Источник статьи: qubits
 Источник изображения: Сгенерировано Unbounded AI
Источник изображения: Сгенерировано Unbounded AI
Боевая драма во дворце OpenAI только что закончилась, и она сразу же вызовет новый шум!
Агентство Reuters сообщило, что перед тем, как Альтман был уволен, несколько исследователей написали предупредительные письма совету директоров, которые, возможно, спровоцировали весь инцидент:
Модель искусственного интеллекта следующего поколения, получившая внутреннее название Q (произносится как Q-Star), слишком мощная и продвинутая, чтобы угрожать человечеству.
Q* возглавляет центральная фигура этого шторма, главный научный сотрудник Илья Суцкевер.
Люди быстро связали предыдущие высказывания Альтмана на саммите АТЭС:
В истории OpenAI было четыре раза, последний раз за последние несколько недель, когда я был в комнате, когда мы прорвались сквозь завесу невежества и достигли рубежа открытий, что было высшей честью в моей карьере. "
 Q* может обладать следующими основными характеристиками, которые считаются ключевым шагом на пути к ОИИ, или сверхинтеллекту.
Q* может обладать следующими основными характеристиками, которые считаются ключевым шагом на пути к ОИИ, или сверхинтеллекту.
• Преодолейте ограничения человеческих данных и можете самостоятельно создавать огромные объемы обучающих данных
- Способность к обучению и самосовершенствованию
Новость быстро вызвала бурную дискуссию, и Маск тоже спросил со ссылкой.
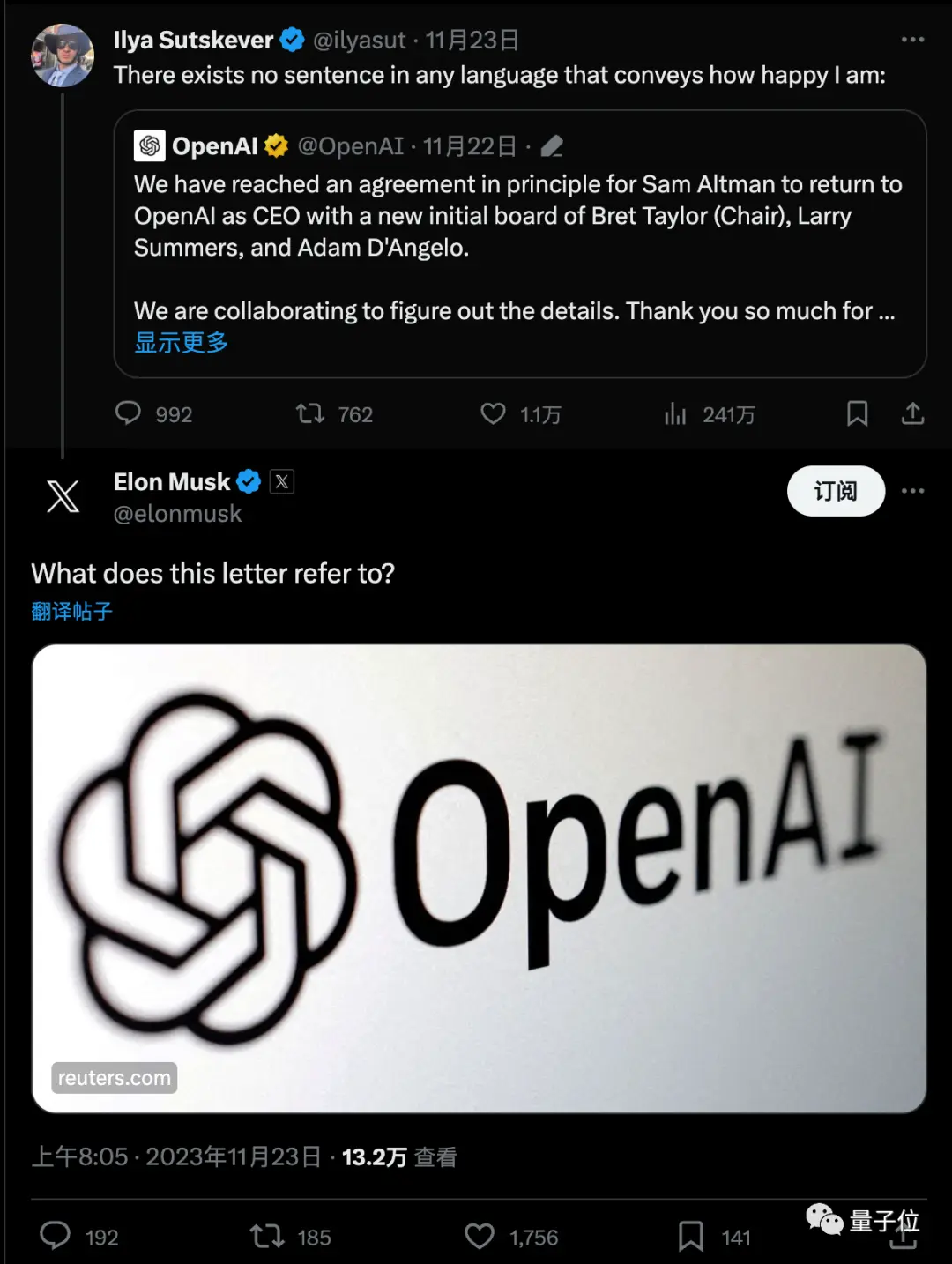 Последний мем заключается в том, что, казалось бы, в одночасье люди превратились из экспертов в совете директоров Ultraman и OpenAI в экспертов Q*.
