Джерело статті: qubits
 Джерело зображення: Створено Unbounded AI
Джерело зображення: Створено Unbounded AI
Драма палацових боїв OpenAI щойно закінчилася, і вона одразу викличе черговий галас!
Агентство Reuters повідомило, що перед звільненням Альтмана кілька дослідників написали попереджувальні листи раді директорів, які, можливо, спровокували весь інцидент:
Модель штучного інтелекту наступного покоління, внутрішня назва Q (вимовляється як Q-Star), занадто потужна і просунута, щоб загрожувати людству.
Q* очолює центральна фігура цього шторму, головний науковий співробітник Ілля Суцкевер.
Люди швидко пов’язали попередні виступи Альтмана на саміті АТЕС:
В історії OpenAI було чотири рази, востаннє за останні кілька тижнів, коли я був у кімнаті, коли ми пробивалися крізь завісу невігластва та досягали межі відкриттів, що було найвищою честю в моїй кар’єрі. "
 Q* може мати такі основні характеристики, які вважаються ключовим кроком на шляху до AGI або суперінтелекту.
Q* може мати такі основні характеристики, які вважаються ключовим кроком на шляху до AGI або суперінтелекту.
- Подолати обмеження людських даних і самостійно створювати величезні обсяги навчальних даних
- Здатність самостійно навчатися та вдосконалюватися
Ця новина швидко викликала величезну дискусію, і Маск також запитав із посиланням.
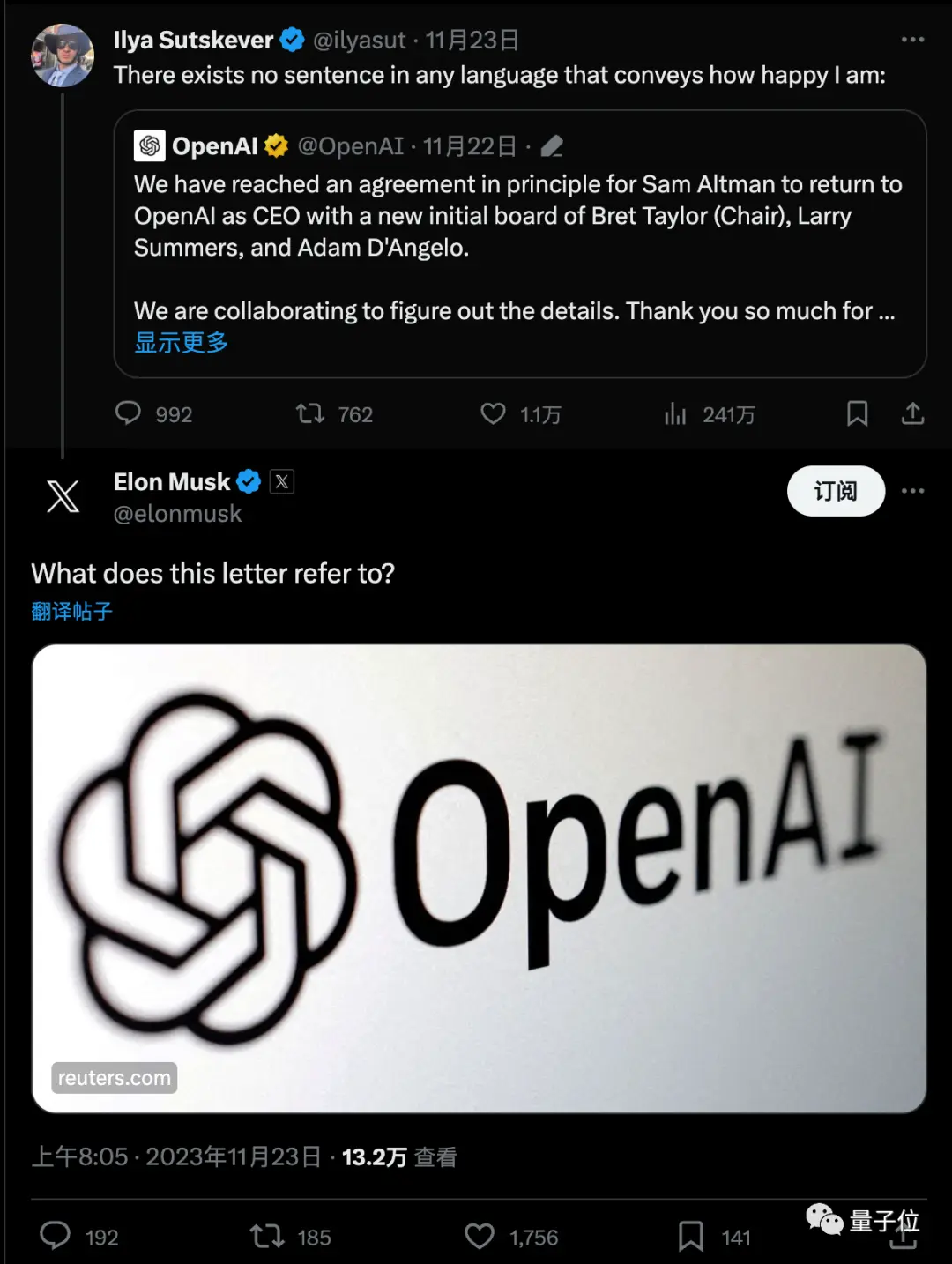 Останній мем полягає в тому, що, здавалося б, за одну ніч люди перетворилися з експертів у раді директорів Ultraman та OpenAI на експертів Q*.
