Nguồn bài viết: qubits
 Nguồn hình ảnh: Được tạo bởi Unbounded AI
Nguồn hình ảnh: Được tạo bởi Unbounded AI
Bộ phim chiến đấu cung điện OpenAI vừa kết thúc, và nó sẽ ngay lập tức gây ra một sự náo động khác!
Reuters tiết lộ rằng trước khi Altman bị sa thải, một số nhà nghiên cứu đã viết thư cảnh báo cho ban giám đốc có thể đã gây ra toàn bộ vụ việc:
Mô hình AI thế hệ tiếp theo, có tên nội bộ là Q (phát âm là Q-Star), quá mạnh mẽ và tiên tiến để đe dọa nhân loại.
Q* được dẫn dắt bởi nhân vật trung tâm của cơn bão này, nhà khoa học trưởng Ilya Sutskever.
Mọi người nhanh chóng liên kết những nhận xét trước đây của Altman tại hội nghị thượng đỉnh APEC:
Đã có bốn lần trong lịch sử của OpenAI, gần đây nhất là trong vài tuần qua, khi tôi ở trong phòng khi chúng tôi vượt qua bức màn của sự thiếu hiểu biết và đạt đến biên giới khám phá, đó là vinh dự cao nhất trong sự nghiệp của tôi. "
