数週間、私がこの部屋にいて、無知のベールを押し破り、発見のフロンティアに到達したとき、それは私のキャリアの中で最高の栄誉でした。 "
 Q*には、汎用人工知能や超知能への道のりの重要なステップと見なされる、次のようなコア特性があるかもしれません。
Q*には、汎用人工知能や超知能への道のりの重要なステップと見なされる、次のようなコア特性があるかもしれません。
・ヒトデータの限界を突破し、膨大な量の学習データを自分で生成可能 ・主体的に学び、向上する能力
このニュースはすぐに大きな議論を巻き起こし、マスク氏もリンクを尋ねました。
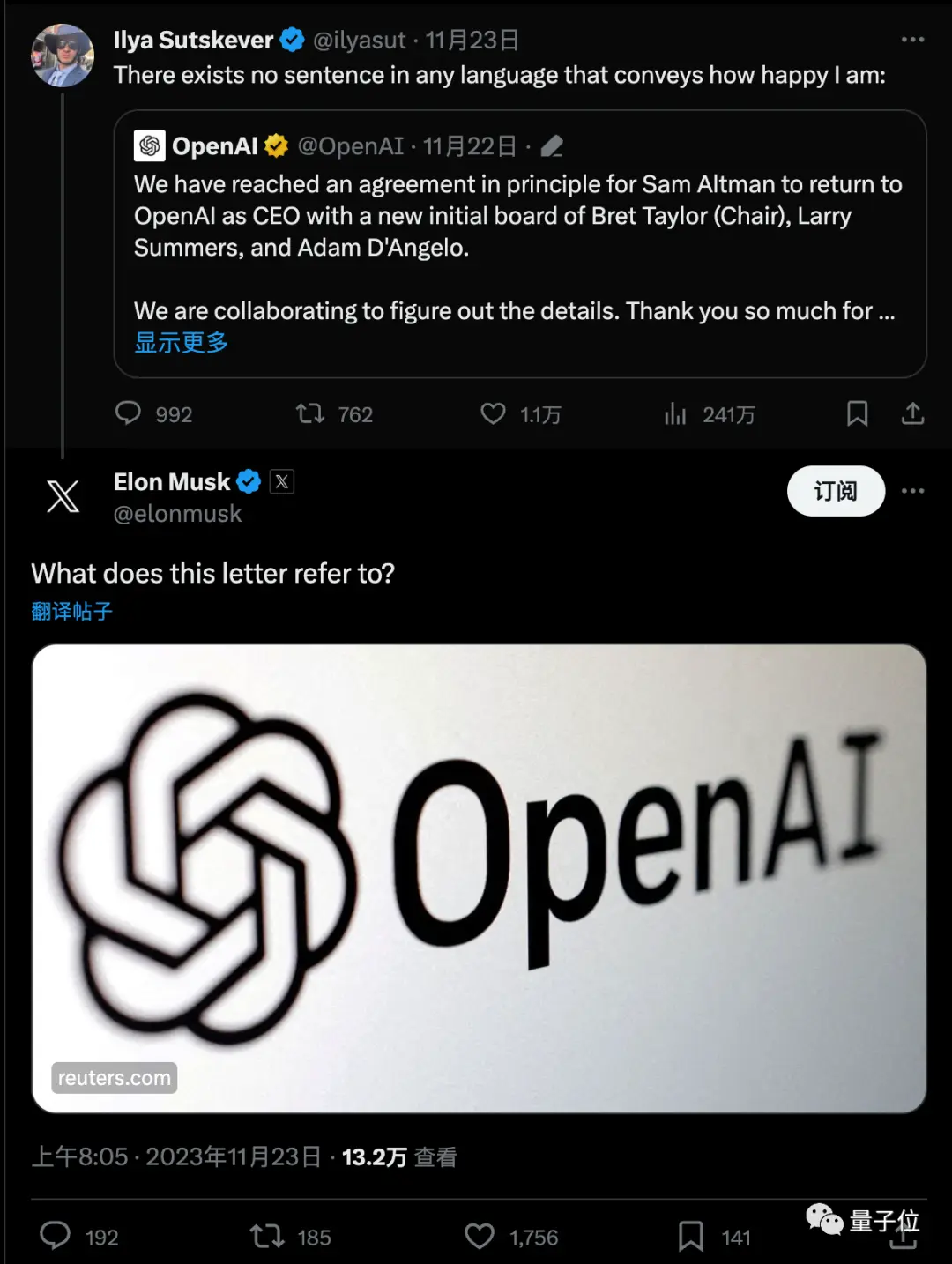 最新のミームは、一夜にして、人々はウルトラマンとOpenAIの取締役会の専門家からQ*の専門家になったということです。
最新のミームは、一夜にして、人々はウルトラマンとOpenAIの取締役会の専門家からQ*の専門家になったということです。

データ制限を破る
The Informationの最新ニュースによると、Q’*は以前はGPT-Zeroとして知られており、Ilya Sutskeverが立ち上げたプロジェクトで、DeepMindのAlpha-Zeroに敬意を表した名前が付けられています。