Останній мем полягає в тому, що, здавалося б, за одну ніч люди перетворилися з експертів у раді директорів Ultraman та OpenAI на експертів Q*.

Порушення лімітів даних
Згідно з останніми новинами The Information, Q’* раніше був відомий як GPT-Zero, проєкт, ініційований Іллею Суцкевером, з назвою, яка віддає данину поваги Alpha-Zero від DeepMind.
Альфа-Зеро не потрібно вивчати людські шахові партії, а він вчиться грати в го, граючи проти самого себе.
GPT-Zero дозволяє навчати моделі штучного інтелекту наступного покоління, використовуючи синтетичні дані, а не покладатися на реальні дані, такі як текст або зображення, витягнуті з Інтернету.
У 2021 році GPT-Zero був офіційно створений, і з того часу було не так багато новин, безпосередньо пов’язаних із цим.
Але буквально кілька тижнів тому Ілля згадав в інтерв’ю:
Не вдаючись у подробиці, я просто хочу сказати, що обмеження даних можна подолати, і прогрес триватиме.
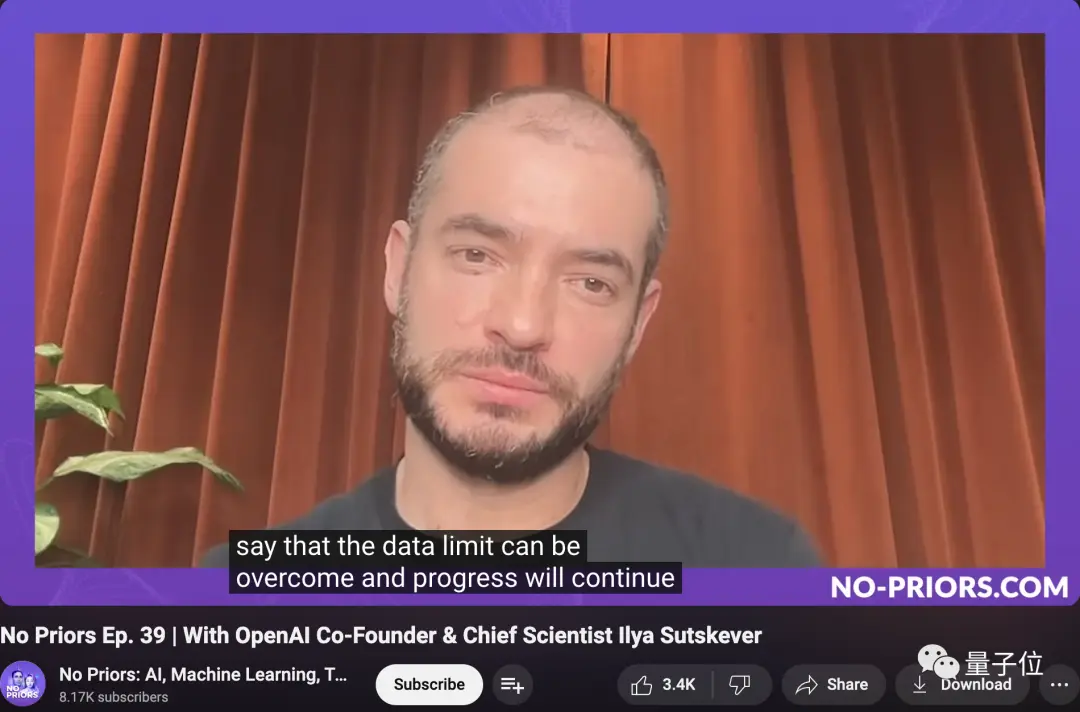 На основі GPT-Zero Q* був розроблений Якубом Пачоцьким та Шимоном Сидором.