 Q* có thể có các đặc điểm cốt lõi sau đây được coi là một bước quan trọng trên con đường dẫn đến AGI hoặc siêu trí tuệ.
Q* có thể có các đặc điểm cốt lõi sau đây được coi là một bước quan trọng trên con đường dẫn đến AGI hoặc siêu trí tuệ.
- Vượt qua những hạn chế của dữ liệu con người và có thể tự tạo ra một lượng lớn dữ liệu đào tạo
- Khả năng học hỏi và cải thiện độc lập
Tin tức nhanh chóng gây ra một cuộc thảo luận lớn và Musk cũng hỏi kèm theo một liên kết.
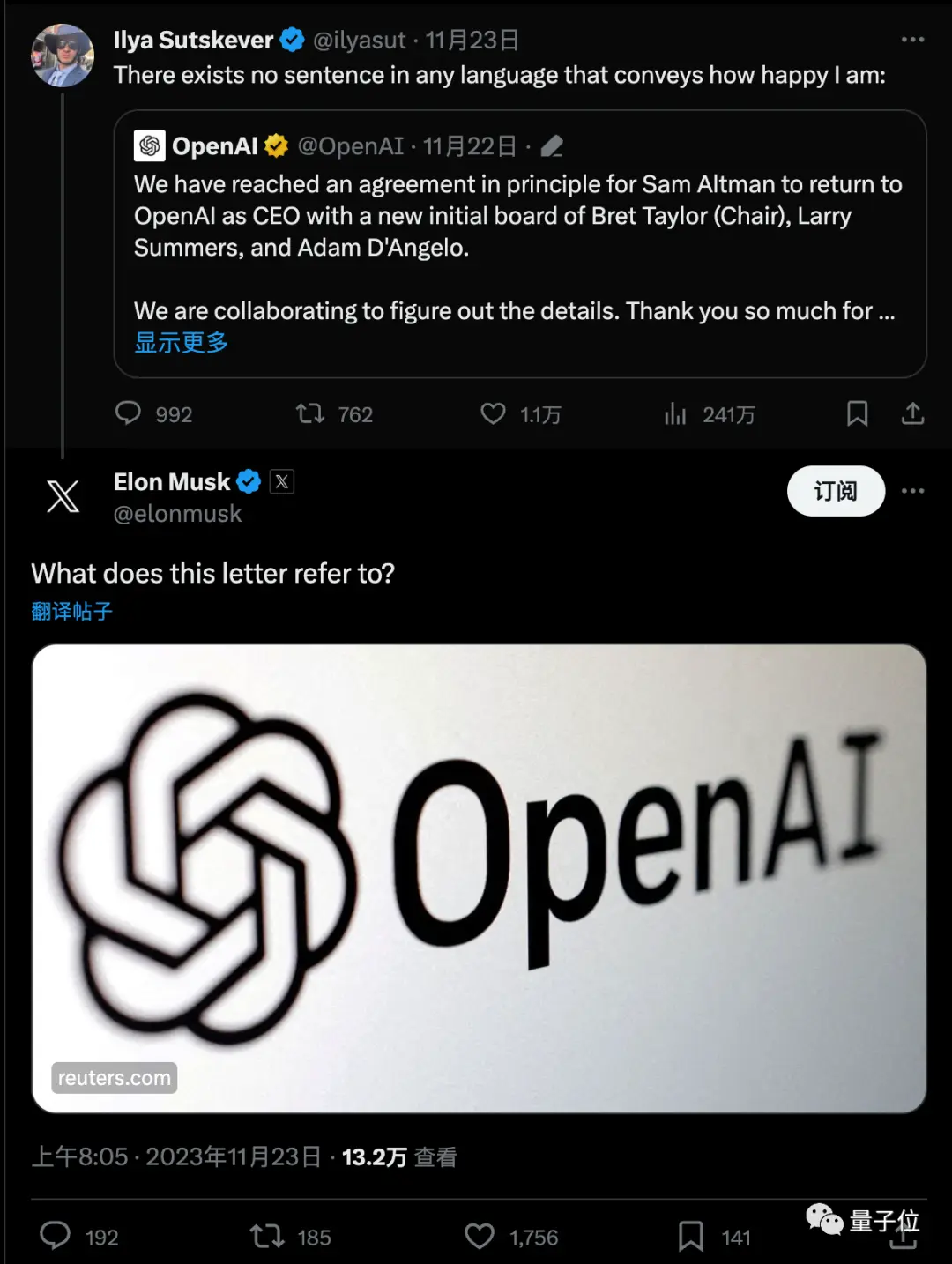 Meme mới nhất là, dường như chỉ sau một đêm, mọi người đã đi từ chuyên gia trong ban giám đốc của Ultraman và OpenAI đến các chuyên gia Q*.
Meme mới nhất là, dường như chỉ sau một đêm, mọi người đã đi từ chuyên gia trong ban giám đốc của Ultraman và OpenAI đến các chuyên gia Q*.