Alpha-Zeroは人間のチェスゲームを学ぶ必要はありませんが、自分自身と対戦することで囲碁のプレイを学びます。
GPT-Zeroは、インターネットからスクレイピングしたテキストや画像などの実世界のデータに頼るのではなく、合成データを使用して次世代AIモデルをトレーニングすることを可能にします。
2021年にGPT-Zeroが正式に設立され、それ以来、直接関係するニュースはあまりありませんでした。
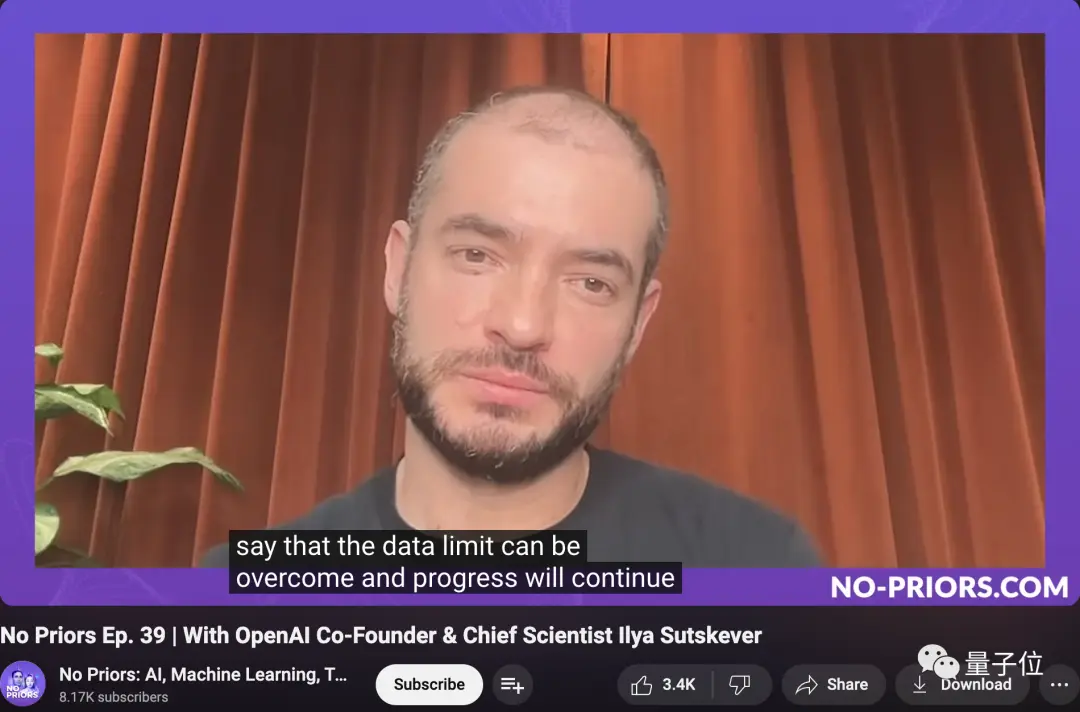
しかし、ほんの数週間前、イリヤはインタビューで次のように述べている。
あまり詳細には触れませんが、データの限界は克服でき、進歩は続くということだけをお伝えしたいと思います。
 GPT-ZeroをベースにしたQ*は、Jakub Pachocki氏とSzymon Sidor氏によって開発されました。
GPT-ZeroをベースにしたQ*は、Jakub Pachocki氏とSzymon Sidor氏によって開発されました。
2人ともOpenAIの初期メンバーであり、ウルトラマンに続いてマイクロソフトに行くことを最初に発表したメンバーでもありました。
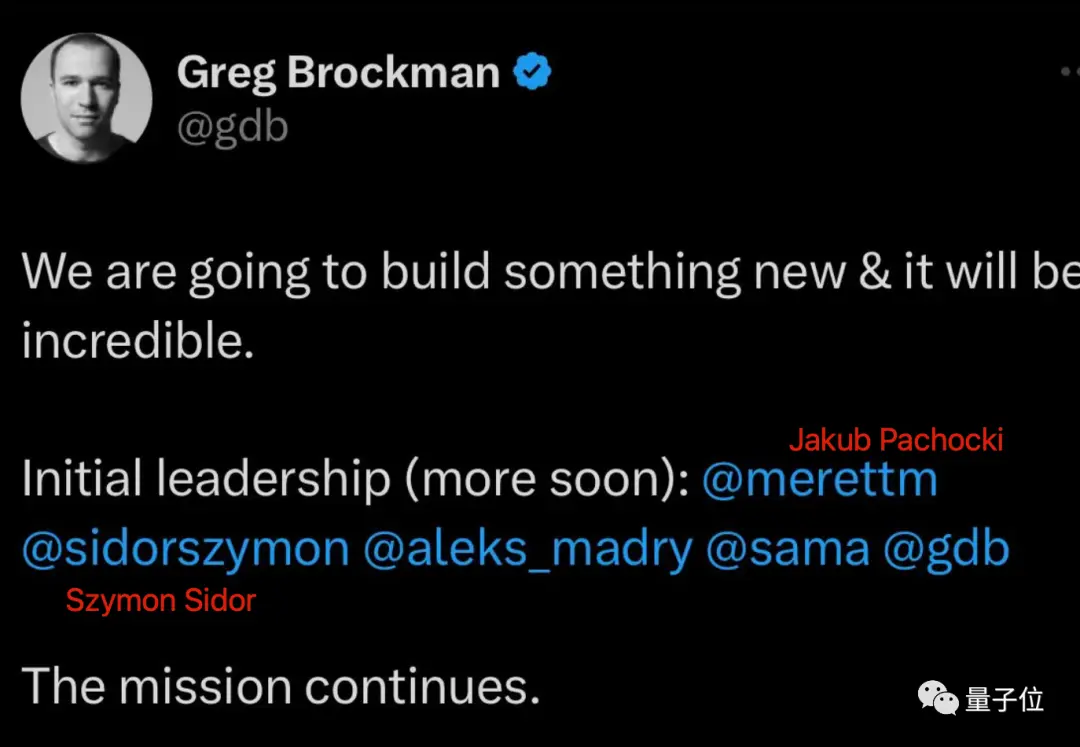 先月リサーチディレクターに昇進したJakub Pachocki氏は、Dota 2プロジェクトやGPT-4の事前トレーニングなど、過去の多くのブレークスルーに大きく貢献してきました。