На основі GPT-Zero Q* був розроблений Якубом Пачоцьким та Шимоном Сидором.
Обидва вони були ранніми членами OpenAI, а також першими членами, які оголосили, що підуть слідом за Ultraman до Microsoft.
 Якуб Пачоцький, якого минулого місяця підвищили до директора з досліджень, був основним учасником багатьох його минулих проривів, включаючи проєкт Dota 2 та попереднє навчання GPT-4.
Якуб Пачоцький, якого минулого місяця підвищили до директора з досліджень, був основним учасником багатьох його минулих проривів, включаючи проєкт Dota 2 та попереднє навчання GPT-4.
 Шимон Сидор також працював над проектом Dota 2, а його біографія – «побудова AGI, рядок за рядком».
Шимон Сидор також працював над проектом Dota 2, а його біографія – «побудова AGI, рядок за рядком».
 У повідомленні Reuters згадувалося, що Q* отримав величезні обчислювальні ресурси, щоб мати можливість вирішувати певні математичні завдання. Хоча нинішні математичні здібності є лише на рівні початкової школи, дослідники дуже оптимістично дивляться на майбутні успіхи.
У повідомленні Reuters згадувалося, що Q* отримав величезні обчислювальні ресурси, щоб мати можливість вирішувати певні математичні завдання. Хоча нинішні математичні здібності є лише на рівні початкової школи, дослідники дуже оптимістично дивляться на майбутні успіхи.
Крім того, було згадано, що OpenAI створила нову команду «вчених зі штучного інтелекту», яка є злиттям двох команд «Code Gen» і «Math Gen» у перші дні, і досліджує та оптимізує, щоб покращити здатність ШІ міркувати, і зрештою провести наукові дослідження.
Три припущення
Більше немає конкретних слів про те, що таке Q*, але деякі припускають з назви, що це може мати якесь відношення до Q-Learning.
Q-Learning, який бере свій початок з 1989 року, є безмодельним алгоритмом навчання з підкріпленням, який не вимагає моделювання середовища навіть для передавальних функцій з випадковими факторами або функціями винагороди, і може бути адаптований без особливих змін.
На відміну від інших алгоритмів навчання з підкріпленням, Q-Learning фокусується на вивченні цінності кожної пари стан-дія, щоб вирішити, яка дія принесе найбільшу віддачу в довгостроковій перспективі, а не безпосередньо вивчає саму стратегію дій.
Друге припущення пов’язане з випуском OpenAI у травні про те, що він вирішує математичні проблеми за допомогою «нагляду за процесами», а не «нагляду за результатами».
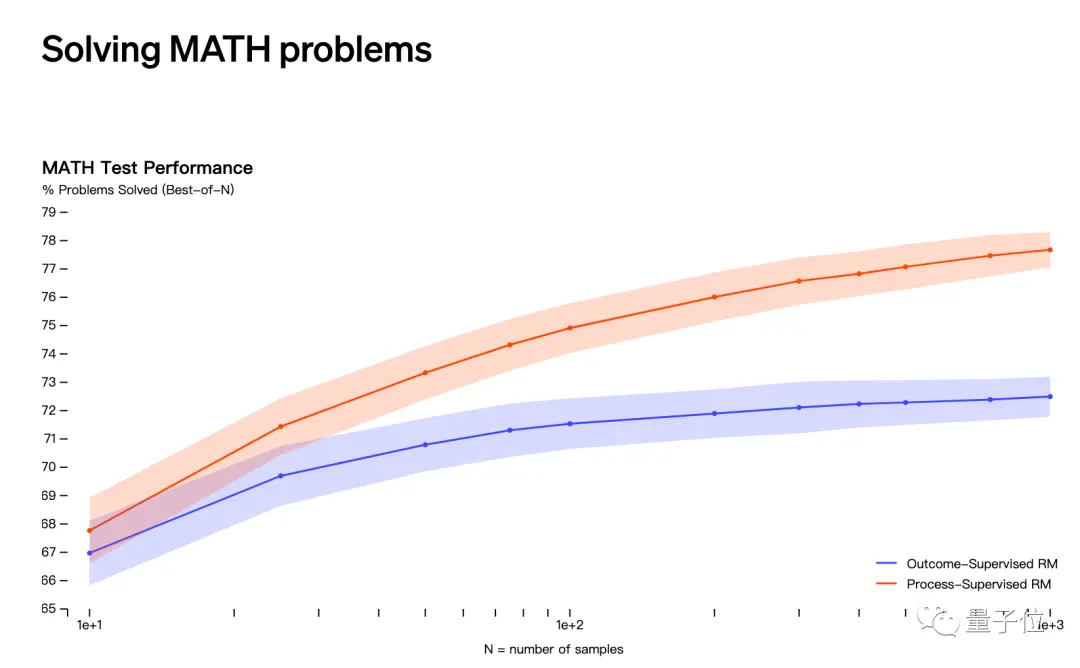 Однак імена Якуба Пачоцького та Шимона Сидора не фігурують у списку учасників цього дослідження.