**Phá vỡ giới hạn dữ liệu **
Theo tin tức mới nhất từ The Information, Q’* trước đây được gọi là GPT-Zero, một dự án do Ilya Sutskever khởi xướng, với cái tên bày tỏ lòng kính trọng đối với Alpha-Zero của DeepMind.
Alpha-Zero không cần phải học các trò chơi cờ vua của con người, nhưng học cách chơi cờ vây bằng cách chơi với chính mình.
GPT-Zero cho phép các mô hình AI thế hệ tiếp theo được đào tạo bằng cách sử dụng dữ liệu tổng hợp thay vì dựa vào dữ liệu trong thế giới thực như văn bản hoặc hình ảnh được lấy từ internet.
Năm 2021, GPT-Zero chính thức được thành lập và không có nhiều tin tức liên quan trực tiếp kể từ đó.
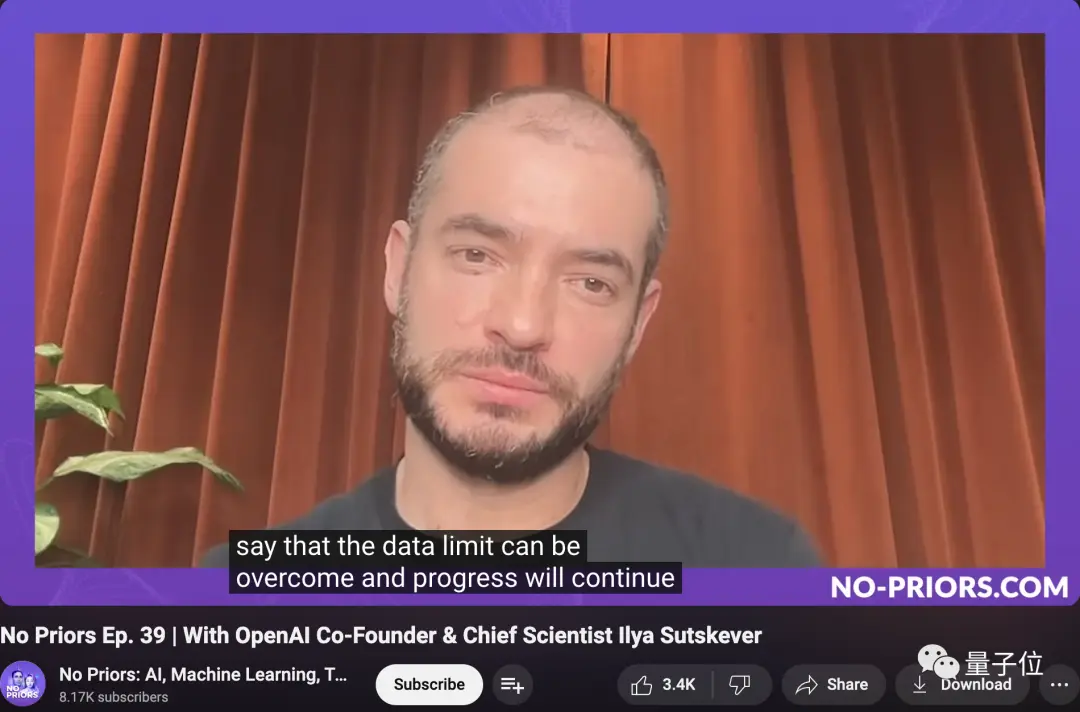
Nhưng chỉ vài tuần trước, Ilya đã đề cập trong một cuộc phỏng vấn:
Không đi sâu vào quá nhiều chi tiết, tôi chỉ muốn nói rằng những hạn chế về dữ liệu có thể được khắc phục và tiến độ sẽ tiếp tục.
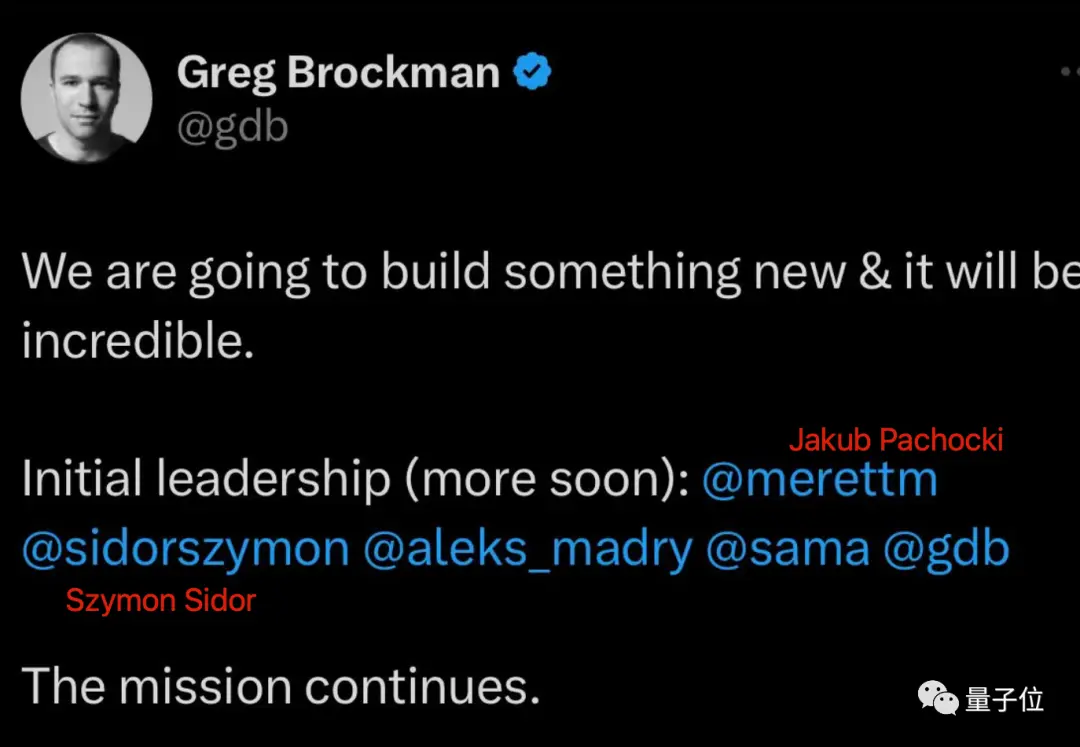
 Dựa trên GPT-Zero, Q* được phát triển bởi Jakub Pachocki và Szymon Sidor.