先月リサーチディレクターに昇進したJakub Pachocki氏は、Dota 2プロジェクトやGPT-4の事前トレーニングなど、過去の多くのブレークスルーに大きく貢献してきました。
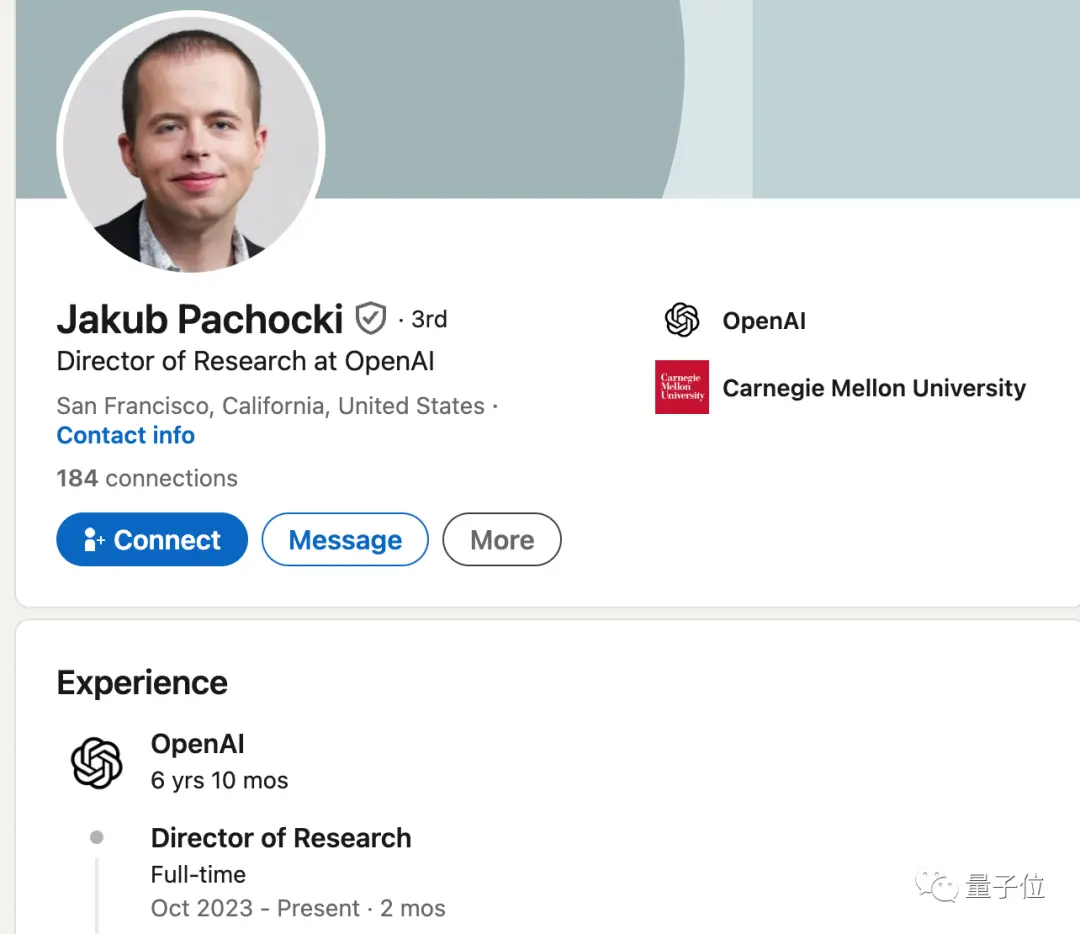 Szymon Sidor は Dota 2 プロジェクトにも携わっており、彼の経歴は「AGIを行ごとに構築する」ことです。
Szymon Sidor は Dota 2 プロジェクトにも携わっており、彼の経歴は「AGIを行ごとに構築する」ことです。
 ロイターのメッセージでは、Q*には特定の数学的問題を解くために膨大な計算リソースが与えられていると言及されています。 現在の数学の能力は小学校レベルにすぎませんが、研究者たちは将来の成功について非常に楽観的です。
ロイターのメッセージでは、Q*には特定の数学的問題を解くために膨大な計算リソースが与えられていると言及されています。 現在の数学の能力は小学校レベルにすぎませんが、研究者たちは将来の成功について非常に楽観的です。
また、OpenAIは初期の頃に「Code Gen」と「Math Gen」の2つのチームが合併した「AIサイエンティスト」という新しいチームを設立し、AIの推論能力を向上させるための探索と最適化を行い、最終的には科学的探索を行っていることが言及されました。