Однак імена Якуба Пачоцького та Шимона Сидора не фігурують у списку учасників цього дослідження.
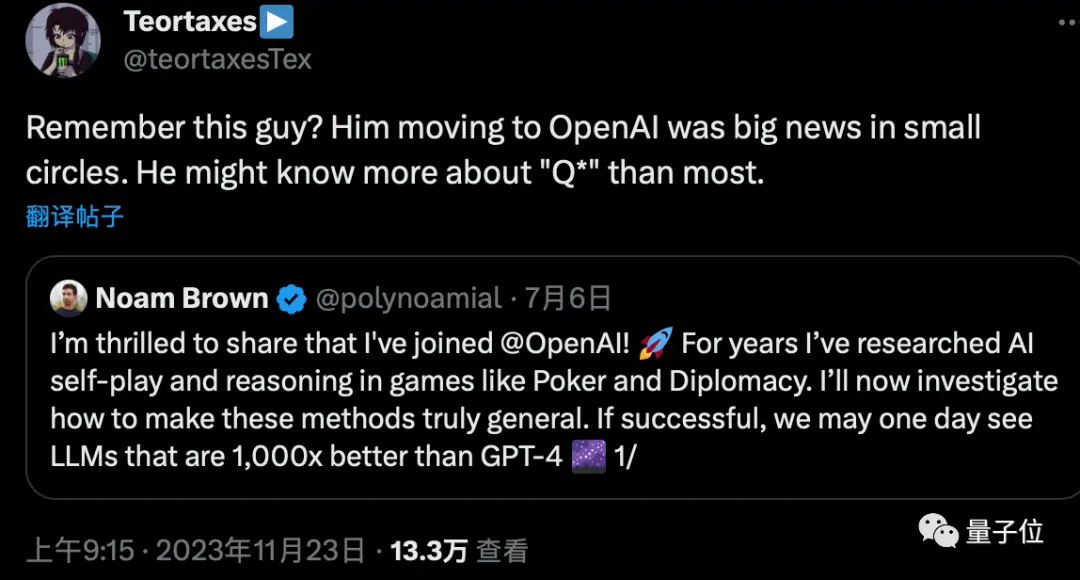
 Також є припущення, що Ноам Браун, «батько Depo AI», який приєднався до OpenAI у липні, також може бути залучений до проєкту.
Також є припущення, що Ноам Браун, «батько Depo AI», який приєднався до OpenAI у липні, також може бути залучений до проєкту.
