Source de l’article : qubits
 Source de l’image : Générée par Unbounded AI
Source de l’image : Générée par Unbounded AI
Le drame de combat de palais d’OpenAI vient de se terminer, et il déclenchera immédiatement un autre tumulte !
Reuters a révélé qu’avant qu’Altman ne soit licencié, plusieurs chercheurs ont écrit des lettres d’avertissement au conseil d’administration qui pourraient avoir déclenché tout l’incident :
Le modèle d’IA de nouvelle génération, nommé en interne Q (prononcé Q-Star), est trop puissant et avancé pour menacer l’humanité.
Q* est dirigé par le personnage central de cette tempête, le scientifique en chef Ilya Sutskever.
Les gens ont rapidement fait le lien avec les remarques précédentes d’Altman au sommet de l’APEC :
Il y a eu quatre fois dans l’histoire d’OpenAI, la dernière fois au cours des dernières semaines, où j’étais dans la salle lorsque nous avons franchi le voile de l’ignorance et atteint la frontière de la découverte, ce qui a été le plus grand honneur de ma carrière. "
 Q* peut avoir les caractéristiques de base suivantes qui sont considérées comme une étape clé sur la voie de l’IAG ou de la superintelligence.
Q* peut avoir les caractéristiques de base suivantes qui sont considérées comme une étape clé sur la voie de l’IAG ou de la superintelligence.
- Dépasser les limites des données humaines et produire vous-même d’énormes quantités de données d’entraînement