Dựa trên GPT-Zero, Q* được phát triển bởi Jakub Pachocki và Szymon Sidor.
Cả hai đều là thành viên đầu tiên của OpenAI và họ cũng là những thành viên đầu tiên thông báo rằng họ sẽ theo Ultraman đến Microsoft.
 Jakub Pachocki, người được thăng chức Giám đốc Nghiên cứu vào tháng trước, là người đóng góp cốt lõi cho nhiều đột phá trong quá khứ của ông, bao gồm dự án Dota 2 và đào tạo trước GPT-4.
Jakub Pachocki, người được thăng chức Giám đốc Nghiên cứu vào tháng trước, là người đóng góp cốt lõi cho nhiều đột phá trong quá khứ của ông, bao gồm dự án Dota 2 và đào tạo trước GPT-4.
 Szymon Sidor cũng đã làm việc trong dự án Dota 2, và tiểu sử của anh ấy là “xây dựng AGI, từng dòng một”.
Szymon Sidor cũng đã làm việc trong dự án Dota 2, và tiểu sử của anh ấy là “xây dựng AGI, từng dòng một”.
 Trong tin nhắn của Reuters, người ta đã đề cập rằng Q * đã được cung cấp tài nguyên máy tính khổng lồ để có thể giải quyết một số vấn đề toán học nhất định. Mặc dù khả năng toán học hiện tại chỉ ở cấp tiểu học, các nhà nghiên cứu rất lạc quan về thành công trong tương lai.
Trong tin nhắn của Reuters, người ta đã đề cập rằng Q * đã được cung cấp tài nguyên máy tính khổng lồ để có thể giải quyết một số vấn đề toán học nhất định. Mặc dù khả năng toán học hiện tại chỉ ở cấp tiểu học, các nhà nghiên cứu rất lạc quan về thành công trong tương lai.
Ngoài ra, OpenAI đã thành lập một nhóm “nhà khoa học AI” mới, đó là sự hợp nhất của hai nhóm “Code Gen” và “Math Gen” trong những ngày đầu, và đang khám phá và tối ưu hóa để cải thiện khả năng suy luận của AI, và cuối cùng thực hiện khám phá khoa học.
Ba đoán
Không có từ cụ thể hơn về chính xác Q * là gì, nhưng một số người đã suy đoán từ cái tên rằng nó có thể có liên quan đến Q-Learning.
Q-Learning, có từ năm 1989, là một thuật toán học tăng cường không có mô hình, không yêu cầu mô hình hóa môi trường, ngay cả đối với các chức năng chuyển giao với các yếu tố ngẫu nhiên hoặc chức năng thưởng và có thể được điều chỉnh mà không cần thay đổi đặc biệt.
Trái ngược với các thuật toán học tăng cường khác, Q-Learning tập trung vào việc tìm hiểu giá trị của từng cặp hành động trạng thái để quyết định hành động nào sẽ mang lại lợi nhuận lớn nhất trong thời gian dài, thay vì trực tiếp học chính chiến lược hành động.
Dự đoán thứ hai liên quan đến việc phát hành OpenAI vào tháng Năm rằng nó giải quyết các vấn đề toán học thông qua “giám sát quá trình” thay vì “giám sát kết quả”.