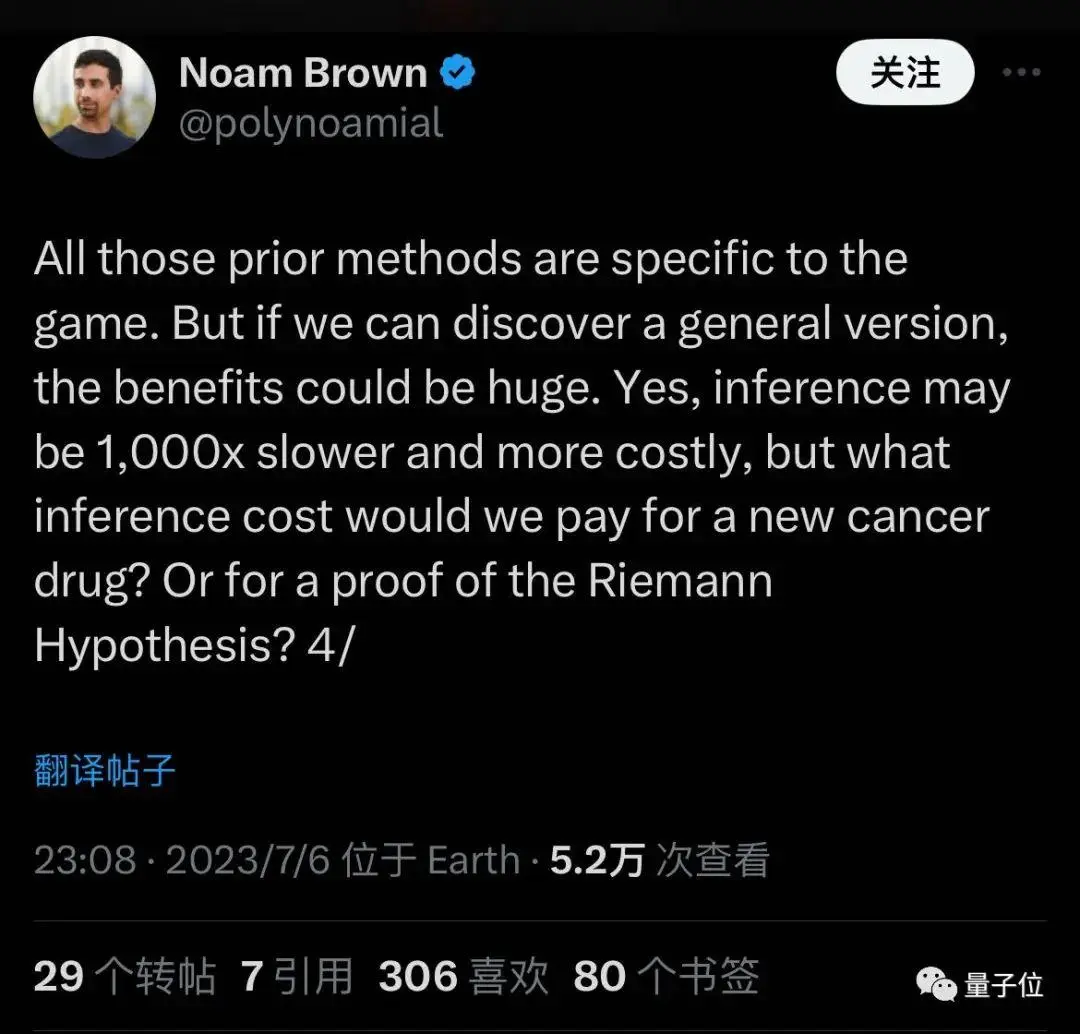
 Коли він приєднався, він сказав, що хоче узагальнити методи, які раніше були застосовні тільки до ігор, і що міркування можуть бути в 1000 разів повільнішими і дорожчими, але можуть відкрити нові ліки або довести математичні гіпотези.
Коли він приєднався, він сказав, що хоче узагальнити методи, які раніше були застосовні тільки до ігор, і що міркування можуть бути в 1000 разів повільнішими і дорожчими, але можуть відкрити нові ліки або довести математичні гіпотези.
Це узгоджується з чутками про «вимогу величезних обчислювальних ресурсів» і «здатність вирішувати певні математичні завдання».
 Хоча все ще робляться додаткові припущення, питання про те, чи можуть синтетичні дані та навчання з підкріпленням вивести штучний інтелект на новий рівень, стало однією з найбільш обговорюваних тем у галузі.
Хоча все ще робляться додаткові припущення, питання про те, чи можуть синтетичні дані та навчання з підкріпленням вивести штучний інтелект на новий рівень, стало однією з найбільш обговорюваних тем у галузі.