Последний мем заключается в том, что, казалось бы, в одночасье люди превратились из экспертов в совете директоров Ultraman и OpenAI в экспертов Q*.

Превышение лимитов данных
Согласно последним новостям от The Information, Q’* ранее был известен как GPT-Zero, проект, инициированный Ильей Суцкевером, с названием, которое отдает дань уважения Alpha-Zero от DeepMind.
Альфа-Зеро не нужно изучать человеческие шахматные партии, он учится играть в Го, играя против самого себя.
GPT-Zero позволяет обучать модели ИИ следующего поколения с использованием синтетических данных вместо того, чтобы полагаться на реальные данные, такие как текст или изображения, извлеченные из Интернета.
В 2021 году GPT-Zero была официально учреждена, и с тех пор не было много новостей, связанных с ней.
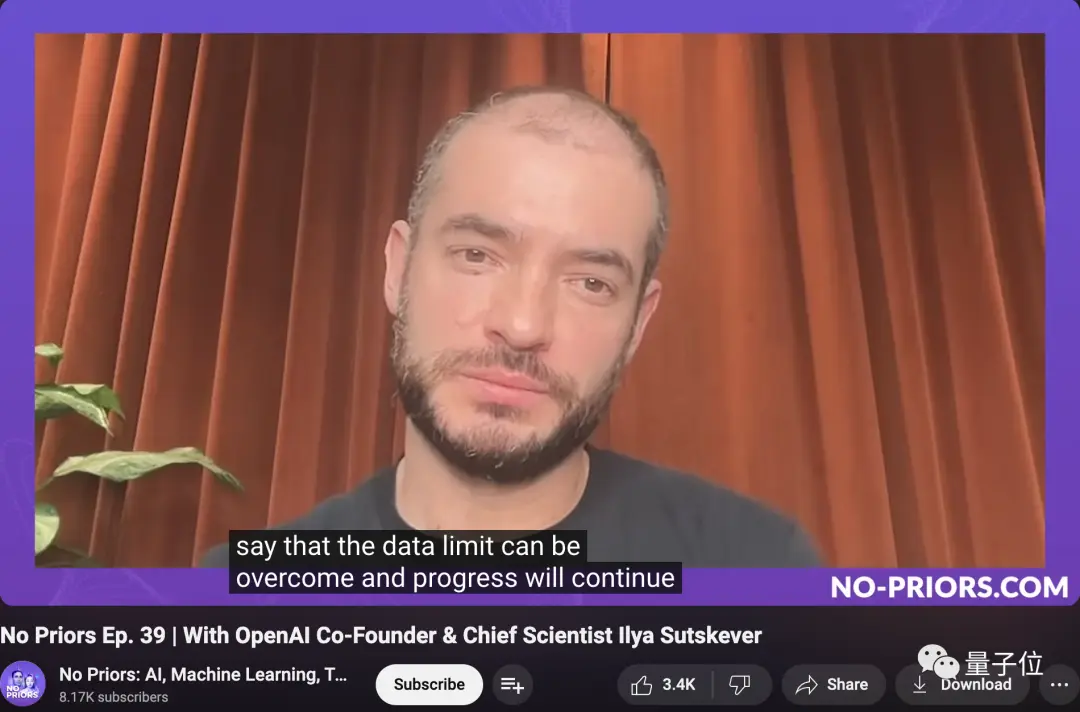
Но всего несколько недель назад Илья упомянул в интервью:
Не вдаваясь в подробности, скажу лишь, что ограничения данных можно преодолеть, и прогресс будет продолжаться.
 Основанный на GPT-Zero, Q* был разработан Якубом Пахоцки и Шимоном Сидором.
Основанный на GPT-Zero, Q* был разработан Якубом Пахоцки и Шимоном Сидором.