3つの推測
Q*が正確に何であるかについて、これ以上具体的な言葉はありませんが、名前からQ-Learningと関係があるのではないかと推測する人もいます。
1989年に遡るQ-Learningは、ランダム因子や報酬関数を持つ伝達関数であっても環境のモデリングを必要とせず、特別な変更なしで適応できるモデルフリーの強化学習アルゴリズムです。
他の強化学習アルゴリズムとは対照的に、Q-Learningは、行動戦略自体を直接学習するのではなく、各状態と行動のペアの価値を学習して、どの行動が長期的に最大のリターンをもたらすかを決定することに重点を置いています。
2つ目の推測は、OpenAIが5月にリリースした「結果の監督」ではなく「プロセスの監督」によって数学の問題を解くことに関係しています。
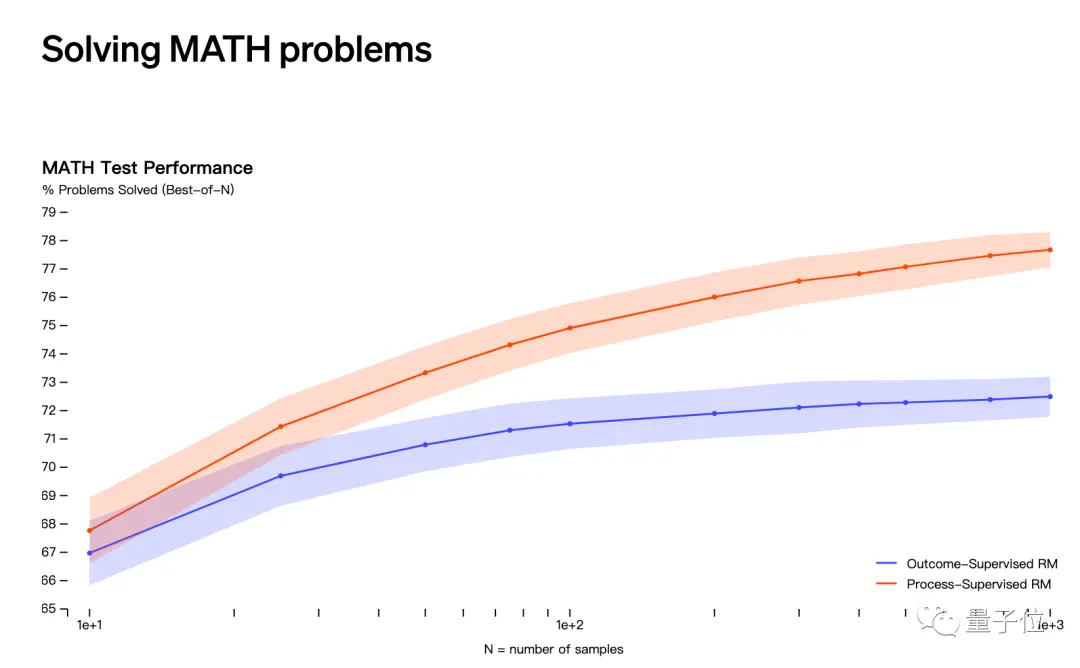 しかし、Jakub Pachocki氏とSzymon Sidor氏の名前は、この研究の貢献者リストには含まれていない。
しかし、Jakub Pachocki氏とSzymon Sidor氏の名前は、この研究の貢献者リストには含まれていない。