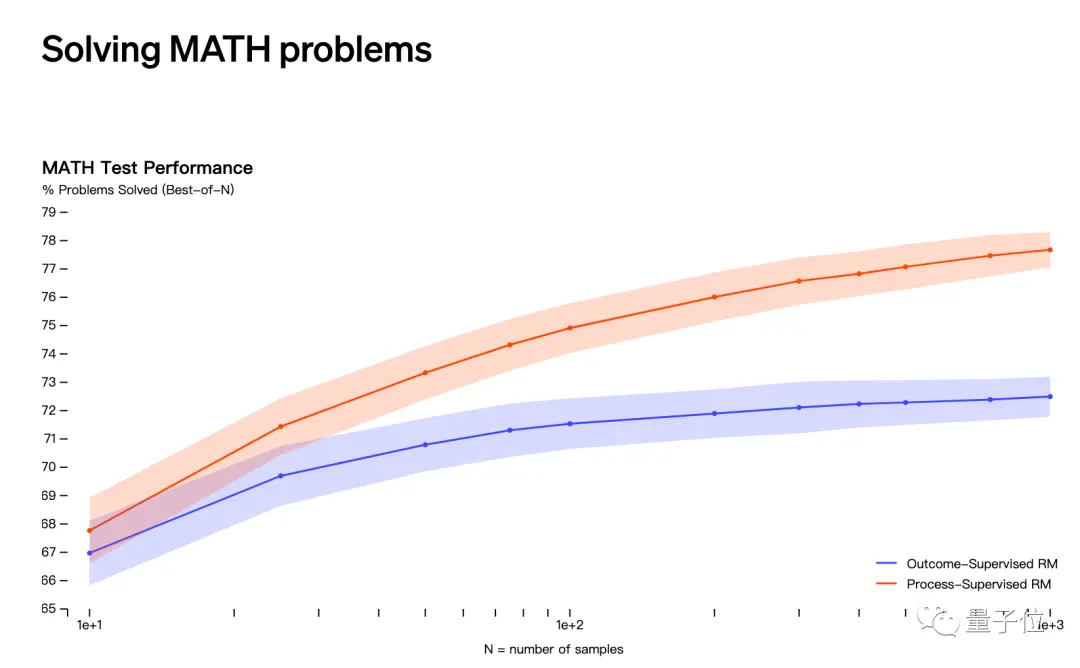 Tuy nhiên, tên của Jakub Pachocki và Szymon Sidor không xuất hiện trong danh sách những người đóng góp cho nghiên cứu này.
Tuy nhiên, tên của Jakub Pachocki và Szymon Sidor không xuất hiện trong danh sách những người đóng góp cho nghiên cứu này.
 Cũng có suy đoán rằng Noam Brown, “cha đẻ của Depo AI”, người đã tham gia OpenAI vào tháng Bảy, cũng có thể tham gia vào dự án.
Cũng có suy đoán rằng Noam Brown, “cha đẻ của Depo AI”, người đã tham gia OpenAI vào tháng Bảy, cũng có thể tham gia vào dự án.
 Khi tham gia, ông nói rằng ông muốn khái quát hóa các phương pháp trước đây chỉ áp dụng cho các trò chơi, và lý luận đó có thể chậm hơn và tốn kém hơn 1000 lần, nhưng có thể khám phá ra các loại thuốc mới hoặc chứng minh các phỏng đoán toán học.
Khi tham gia, ông nói rằng ông muốn khái quát hóa các phương pháp trước đây chỉ áp dụng cho các trò chơi, và lý luận đó có thể chậm hơn và tốn kém hơn 1000 lần, nhưng có thể khám phá ra các loại thuốc mới hoặc chứng minh các phỏng đoán toán học.
Nó phù hợp với các mô tả được đồn đại về “đòi hỏi tài nguyên máy tính khổng lồ” và “có thể giải quyết một số vấn đề toán học nhất định”.
 Trong khi nhiều suy đoán vẫn đang được đưa ra, liệu dữ liệu tổng hợp và học tăng cường có thể đưa AI lên một tầm cao mới hay không đã trở thành một trong những chủ đề được thảo luận nhiều nhất trong ngành.
Trong khi nhiều suy đoán vẫn đang được đưa ra, liệu dữ liệu tổng hợp và học tăng cường có thể đưa AI lên một tầm cao mới hay không đã trở thành một trong những chủ đề được thảo luận nhiều nhất trong ngành.
Nhà khoa học Nvidia Fan Linxi tin rằng dữ liệu tổng hợp sẽ cung cấp hàng nghìn tỷ mã thông báo đào tạo chất lượng cao và câu hỏi quan trọng là làm thế nào để duy trì chất lượng và tránh rơi vào tình trạng tắc nghẽn sớm.