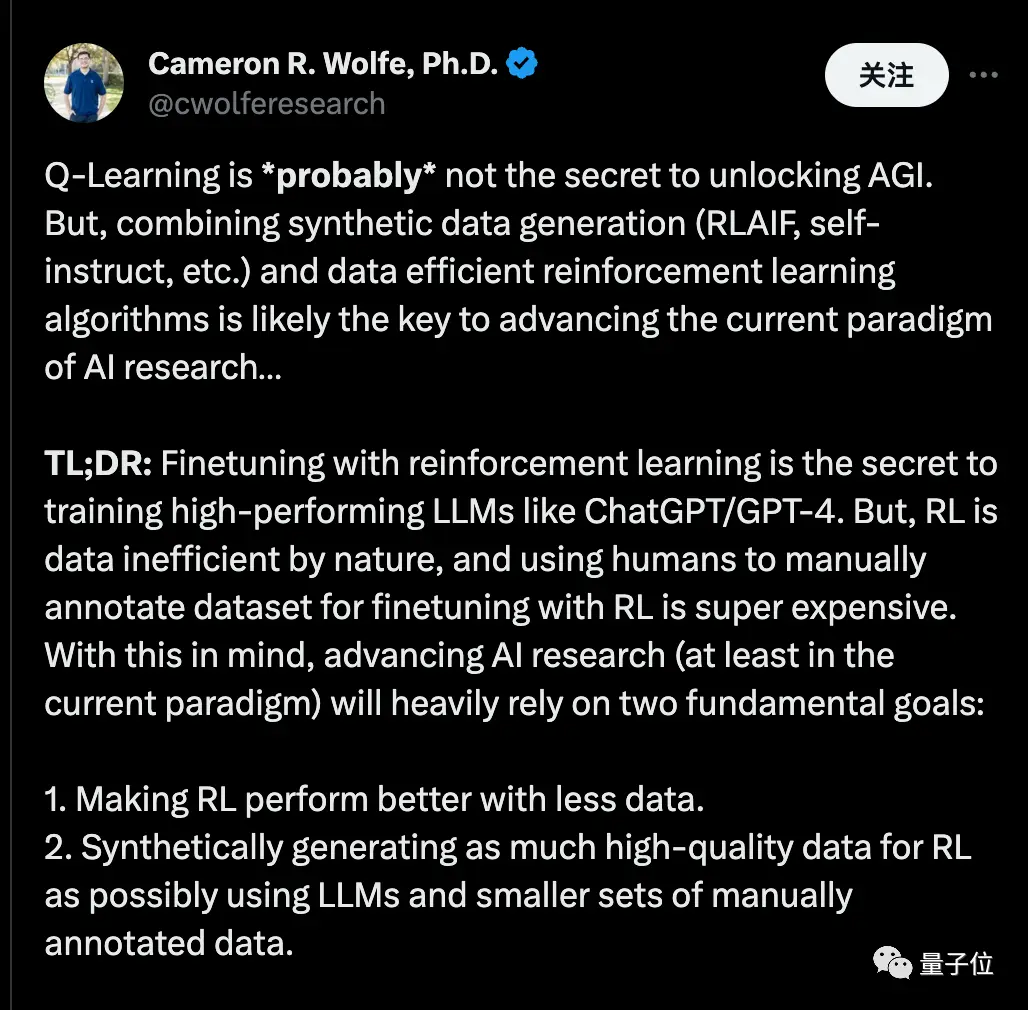
Вчений Nvidia Фань Ліньсі вважає, що синтетичні дані забезпечать трильйони високоякісних навчальних токенів, і ключове питання полягає в тому, як зберегти якість і уникнути передчасного потрапляння в вузькі місця.
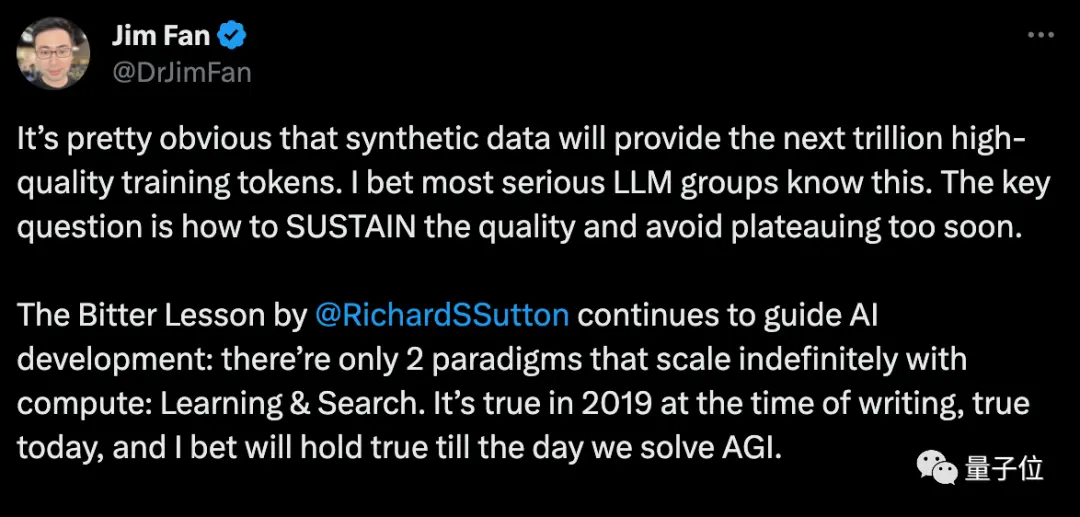 Маск погоджується, зазначаючи, що кожна книга, написана людиною, може поміститися на жорсткому диску, а синтетичні дані будуть далеко за межами цього.