Оба они были первыми членами OpenAI, а также первыми, кто объявил, что последует за Ультраменом в Microsoft.
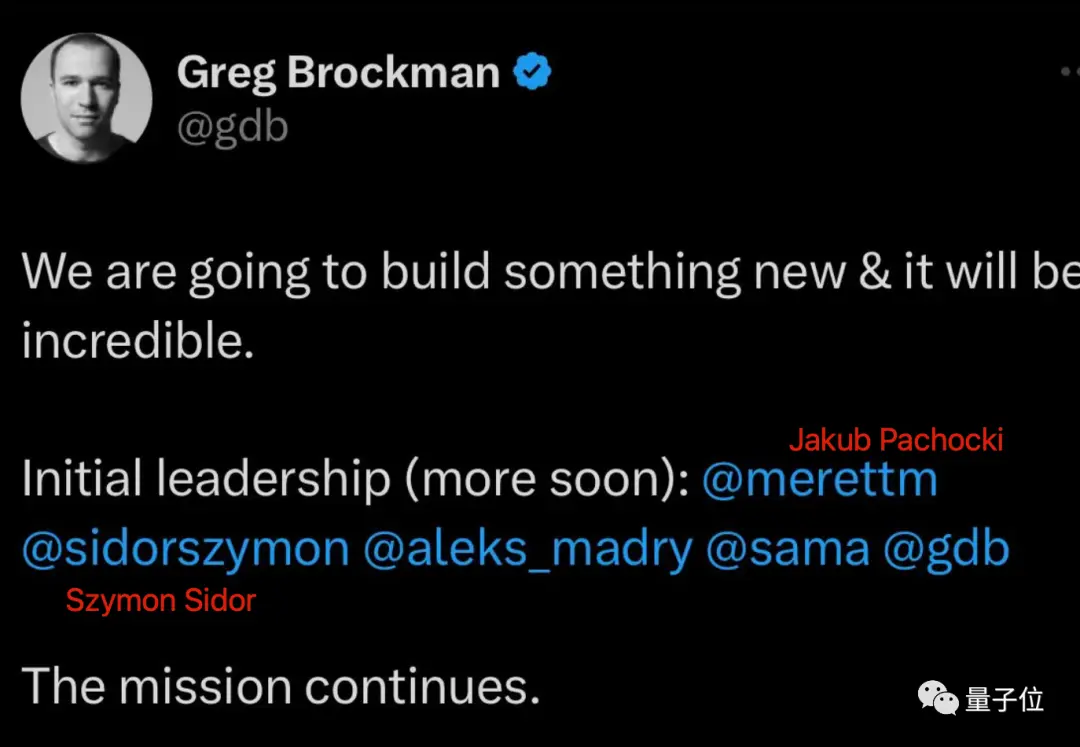 Якуб Пахоцки, который в прошлом месяце был назначен директором по исследованиям, внес основной вклад во многие из своих прошлых прорывов, включая проект Dota 2 и предварительную подготовку GPT-4.
Якуб Пахоцки, который в прошлом месяце был назначен директором по исследованиям, внес основной вклад во многие из своих прошлых прорывов, включая проект Dota 2 и предварительную подготовку GPT-4.
 Шимон Сидор также работал над проектом Dota 2, и его биография звучит так: «Строим AGI, строка за строкой».
Шимон Сидор также работал над проектом Dota 2, и его биография звучит так: «Строим AGI, строка за строкой».
 В сообщении Reuters упоминалось, что Q* получил огромные вычислительные ресурсы для решения определенных математических задач. Несмотря на то, что в настоящее время математические способности находятся только на уровне начальной школы, исследователи очень оптимистично настроены в отношении будущих успехов.
В сообщении Reuters упоминалось, что Q* получил огромные вычислительные ресурсы для решения определенных математических задач. Несмотря на то, что в настоящее время математические способности находятся только на уровне начальной школы, исследователи очень оптимистично настроены в отношении будущих успехов.
Кроме того, было упомянуто, что OpenAI создала новую команду «ученых ИИ», которая представляет собой слияние двух команд «Code Gen» и «Math Gen» в первые дни, и изучает и оптимизирует для улучшения способности ИИ к рассуждению и, в конечном итоге, проведения научных исследований.
Три догадки
Нет более конкретного слова о том, что именно представляет собой Q*, но некоторые предположили, что, исходя из названия, это может иметь какое-то отношение к Q-Learning.
Q-Learning, который ведет свою историю с 1989 года, представляет собой безмодельный алгоритм обучения с подкреплением, который не требует моделирования среды, даже для передаточных функций со случайными факторами или функциями вознаграждения, и может быть адаптирован без специальных изменений.