 また、7月にOpenAIに入社した「Depo AIの父」であるNoam Brown氏もプロジェクトに関わっているのではないかという憶測も出ています。
また、7月にOpenAIに入社した「Depo AIの父」であるNoam Brown氏もプロジェクトに関わっているのではないかという憶測も出ています。
 入社当時、これまでゲームにしか適用できなかった手法を一般化したい、推論は1000倍遅くてコストがかかるかもしれないが、新薬を発見したり、数学的予想を証明したりできるかもしれないと語っていました。
入社当時、これまでゲームにしか適用できなかった手法を一般化したい、推論は1000倍遅くてコストがかかるかもしれないが、新薬を発見したり、数学的予想を証明したりできるかもしれないと語っていました。
これは、「膨大な計算リソースを必要とする」とか「特定の数学的問題を解くことができる」という噂の説明と一致しています。
 まだ憶測が飛び交っていますが、合成データと強化学習がAIを次のレベルに引き上げることができるかどうかは、業界で最も議論されているトピックの1つになっています。
まだ憶測が飛び交っていますが、合成データと強化学習がAIを次のレベルに引き上げることができるかどうかは、業界で最も議論されているトピックの1つになっています。
エヌビディアの科学者であるファン・リンシー氏は、合成データによって何兆もの高品質のトレーニングトークンが得られると考えており、重要な問題は、品質を維持し、時期尚早にボトルネックに陥らないようにする方法です。
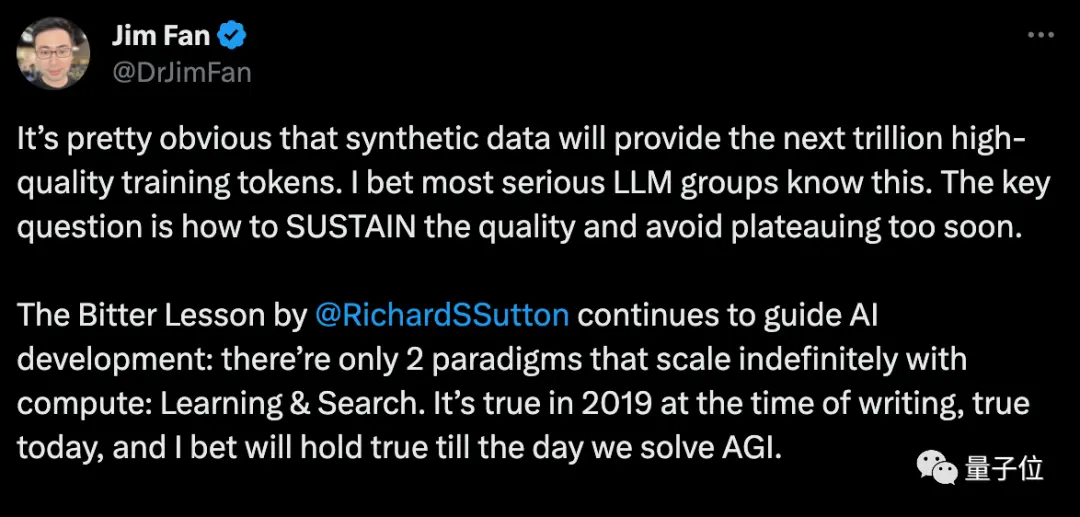 Musk氏もこれに同意し、人間が書いた本はすべてハードドライブに収まる可能性があり、合成データはそれをはるかに超えるものになるだろうと述べています。
Musk氏もこれに同意し、人間が書いた本はすべてハードドライブに収まる可能性があり、合成データはそれをはるかに超えるものになるだろうと述べています。
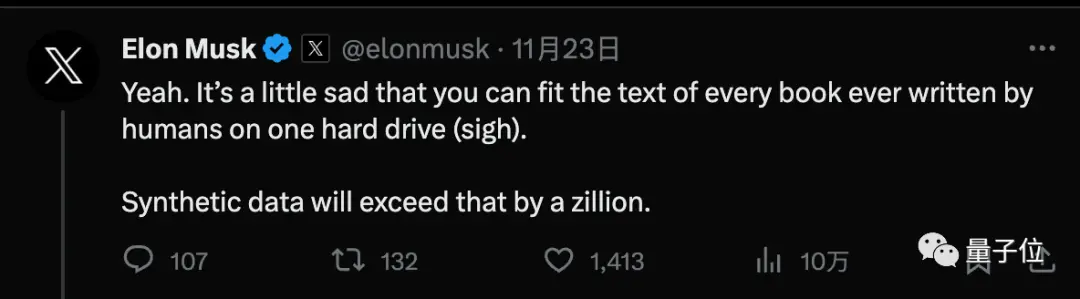 しかし、チューリング賞の三頭政治の1人であるルカンは、合成データを増やすことはその場しのぎの手段であり、AIは人間や動物と同じように、最終的には非常に少ないデータで学習する必要があると主張しています。
しかし、チューリング賞の三頭政治の1人であるルカンは、合成データを増やすことはその場しのぎの手段であり、AIは人間や動物と同じように、最終的には非常に少ないデータで学習する必要があると主張しています。
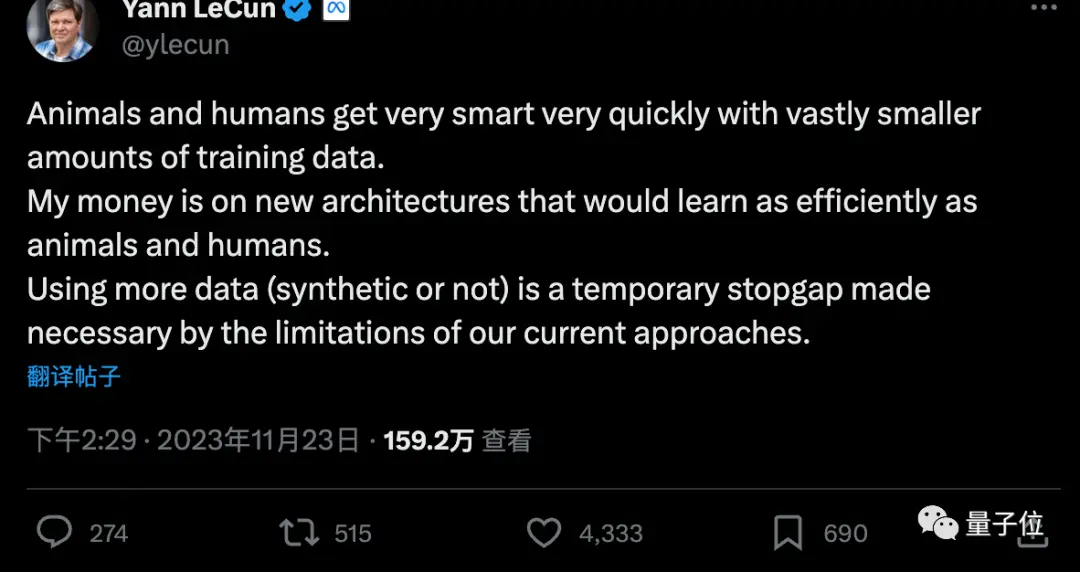 ライス大学のCameron R. Wolfe博士は、Q-Learningは汎用人工知能を解き放つ秘訣ではないかもしれないと述べています。