- Capacité à apprendre et à s’améliorer de manière autonome
La nouvelle a rapidement déclenché une énorme discussion, et Musk a également demandé avec un lien.
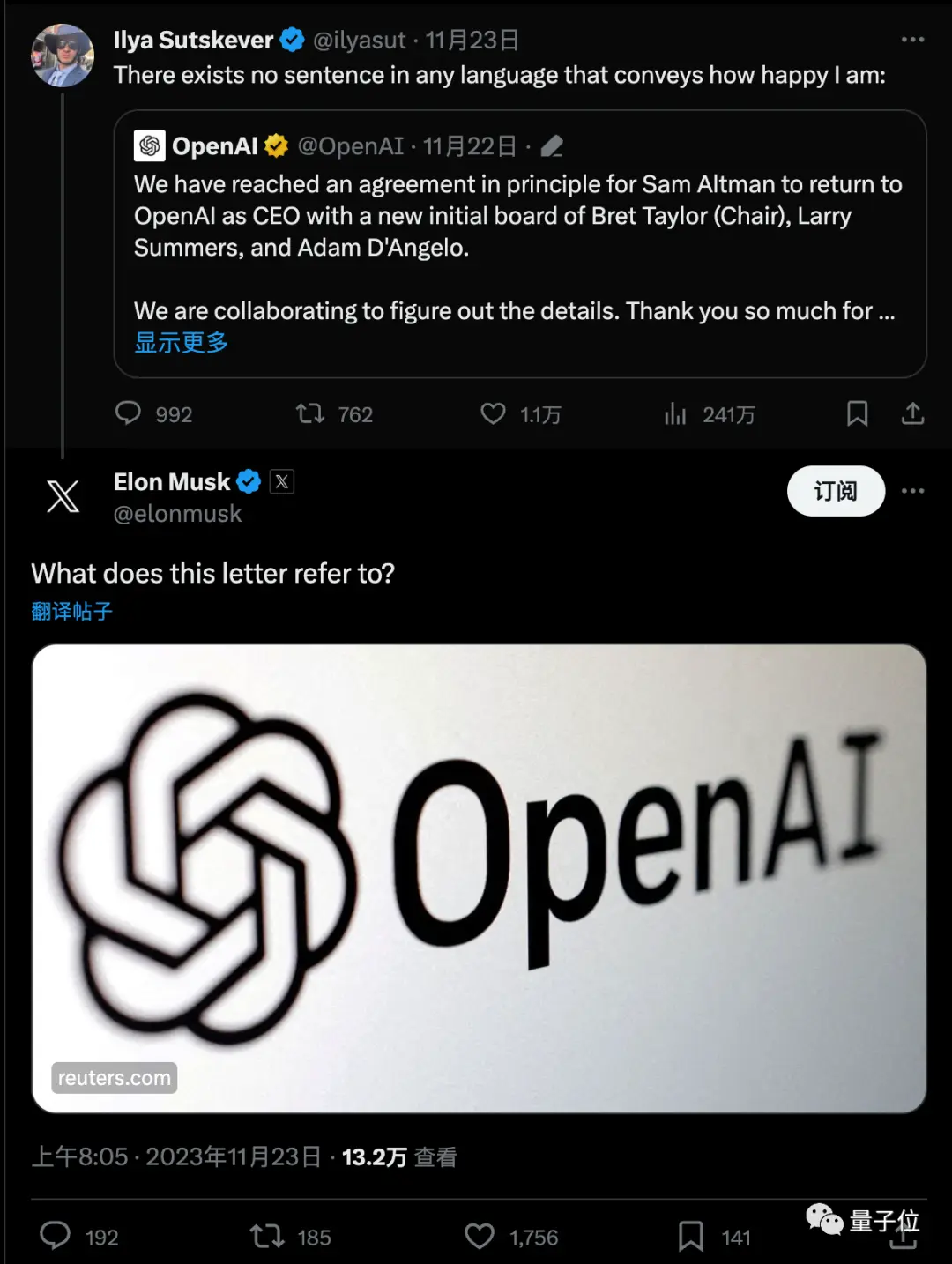 Le dernier mème est que, apparemment du jour au lendemain, les gens sont passés d’experts du conseil d’administration d’Ultraman et d’OpenAI à des experts Q*.
Le dernier mème est que, apparemment du jour au lendemain, les gens sont passés d’experts du conseil d’administration d’Ultraman et d’OpenAI à des experts Q*.

Dépassement des limites de données
Selon les dernières nouvelles de The Information, Q’* était auparavant connu sous le nom de GPT-Zero, un projet initié par Ilya Sutskever, avec un nom qui rend hommage à l’Alpha-Zero de DeepMind.
Alpha-Zero n’a pas besoin d’apprendre les jeux d’échecs humains, mais apprend à jouer au Go en jouant contre lui-même.
GPT-Zero permet d’entraîner des modèles d’IA de nouvelle génération à l’aide de données synthétiques au lieu de s’appuyer sur des données du monde réel telles que du texte ou des images récupérées sur Internet.
En 2021, GPT-Zero a été officiellement créé, et il n’y a pas eu beaucoup de nouvelles directement liées depuis lors.
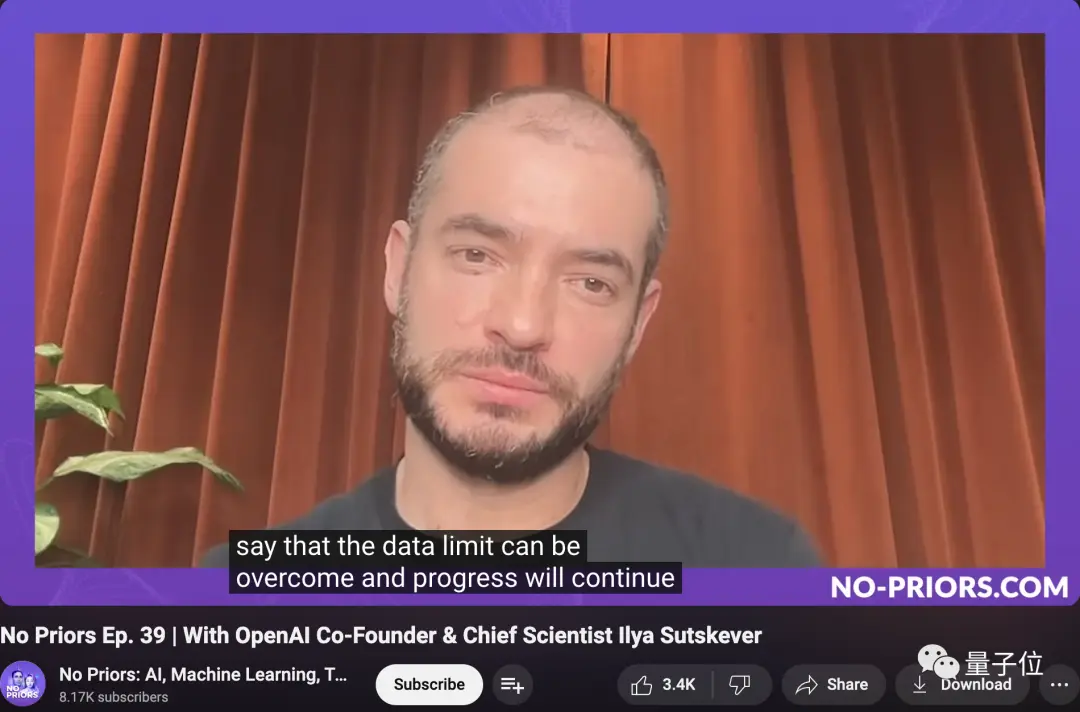
Mais il y a quelques semaines à peine, Ilya a mentionné dans une interview :
Sans trop entrer dans les détails, je veux juste dire que les limites des données peuvent être surmontées et que les progrès se poursuivront.