В отличие от других алгоритмов обучения с подкреплением, Q-Learning фокусируется на изучении значения каждой пары состояние-действие, чтобы решить, какое действие принесет наибольшую отдачу в долгосрочной перспективе, а не непосредственно на изучении самой стратегии действия.
Вторая догадка связана с майским релизом OpenAI о том, что он решает математические задачи с помощью «контроля процесса», а не «контроля результатов».
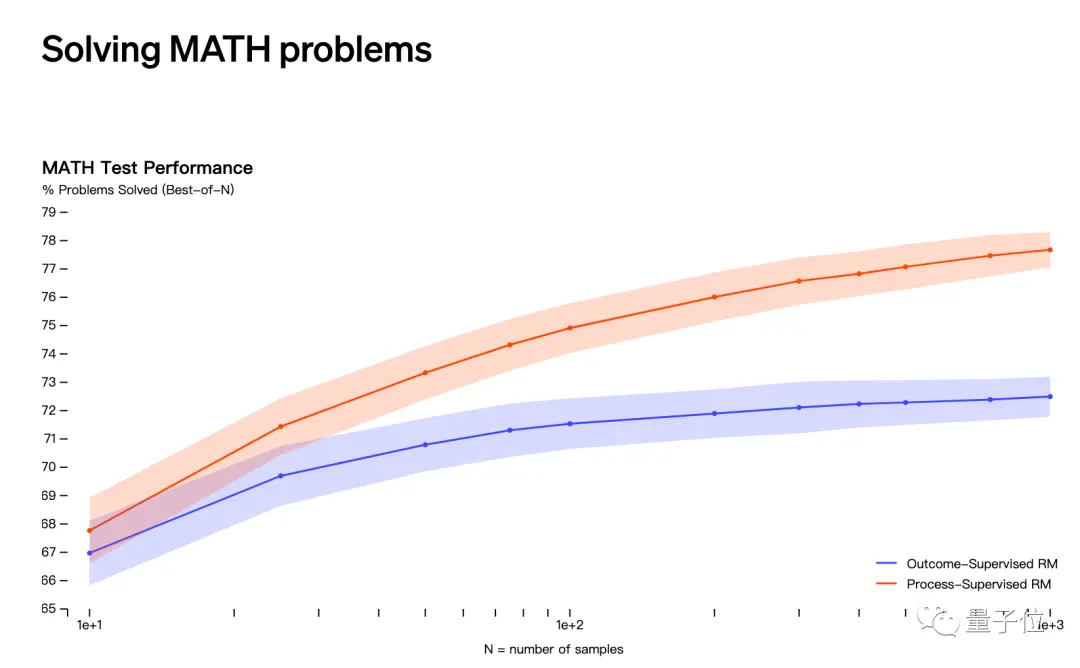 Тем не менее, имена Якуба Пахоцкого и Шимона Сидора не фигурируют в списке лиц, участвовавших в этом исследовании.
Тем не менее, имена Якуба Пахоцкого и Шимона Сидора не фигурируют в списке лиц, участвовавших в этом исследовании.
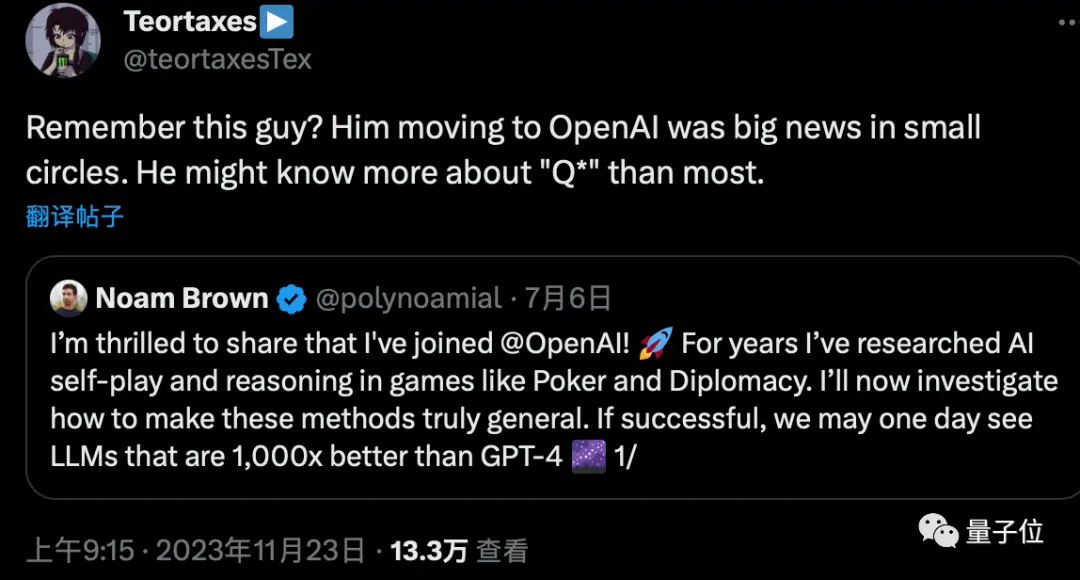
 Также есть предположение, что Ноам Браун, «отец Depo AI», который присоединился к OpenAI в июле, также может быть вовлечен в проект.