ライス大学のCameron R. Wolfe博士は、Q-Learningは汎用人工知能を解き放つ秘訣ではないかもしれないと述べています。
しかし、「合成データ」と「データ効率の高い強化学習アルゴリズム」を組み合わせることが、現在のAI研究パラダイムを前進させる鍵となるかもしれません。
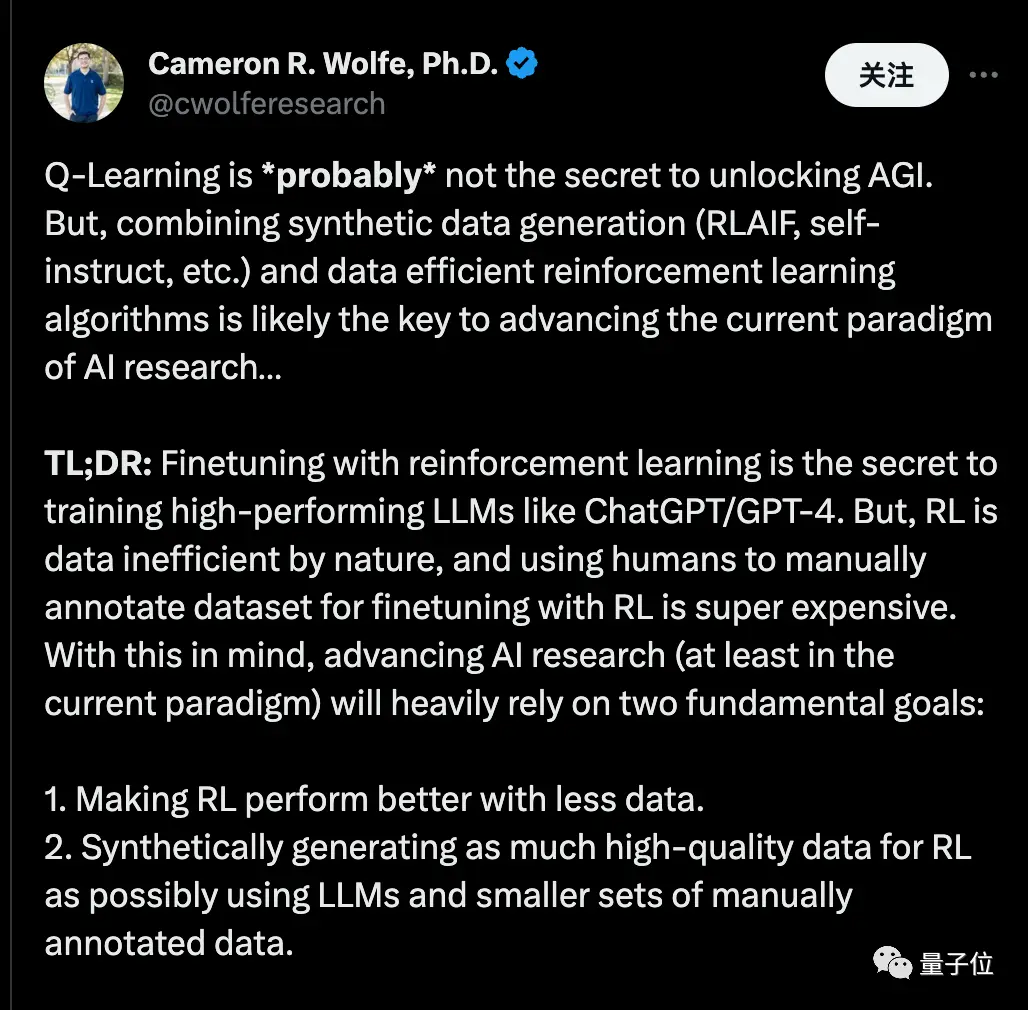
強化学習による微調整が、ChatGPT/GPT-4のような高性能な大規模モデルを学習させる秘訣だという。 しかし、強化学習は本質的にデータ効率が悪く、人間が手作業でラベル付けしたデータセットを使用して強化学習を微調整するには非常にコストがかかります。 このことを念頭に置いて、AI研究の推進は(少なくとも現在のパラダイムでは)2つの基本的な目標に大きく依存します。
- より少ないデータで強化学習のパフォーマンスを向上させます。 *可能な限り、大規模なモデルと少量の手動で注釈を付けたデータを使用して、高品質のデータを合成および生成します。
… デコーダのみのトランスフォーマーを使用して、次のトークンパラダイム(つまり、事前学習済みの-> SFT-> RLHF)の予測に固執すると… これら2つの方法を組み合わせることで、多額の資金を持つ研究チームだけでなく、誰もが最先端のトレーニング技術にアクセスできるようになります。
もう1つ
OpenAI社内では、Qのメッセージにまだ誰も反応していない。
しかし、アルトマンは、取締役会に残ったQuoraの創設者であるAdam D’Angeloと数時間友好的な会話をしたことを明らかにしたばかりです。
 アダム・ダンジェロが事件の背後にいたかどうかは、誰もが推測していたように、今や決着がついたようです。
アダム・ダンジェロが事件の背後にいたかどうかは、誰もが推測していたように、今や決着がついたようです。
参考リンク:
[1]
[2]
[3]
[4]
[5]
[6]
免責事項:このページの情報は第三者から提供される場合があり、Gateの見解または意見を代表するものではありません。このページに表示される内容は参考情報のみであり、いかなる金融、投資、または法律上の助言を構成するものではありません。Gateは情報の正確性または完全性を保証せず、当該情報の利用に起因するいかなる損失についても責任を負いません。仮想資産への投資は高いリスクを伴い、大きな価格変動の影響を受けます。投資元本の全額を失う可能性があります。関連するリスクを十分に理解したうえで、ご自身の財務状況およびリスク許容度に基づき慎重に判断してください。詳細は免責事項をご参照ください。
コメント
0/400
コメントなし