 Basé sur GPT-Zero, Q* a été développé par Jakub Pachocki et Szymon Sidor.
Basé sur GPT-Zero, Q* a été développé par Jakub Pachocki et Szymon Sidor.
Tous deux ont été les premiers membres d’OpenAI, et ils ont également été les premiers membres à annoncer qu’ils suivraient Ultraman chez Microsoft.
 Jakub Pachocki, qui a été promu directeur de la recherche le mois dernier, a été l’un des principaux contributeurs à bon nombre de ses percées passées, notamment le projet Dota 2 et la pré-formation GPT-4.
Jakub Pachocki, qui a été promu directeur de la recherche le mois dernier, a été l’un des principaux contributeurs à bon nombre de ses percées passées, notamment le projet Dota 2 et la pré-formation GPT-4.
 Szymon Sidor a également travaillé sur le projet Dota 2, et sa biographie est « construire AGI, ligne par ligne ».
Szymon Sidor a également travaillé sur le projet Dota 2, et sa biographie est « construire AGI, ligne par ligne ».
 Dans le message de Reuters, il a été mentionné que Q* avait reçu d’énormes ressources de calcul pour pouvoir résoudre certains problèmes mathématiques. Bien que la capacité mathématique actuelle ne se situe qu’au niveau de l’école primaire, les chercheurs sont très optimistes quant à la réussite future.
Dans le message de Reuters, il a été mentionné que Q* avait reçu d’énormes ressources de calcul pour pouvoir résoudre certains problèmes mathématiques. Bien que la capacité mathématique actuelle ne se situe qu’au niveau de l’école primaire, les chercheurs sont très optimistes quant à la réussite future.
En outre, il a été mentionné qu’OpenAI a mis en place une nouvelle équipe de « scientifiques de l’IA », qui est une fusion des deux équipes de « Code Gen » et « Math Gen » dans les premiers jours, et explore et optimise pour améliorer la capacité de raisonnement de l’IA, et éventuellement mener une exploration scientifique.
Trois suppositions
Il n’y a pas de mot plus précis sur ce qu’est exactement Q*, mais certains ont spéculé à partir du nom qu’il pourrait avoir quelque chose à voir avec Q-Learning.
Q-Learning, qui remonte à 1989, est un algorithme d’apprentissage par renforcement sans modèle qui ne nécessite pas de modélisation de l’environnement, même pour les fonctions de transfert avec des facteurs aléatoires ou des fonctions de récompense, et peut être adapté sans modifications particulières.
Contrairement à d’autres algorithmes d’apprentissage par renforcement, Q-Learning se concentre sur l’apprentissage de la valeur de chaque paire état-action pour décider quelle action apportera le meilleur rendement à long terme, plutôt que d’apprendre directement la stratégie d’action elle-même.
La deuxième supposition concerne la sortie d’OpenAI en mai selon laquelle il résout les problèmes mathématiques par le biais de la « supervision des processus » plutôt que de la « supervision des résultats ».