Также есть предположение, что Ноам Браун, «отец Depo AI», который присоединился к OpenAI в июле, также может быть вовлечен в проект.
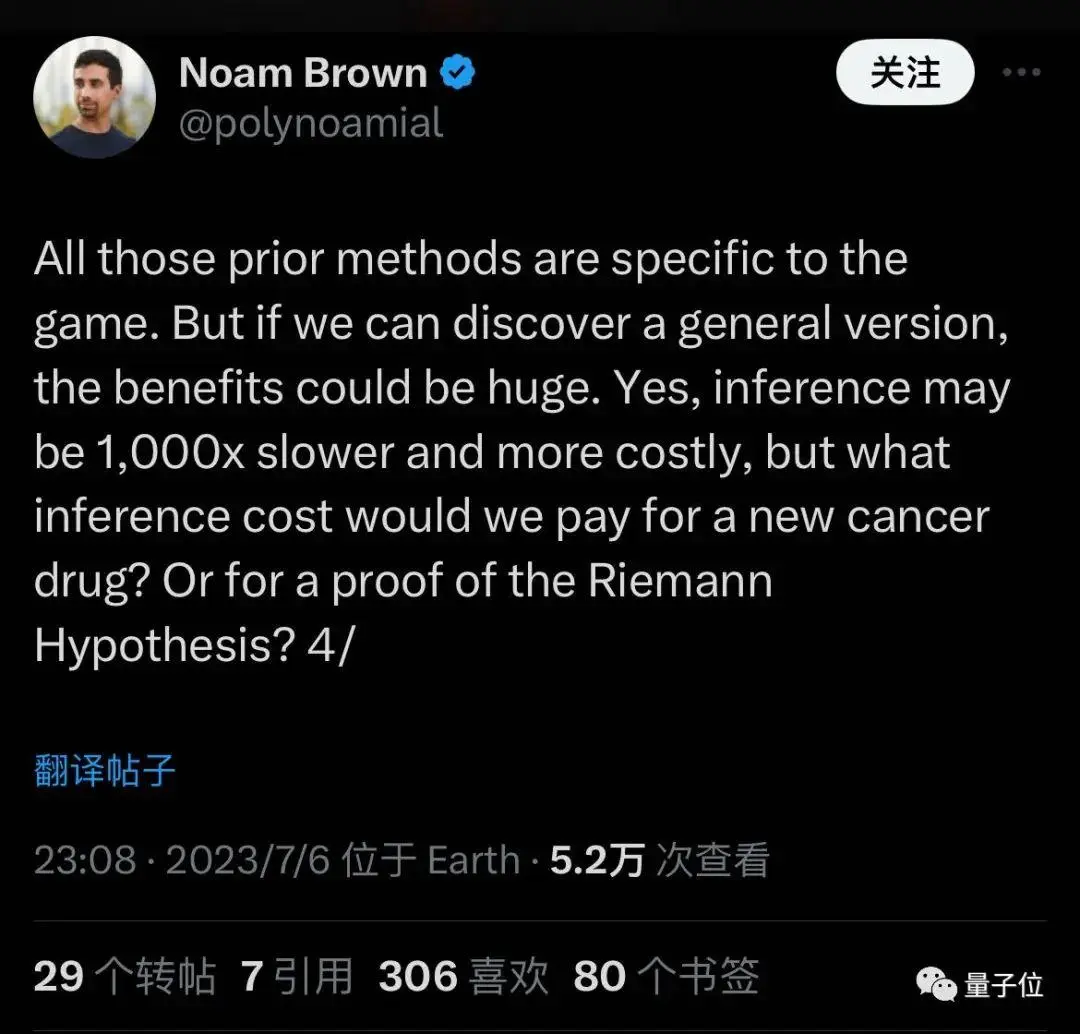
 Когда он присоединился, он сказал, что хочет обобщить методы, которые раньше были применимы только к играм, и что рассуждения могут быть в 1000 раз медленнее и дороже, но могут открыть новые лекарства или доказать математические гипотезы.
Когда он присоединился, он сказал, что хочет обобщить методы, которые раньше были применимы только к играм, и что рассуждения могут быть в 1000 раз медленнее и дороже, но могут открыть новые лекарства или доказать математические гипотезы.