Маск погоджується, зазначаючи, що кожна книга, написана людиною, може поміститися на жорсткому диску, а синтетичні дані будуть далеко за межами цього.
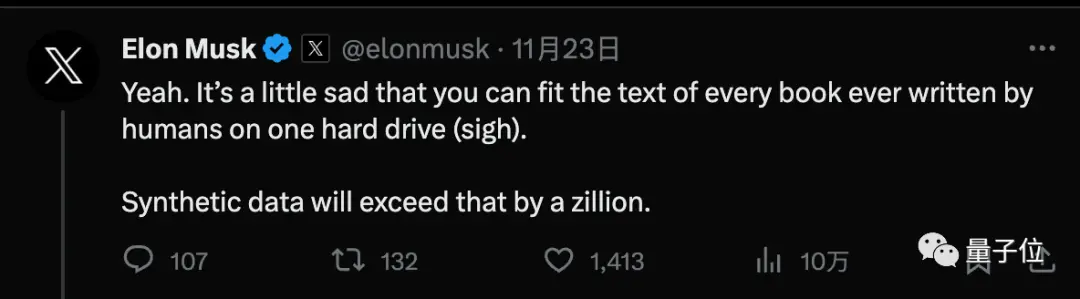 Але Лекун, один з тріумвіратів премії Тюрінга, стверджує, що більша кількість синтетичних даних є тимчасовим заходом, і що ШІ в кінцевому підсумку доведеться навчатися з дуже малою кількістю даних, так само, як людям або тваринам.
Але Лекун, один з тріумвіратів премії Тюрінга, стверджує, що більша кількість синтетичних даних є тимчасовим заходом, і що ШІ в кінцевому підсумку доведеться навчатися з дуже малою кількістю даних, так само, як людям або тваринам.
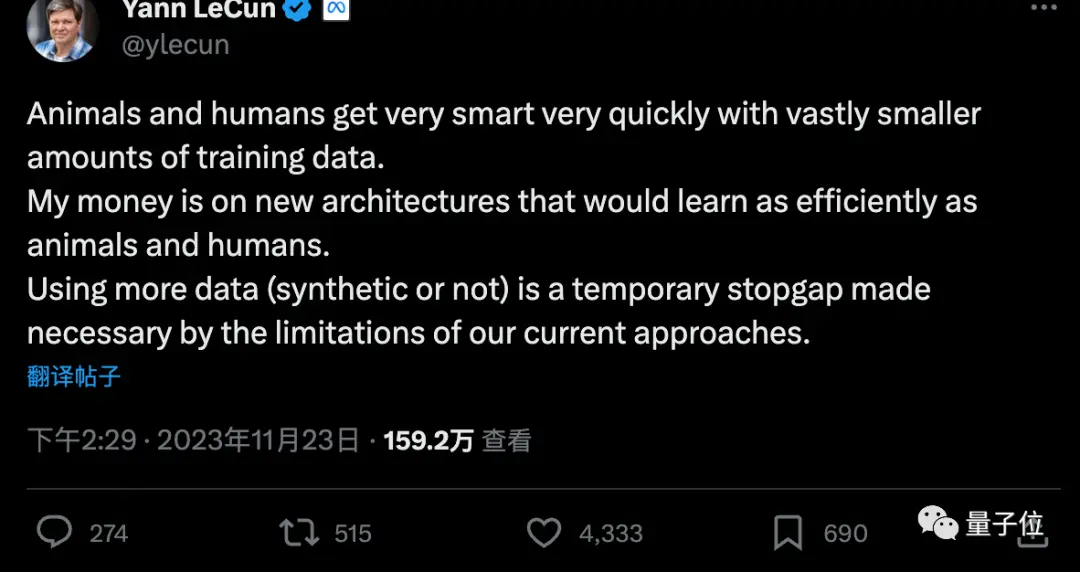 Кемерон Р. Вулф, доктор філософії в Університеті Райса, сказав, що Q-Learning, можливо, не є секретом розблокування AGI.