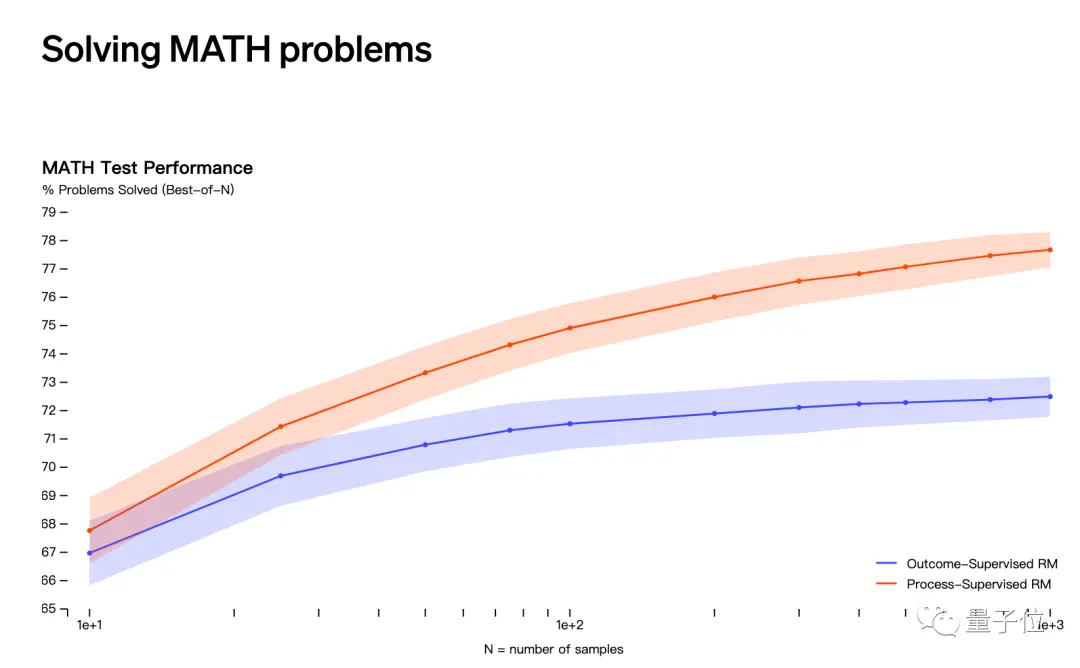 Cependant, les noms de Jakub Pachocki et Szymon Sidor n’apparaissent pas dans la liste des contributeurs à cette étude.
Cependant, les noms de Jakub Pachocki et Szymon Sidor n’apparaissent pas dans la liste des contributeurs à cette étude.
 Il y a aussi des spéculations selon lesquelles Noam Brown, le « père de Depo AI » qui a rejoint OpenAI en juillet, pourrait également être impliqué dans le projet.
Il y a aussi des spéculations selon lesquelles Noam Brown, le « père de Depo AI » qui a rejoint OpenAI en juillet, pourrait également être impliqué dans le projet.
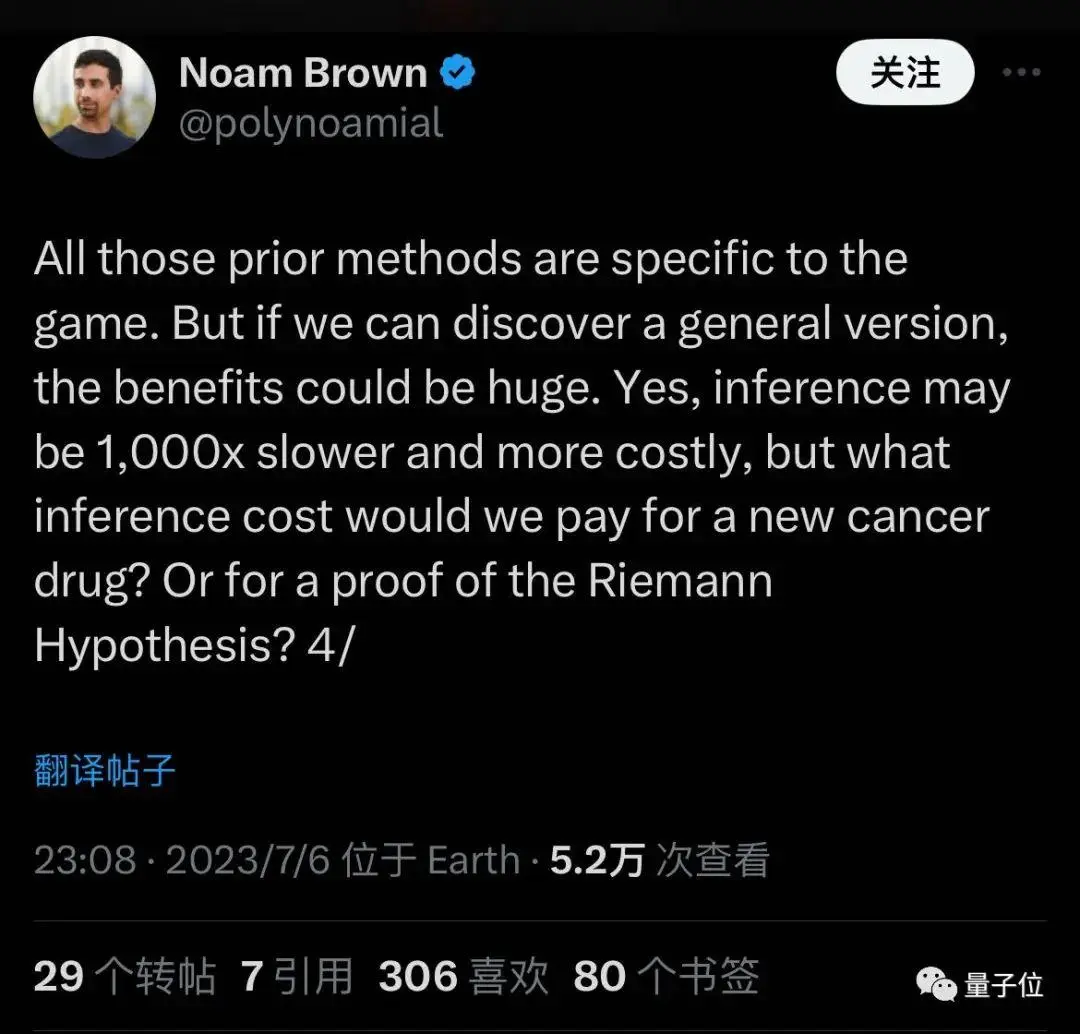
 Lorsqu’il s’est joint à l’équipe, il a dit qu’il voulait généraliser les méthodes qui n’étaient auparavant applicables qu’aux jeux, et que le raisonnement pourrait être 1000 fois plus lent et plus coûteux, mais pourrait découvrir de nouvelles drogues ou prouver des conjectures mathématiques.
Lorsqu’il s’est joint à l’équipe, il a dit qu’il voulait généraliser les méthodes qui n’étaient auparavant applicables qu’aux jeux, et que le raisonnement pourrait être 1000 fois plus lent et plus coûteux, mais pourrait découvrir de nouvelles drogues ou prouver des conjectures mathématiques.