Это соответствует слухам о «требовании огромных вычислительных ресурсов» и «способности решать определенные математические задачи».
 Несмотря на то, что все еще делаются предположения, вопрос о том, могут ли синтетические данные и обучение с подкреплением вывести ИИ на новый уровень, стал одной из самых обсуждаемых тем в отрасли.
Несмотря на то, что все еще делаются предположения, вопрос о том, могут ли синтетические данные и обучение с подкреплением вывести ИИ на новый уровень, стал одной из самых обсуждаемых тем в отрасли.
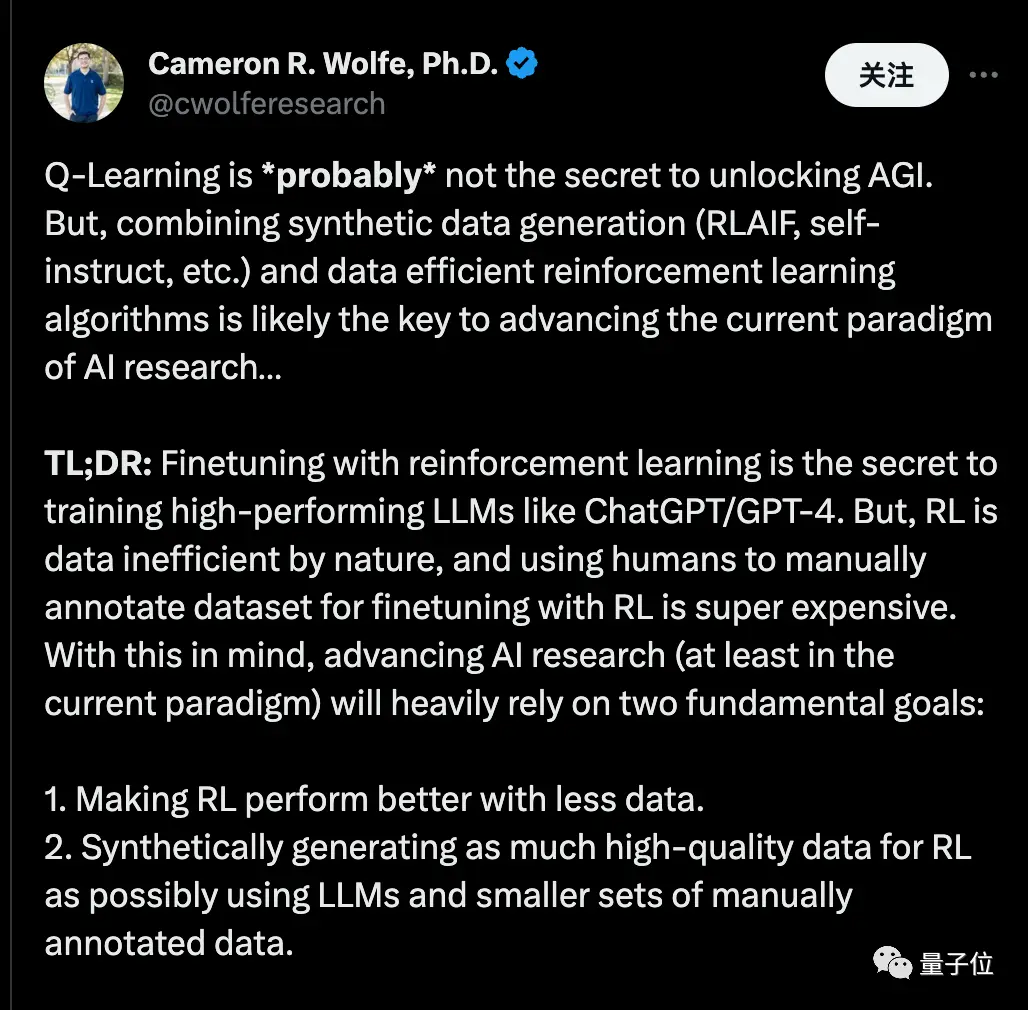
Ученый Nvidia Фань Линьси считает, что синтетические данные обеспечат триллионы качественных обучающих токенов, и ключевой вопрос заключается в том, как сохранить качество и избежать преждевременного попадания в узкие места.