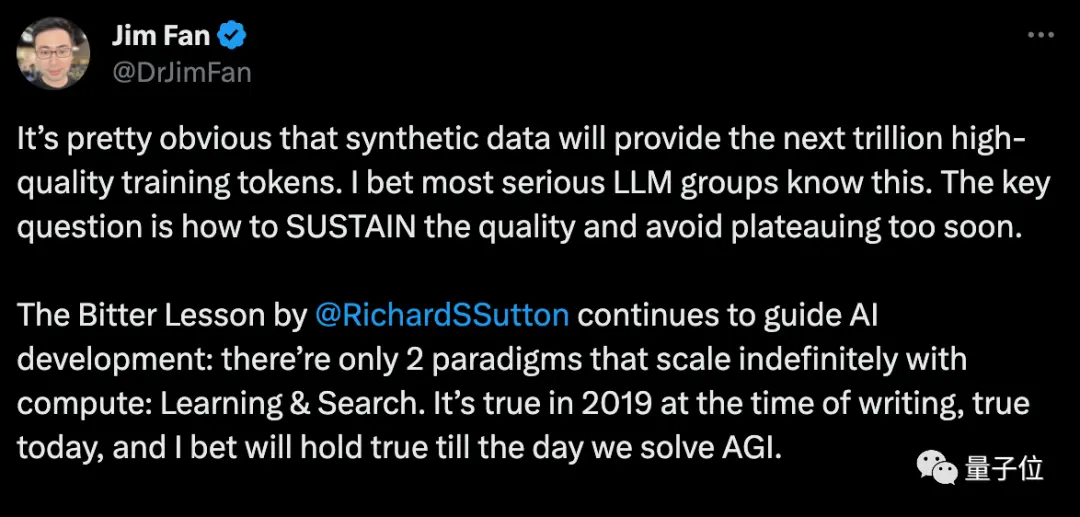 Musk đồng ý, đề cập rằng mọi cuốn sách được viết bởi con người đều có thể nằm gọn trên ổ cứng và dữ liệu tổng hợp sẽ vượt xa điều đó.
Musk đồng ý, đề cập rằng mọi cuốn sách được viết bởi con người đều có thể nằm gọn trên ổ cứng và dữ liệu tổng hợp sẽ vượt xa điều đó.
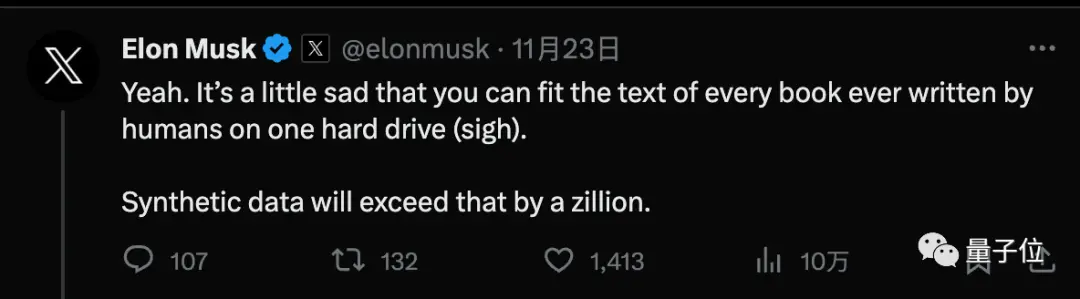 Nhưng LeCun, một trong bộ ba giải thưởng Turing, lập luận rằng nhiều dữ liệu tổng hợp hơn là một biện pháp tạm thời và AI cuối cùng sẽ cần phải học với rất ít dữ liệu, giống như con người hoặc động vật.
Nhưng LeCun, một trong bộ ba giải thưởng Turing, lập luận rằng nhiều dữ liệu tổng hợp hơn là một biện pháp tạm thời và AI cuối cùng sẽ cần phải học với rất ít dữ liệu, giống như con người hoặc động vật.