Cela correspond aux rumeurs selon lesquelles « il faut d’énormes ressources informatiques » et « être capable de résoudre certains problèmes mathématiques ».
 Bien que de plus en plus de spéculations soient encore faites, la question de savoir si les données synthétiques et l’apprentissage par renforcement peuvent faire passer l’IA au niveau supérieur est devenue l’un des sujets les plus discutés dans l’industrie.
Bien que de plus en plus de spéculations soient encore faites, la question de savoir si les données synthétiques et l’apprentissage par renforcement peuvent faire passer l’IA au niveau supérieur est devenue l’un des sujets les plus discutés dans l’industrie.
Le scientifique de Nvidia, Fan Linxi, pense que les données synthétiques fourniront des milliards de jetons d’entraînement de haute qualité, et la question clé est de savoir comment maintenir la qualité et éviter de tomber prématurément dans des goulots d’étranglement.
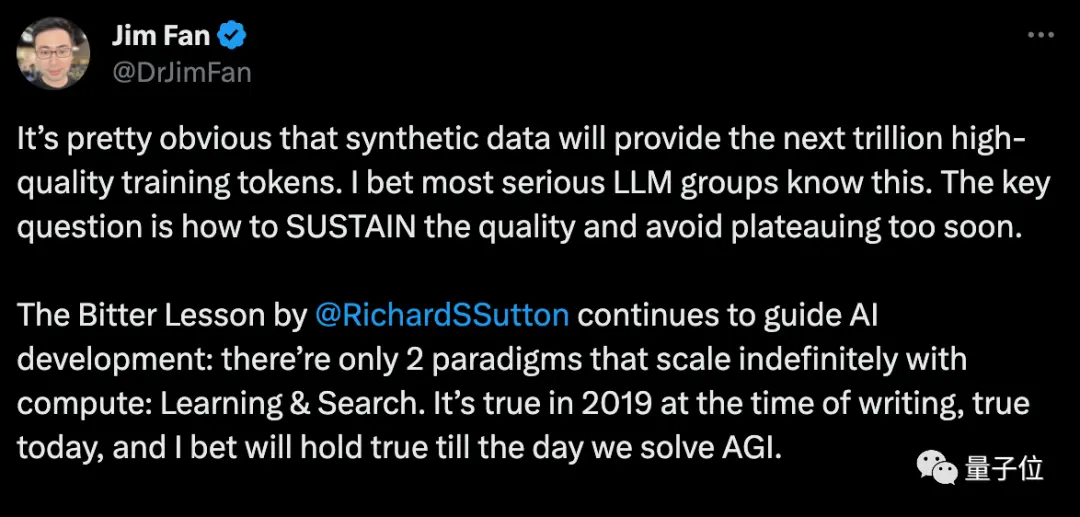 Musk est d’accord, mentionnant que chaque livre écrit par un humain peut tenir sur un disque dur, et que les données synthétiques seront bien au-delà.