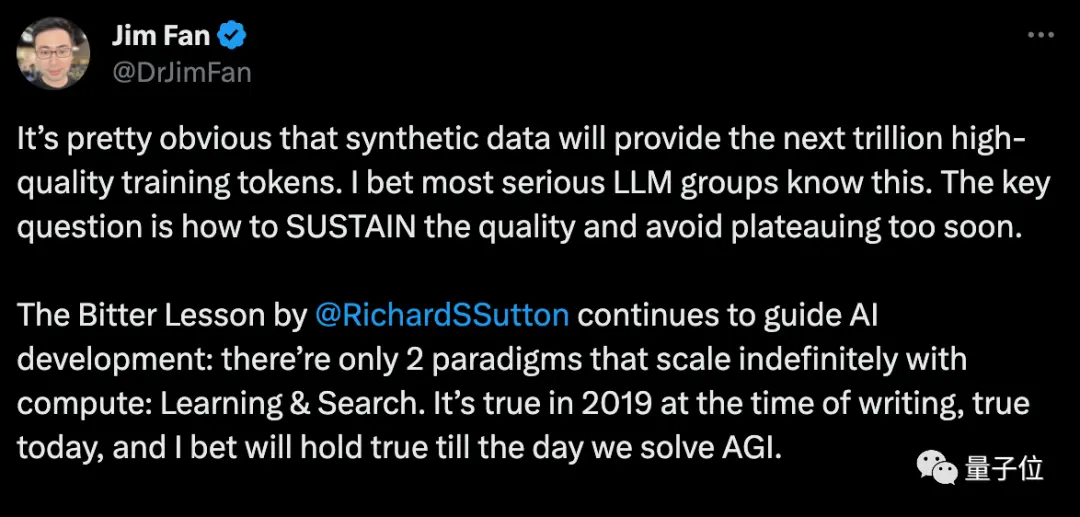 Маск соглашается, упоминая, что каждая книга, написанная человеком, может уместиться на жестком диске, а синтетические данные будут намного шире.
Маск соглашается, упоминая, что каждая книга, написанная человеком, может уместиться на жестком диске, а синтетические данные будут намного шире.
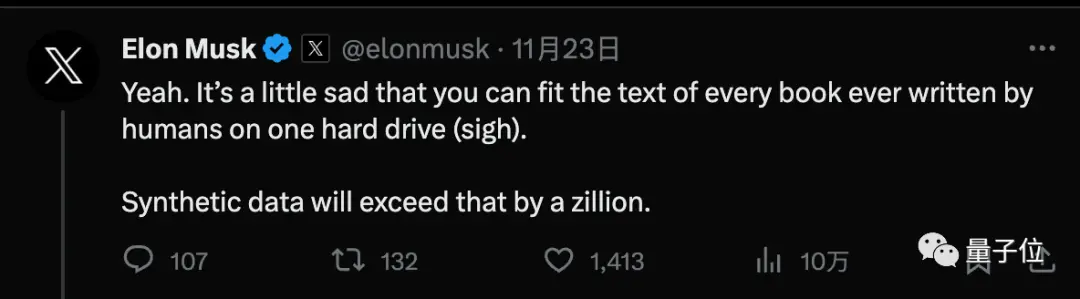 Но Лекун, один из триумвирата премии Тьюринга, утверждает, что больше синтетических данных — это временная мера, и что ИИ в конечном итоге придется учиться с очень небольшим количеством данных, как людям или животным.
Но Лекун, один из триумвирата премии Тьюринга, утверждает, что больше синтетических данных — это временная мера, и что ИИ в конечном итоге придется учиться с очень небольшим количеством данных, как людям или животным.
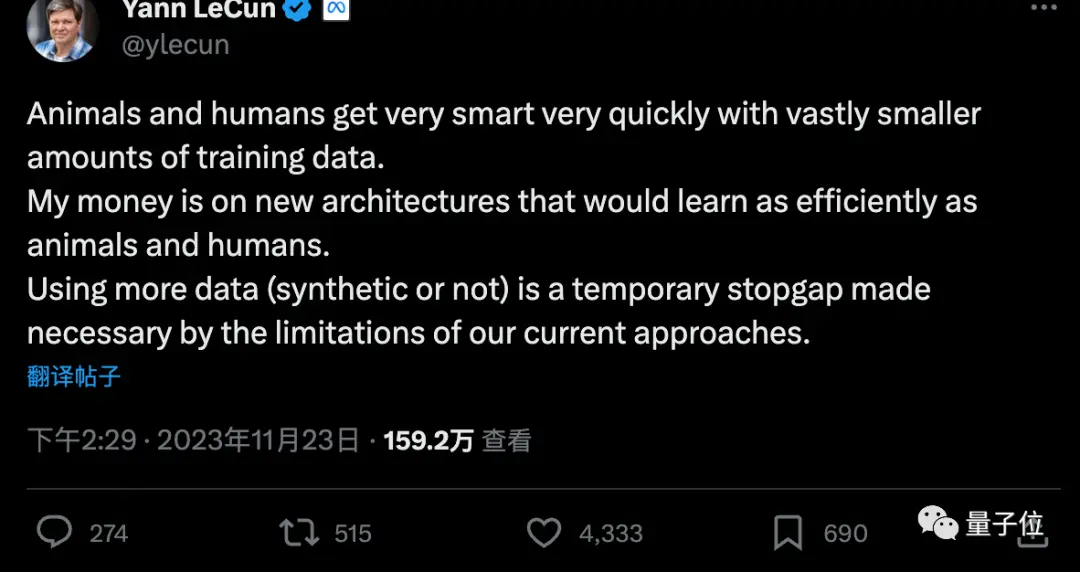 Кэмерон Р. Вулф, доктор философии из Университета Райса, сказал, что Q-Learning, возможно, не является секретом разблокировки AGI.