Кемерон Р. Вулф, доктор філософії в Університеті Райса, сказав, що Q-Learning, можливо, не є секретом розблокування AGI.
Але поєднання «синтетичних даних» з «ефективними алгоритмами навчання з підкріпленням» може стати ключем до просування поточної дослідницької парадигми штучного інтелекту.
Він сказав, що тонке налаштування за допомогою навчання з підкріпленням є секретом навчання високопродуктивних великих моделей, таких як ChatGPT/GPT-4. Однак навчання з підкріпленням за своєю суттю є неефективним для даних, і дуже дорого налаштовувати навчання з підкріпленням, використовуючи вручну позначені людьми набори даних. З огляду на це, просування досліджень у галузі штучного інтелекту (принаймні в нинішній парадигмі) значною мірою залежатиме від двох фундаментальних цілей:
- Зробіть навчання з підкріпленням більш ефективним з меншою кількістю даних.
- Синтезуйте та генеруйте високоякісні дані, використовуючи великі моделі та невелику кількість анотованих вручну даних, коли це можливо.
… Якщо ми дотримуватимемося передбачення наступної парадигми токенів (тобто попередньо навченого -> SFT -> RLHF) за допомогою трансформатора лише з декодером… Поєднання цих двох методів надасть кожному доступ до передових методів навчання, а не лише дослідницьким командам із великими грошима!
Ще одне
Ніхто в OpenAI поки що не відповів на повідомлення Q.
Але Альтман щойно розповів, що провів кілька годин дружньої розмови із засновником Quora Адамом Д’Анджело, який залишився в раді директорів.
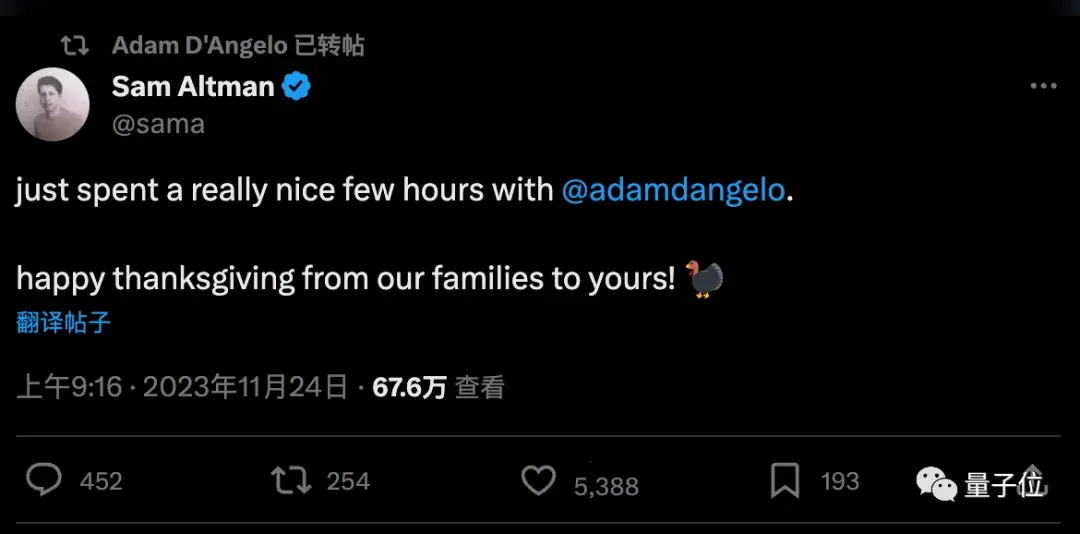 Схоже, що питання про те, чи стояв за цим інцидентом Адам Д’Анджело, як усі припускали, тепер досягло згоди.
Схоже, що питання про те, чи стояв за цим інцидентом Адам Д’Анджело, як усі припускали, тепер досягло згоди.
Посилання на джерела:
[1]
[2]
[3]
[4]
[5]
[6]