Musk est d’accord, mentionnant que chaque livre écrit par un humain peut tenir sur un disque dur, et que les données synthétiques seront bien au-delà.
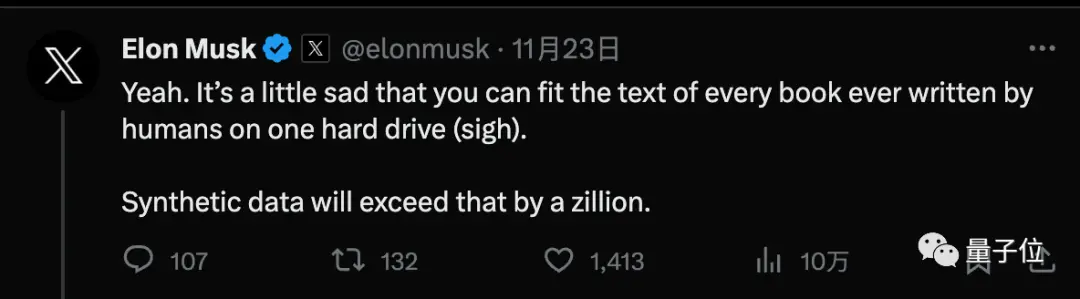 Mais LeCun, l’un des triumvirats du prix Turing, soutient que davantage de données synthétiques sont une mesure provisoire et que l’IA devra finalement apprendre avec très peu de données, tout comme les humains ou les animaux.
Mais LeCun, l’un des triumvirats du prix Turing, soutient que davantage de données synthétiques sont une mesure provisoire et que l’IA devra finalement apprendre avec très peu de données, tout comme les humains ou les animaux.
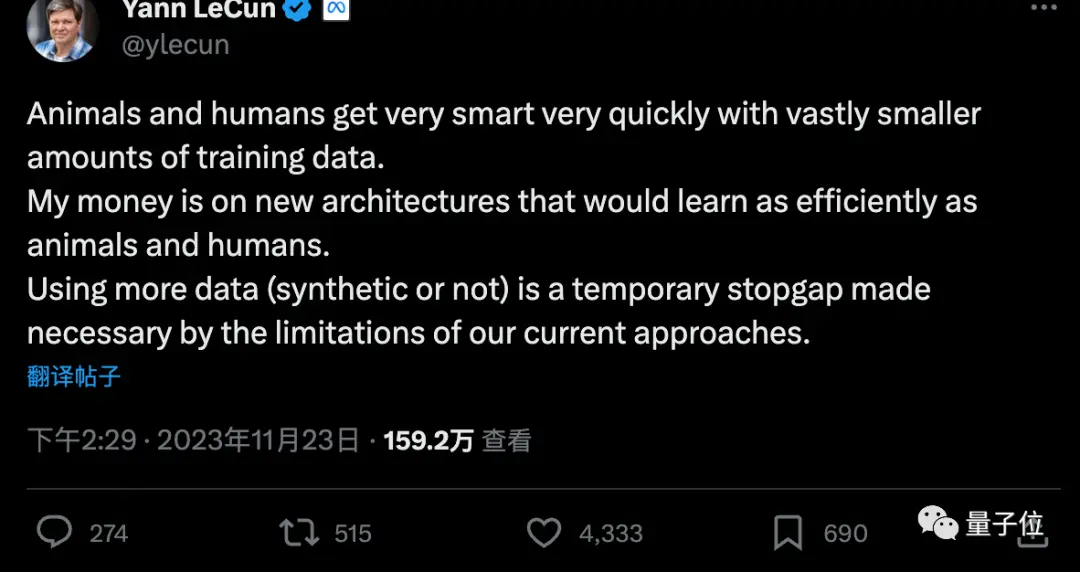 Cameron R. Wolfe, Ph.D. à l’Université Rice, a déclaré que Q-Learning n’est peut-être pas le secret pour débloquer l’AGI.