Кэмерон Р. Вулф, доктор философии из Университета Райса, сказал, что Q-Learning, возможно, не является секретом разблокировки AGI.
Но сочетание «синтетических данных» с «эффективными алгоритмами обучения с подкреплением» может стать ключом к продвижению текущей парадигмы исследований ИИ.
Он сказал, что тонкая настройка с помощью обучения с подкреплением является секретом обучения высокопроизводительных больших моделей, таких как ChatGPT/GPT-4. Тем не менее, обучение с подкреплением по своей сути неэффективно для работы с данными, и тонкая настройка обучения с подкреплением с использованием наборов данных, помеченных вручную людьми, обходится очень дорого. Имея это в виду, продвижение исследований в области ИИ (по крайней мере, в нынешней парадигме) будет в значительной степени зависеть от двух фундаментальных целей:
- Повышение эффективности обучения с подкреплением с меньшим количеством данных.
- Синтезируйте и генерируйте высококачественные данные, используя большие модели и небольшое количество аннотированных вручную данных, когда это возможно.
… Если мы будем придерживаться предсказания следующей парадигмы токенов (т.е. предварительно обученных -> SFT -> RLHF) с использованием Decoder-only Transformer… Комбинация этих двух методов даст доступ к передовым методам обучения всем, а не только исследовательским командам с большими деньгами!
И ещё кое-что
Никто в OpenAI пока не ответил на сообщение Q.
Но Альтман только что рассказал, что у него было несколько часов дружеской беседы с основателем Quora Адамом Д’Анджело, который остался в совете директоров.
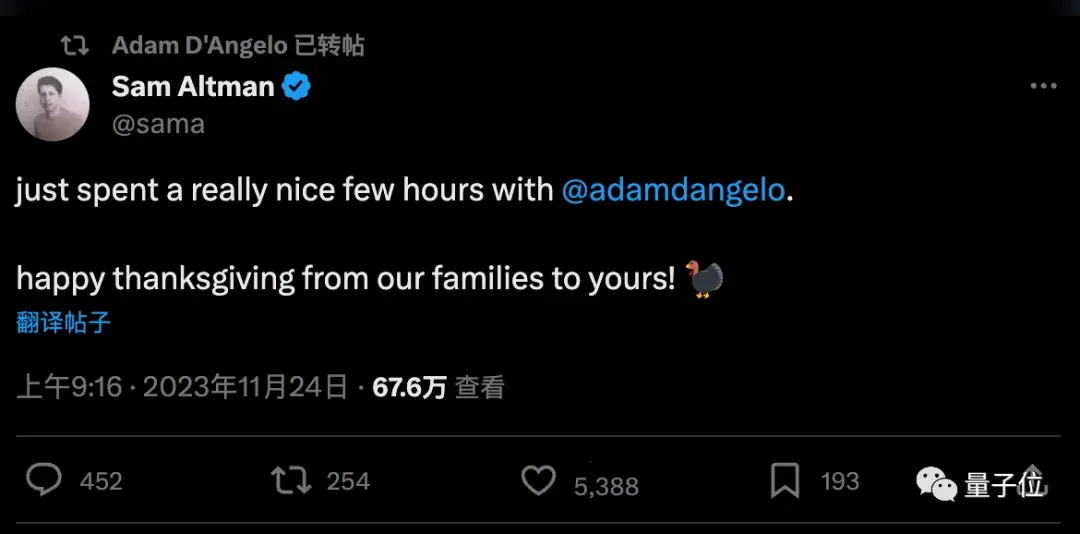 Похоже, что вопрос о том, стоял ли за инцидентом Адам Д’Анджело, как все предполагали, теперь достигнут урегулирование.
Похоже, что вопрос о том, стоял ли за инцидентом Адам Д’Анджело, как все предполагали, теперь достигнут урегулирование.
Ссылки:
[1]
[2]
[3]
[4]
[5]
[6]