谷歌在不损失准确性的情况下缩小了AI的内存——但有个问题
Decrypt
简要介绍
- 谷歌表示,其TurboQuant算法可以在推理过程中将主要的AI内存瓶颈至少缩减六倍,同时不影响准确性。
- 包括美光、西部数据和希捷在内的存储股在相关论文流出后下跌。
- 该方法压缩推理内存,而非模型权重,目前仅在研究基准测试中验证。
谷歌研究团队于周三发布了TurboQuant,这是一种压缩算法,能在保持零准确率损失的情况下,将主要的推理内存瓶颈缩小至少6倍。 该论文计划在2026年ICLR会议上展示,线上反响立即热烈。 Cloudflare首席执行官Matthew Prince称其为谷歌的DeepSeek时刻。当天,包括美光、西部数据和希捷在内的存储股价格下跌。
那么,这是真的吗? 量化效率本身就是一项重大成就。但“零准确率损失”需要一些背景说明。 TurboQuant的目标是KV缓存——存储在GPU内存中的一块区域,用于保存语言模型在对话中需要记忆的所有内容。 随着上下文窗口扩大到数百万个标记,这些缓存会膨胀到每次会话数百GB。这才是真正的瓶颈。不是计算能力,而是原始内存。
传统的压缩方法试图通过向下取整数字来缩小这些缓存——比如从32位浮点数到16位,再到8位或4位整数。理解起来就像把一张4K分辨率的图片压缩到全高清、720p等等。整体上还能辨认出是同一张图片,但4K分辨率下细节更多。 问题在于:它们必须在压缩数据旁边存储额外的“量化常数”以防模型出错。这些常数每个值会增加1到2比特,部分抵消了压缩带来的收益。 TurboQuant声称完全消除了这种开销。 它通过两个子算法实现:PolarQuant将向量的大小与方向分离,QJL(量化的Johnson-Lindenstrauss)则将剩余的微小误差缩减为单一符号位(正或负),无需存储常数。 谷歌表示,最终结果是对驱动变换器模型的注意力计算的数学无偏估计。 在使用Gemma和Mistral的基准测试中,TurboQuant在4倍压缩下达到了全精度性能,包括在高达104,000个标记的“针在草堆中找针”任务中的完美检索准确率。 关于这些基准测试的重要性,扩大模型的可用上下文而不损失质量,一直是大规模语言模型部署中最难的问题之一。
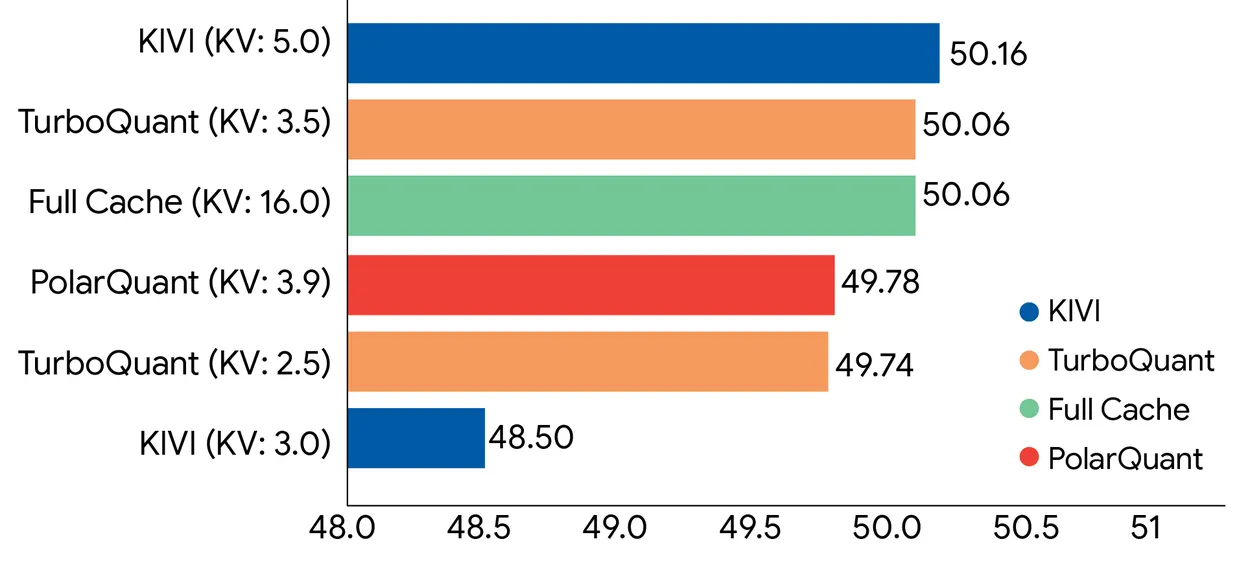
现在,细节部分。 “零准确率损失”仅适用于推理过程中的KV缓存压缩——不包括模型的权重。压缩权重是完全不同、更难的问题,TurboQuant不涉及这些。 它压缩的是存储会话中间注意力计算的临时内存,这部分更容易,因为理论上可以重建这些数据。 此外,存在一个差距:在纯净的基准测试和实际生产系统(处理数十亿请求)之间。TurboQuant是在开源模型(如Gemma、Mistral、Llama)上测试的,而非谷歌自己大规模的Gemini系统。 不同于DeepSeek的效率提升需要从一开始就深度架构设计,TurboQuant无需重新训练或微调,声称几乎没有运行时开销。理论上可以直接集成到现有的推理流程中。 这也是让存储硬件行业感到震惊的部分——因为如果它在生产中奏效,每个主要的AI实验室都可以用相同的GPU变得更高效。 论文将提交到2026年ICLR会议。在正式投入生产之前,“零损失”的说法仍只停留在实验室阶段。
免责声明:本页面信息可能来自第三方,不代表 Gate 的观点或意见。页面显示的内容仅供参考,不构成任何财务、投资或法律建议。Gate 对信息的准确性、完整性不作保证,对因使用本信息而产生的任何损失不承担责任。虚拟资产投资属高风险行为,价格波动剧烈,您可能损失全部投资本金。请充分了解相关风险,并根据自身财务状况和风险承受能力谨慎决策。具体内容详见声明。
评论
0/400
暂无评论