Cameron R. Wolfe, Ph.D. à l’Université Rice, a déclaré que Q-Learning n’est peut-être pas le secret pour débloquer l’AGI.
Mais la combinaison de « données synthétiques » avec des « algorithmes d’apprentissage par renforcement efficaces en termes de données » peut être la clé pour faire progresser le paradigme actuel de la recherche sur l’IA.
Il a déclaré que l’ajustement fin grâce à l’apprentissage par renforcement est le secret de l’entraînement de grands modèles haute performance, tels que ChatGPT/GPT-4. Cependant, l’apprentissage par renforcement est intrinsèquement inefficace en termes de données, et il est très coûteux d’affiner l’apprentissage par renforcement à l’aide d’ensembles de données étiquetés manuellement par des humains. Dans cette optique, l’avancement de la recherche sur l’IA (du moins dans le paradigme actuel) reposera fortement sur deux objectifs fondamentaux :
- Améliorer les performances de l’apprentissage par renforcement avec moins de données.
- Synthétiser et générer des données de haute qualité à l’aide de grands modèles et d’une petite quantité de données annotées manuellement dans la mesure du possible.
… Si nous nous en tenons à la prédiction du prochain paradigme de jeton (c’est-à-dire pré-entraîné -> SFT -> RLHF) à l’aide d’un transformateur de décodeur uniquement… La combinaison de ces deux méthodes permettra à tout le monde d’avoir accès à des techniques de formation de pointe, et pas seulement à des équipes de recherche avec beaucoup d’argent !
Une dernière chose
Personne au sein d’OpenAI n’a encore répondu au message de Q.
Mais Altman vient de révéler qu’il a eu quelques heures de conversation amicale avec le fondateur de Quora, Adam D’Angelo, qui est resté au conseil d’administration.
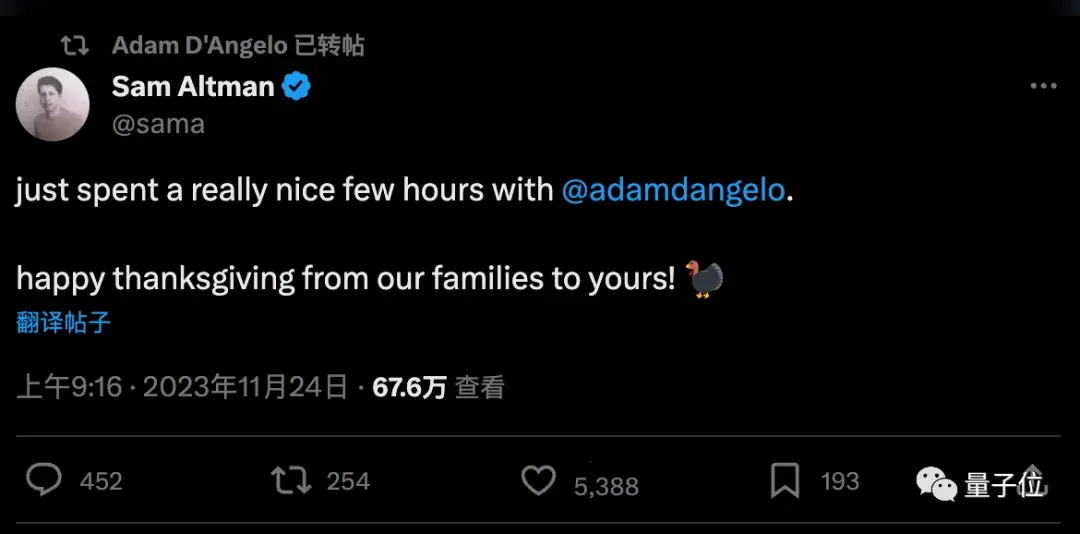 Il semble que la question de savoir si Adam D’Angelo était ou non derrière l’incident, comme tout le monde l’avait spéculé, a maintenant trouvé un règlement.
Il semble que la question de savoir si Adam D’Angelo était ou non derrière l’incident, comme tout le monde l’avait spéculé, a maintenant trouvé un règlement.
Liens de référence :
[1]
[2]
[3]
[4]
[5]
[6]