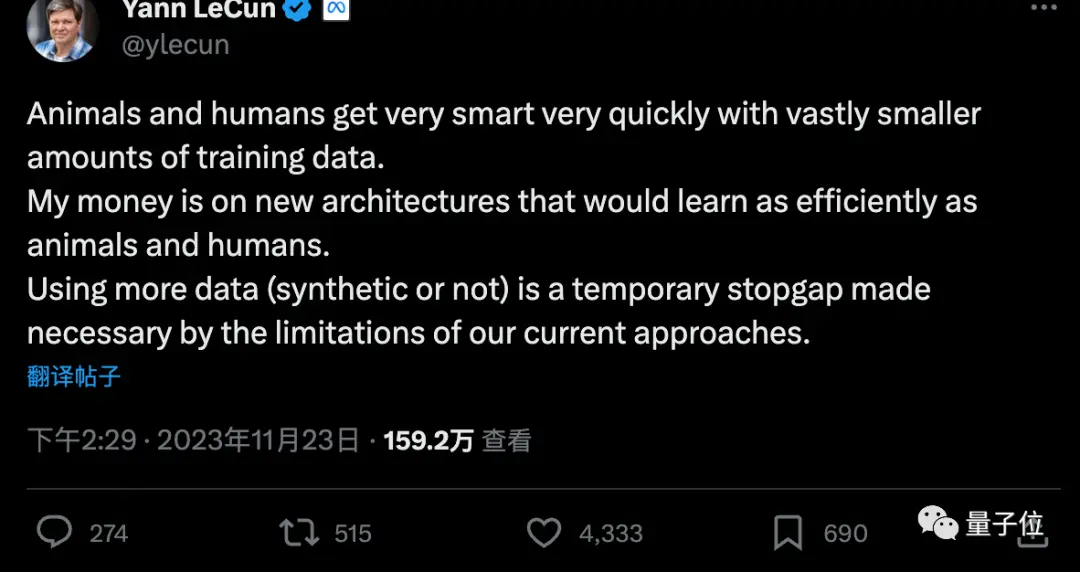 Cameron R. Wolfe, Tiến sĩ tại Đại học Rice, cho biết Q-Learning có thể không phải là bí mật để mở khóa AGI.
Cameron R. Wolfe, Tiến sĩ tại Đại học Rice, cho biết Q-Learning có thể không phải là bí mật để mở khóa AGI.
Nhưng kết hợp “dữ liệu tổng hợp” với “thuật toán học tăng cường hiệu quả dữ liệu” có thể là chìa khóa để thúc đẩy mô hình nghiên cứu AI hiện tại.
Ông nói rằng tinh chỉnh thông qua học tăng cường là bí quyết để đào tạo các mô hình lớn hiệu suất cao, chẳng hạn như ChatGPT / GPT-4. Tuy nhiên, học tăng cường vốn không hiệu quả về dữ liệu và rất tốn kém để tinh chỉnh việc học tăng cường bằng cách sử dụng các bộ dữ liệu được gắn nhãn thủ công bởi con người. Với suy nghĩ này, việc thúc đẩy nghiên cứu AI (ít nhất là trong mô hình hiện tại) sẽ phụ thuộc rất nhiều vào hai mục tiêu cơ bản:
- Làm cho việc học tăng cường hoạt động tốt hơn với ít dữ liệu hơn.
- Tổng hợp và tạo dữ liệu chất lượng cao bằng cách sử dụng các mô hình lớn và một lượng nhỏ dữ liệu được chú thích thủ công bất cứ khi nào có thể.
… Nếu chúng ta bám sát dự đoán của mô hình mã thông báo tiếp theo (tức là được đào tạo trước -> SFT -> RLHF) bằng cách sử dụng Biến áp chỉ dành cho Bộ giải mã… Sự kết hợp của hai phương pháp này sẽ giúp mọi người tiếp cận với các kỹ thuật đào tạo tiên tiến, không chỉ các nhóm nghiên cứu với nhiều tiền!
Một điều nữa
Chưa ai trong OpenAI trả lời tin nhắn của Q.
Nhưng Altman vừa tiết lộ rằng ông đã có một vài giờ trò chuyện thân thiện với người sáng lập Quora Adam D’Angelo, người vẫn còn trong hội đồng quản trị.
 Có vẻ như việc Adam D’Angelo có đứng sau vụ việc hay không, như mọi người đã suy đoán, hiện đã đạt được thỏa thuận.
Có vẻ như việc Adam D’Angelo có đứng sau vụ việc hay không, như mọi người đã suy đoán, hiện đã đạt được thỏa thuận.
Liên kết tham khảo:
[1]
[2]
[3]
[4]
[5]
[6]
