Kernel Ventures : un article sur la DA et la conception de couches de données historiques
Par Jerry Luo, Kernel Ventures
TL ;DR
-
Au début, les chaînes publiques avaient besoin de nœuds sur le réseau pour maintenir la cohérence des données afin d’assurer la sécurité et la décentralisation. Cependant, avec le développement de l’écosystème blockchain, la pression de stockage continue d’augmenter, ce qui entraîne une tendance à la centralisation des opérations des nœuds. À ce stade, la couche 1 doit résoudre de toute urgence le problème de coût de stockage causé par la croissance du TPS.
-
Face à ce problème, les développeurs doivent proposer un nouveau schéma de stockage des données historiques en partant du principe de la prise en compte de la sécurité, du coût de stockage, de la vitesse de lecture des données et de la polyvalence de la couche DA.
-
Dans le processus de résolution de ce problème, de nombreuses nouvelles technologies et idées ont émergé, notamment le Sharding, le DAS, l’arbre de Verkle, les composants intermédiaires DA, etc. Ils ont essayé d’optimiser le schéma de stockage de la couche DA en réduisant la redondance des données et en améliorant l’efficacité de la vérification des données.
-
Du point de vue de l’emplacement de stockage des données, le système actuel d’AD est grossièrement divisé en deux catégories, à savoir l’AD de la chaîne principale et l’AD tierce. La DA de la chaîne principale est basée sur la perspective d’un nettoyage régulier des données et du partitionnement du stockage des données afin de réduire la pression de stockage sur les nœuds. Les exigences de conception des DA tiers sont conçues pour servir le stockage et disposent d’une solution raisonnable pour de grandes quantités de données. Par conséquent, il s’agit principalement d’un compromis entre la compatibilité mono-chaîne et la compatibilité multi-chaîne, et trois solutions sont proposées : DA dédiée à la chaîne principale, DA modulaire et DA à chaîne publique de stockage.
-
La chaîne publique basée sur le paiement a des exigences extrêmement élevées en matière de sécurité des données historiques, et il convient d’utiliser la chaîne principale comme couche DA. Cependant, pour les chaînes publiques qui fonctionnent depuis longtemps et qui font fonctionner le réseau par un grand nombre de mineurs, il est plus approprié d’adopter une DA tierce qui n’implique pas de couche consensuelle et prend en compte la sécurité. La chaîne publique complète est plus adaptée à l’utilisation d’un stockage DA dédié à la chaîne principale avec une plus grande capacité de données, un coût et une sécurité inférieurs. Mais compte tenu de la nécessité d’une chaîne croisée, le DA modulaire est également une bonne option.
-
En général, la blockchain se développe dans le sens de la réduction de la redondance des données et de la division du travail multi-chaînes.
1. arrière-plan
En tant que registre distribué, la blockchain doit stocker des données historiques sur tous les nœuds pour assurer la sécurité et la décentralisation du stockage des données. Étant donné que l’exactitude de chaque changement d’état est liée à l’état précédent (la source de la transaction), afin de garantir l’exactitude de la transaction, une blockchain devrait, en principe, stocker tout l’historique de la première transaction à la transaction en cours. Si l’on prend l’exemple d’Ethereum, même si la taille moyenne de chaque bloc est estimée à 20 ko, la taille totale du bloc Ethereum actuel a atteint 370 Go, et un nœud complet doit enregistrer l’état et les reçus de transaction en plus du bloc lui-même. En comptant cette partie, le volume de stockage total d’un seul nœud a dépassé 1 To, ce qui rend le fonctionnement du nœud concentré sur un petit nombre de personnes.
Dernière hauteur de bloc d’Ethereum, source de l’image : Etherscan
2. Indicateurs de performance de l’AD
2.1 Sécurité
Par rapport à la structure de stockage de la base de données ou de la liste chaînée, l’immuabilité de la blockchain provient du fait que les données nouvellement générées peuvent être vérifiées par le biais de données historiques, de sorte que la sécurité de ses données historiques est la première considération dans le stockage de la couche DA. Pour l’évaluation de la sécurité des données du système blockchain, nous analysons souvent la quantité de redondance des données et la méthode de vérification de la disponibilité des données
Nombre de redondance : Pour la redondance des données dans le système blockchain, il peut principalement jouer les rôles suivants : tout d’abord, si le nombre de redondance dans le réseau est plus important, lorsque le validateur a besoin de vérifier l’état du compte dans un bloc historique pour vérifier la transaction en cours, il peut obtenir le plus grand nombre d’échantillons pour référence, et sélectionner les données enregistrées par la majorité des nœuds. Dans les bases de données traditionnelles, comme les données ne sont stockées que sous forme de paires clé-valeur sur un certain nœud, le coût d’attaque est extrêmement faible pour modifier les données historiques sur un seul nœud, et théoriquement parlant, plus les données sont redondantes, plus les données sont crédibles. Dans le même temps, plus il y a de nœuds stockés, moins les données risquent d’être perdues. Cela peut également être comparé à des serveurs centralisés qui stockent des jeux Web2, et une fois que tous les serveurs backend sont arrêtés, il y aura un arrêt complet. Cependant, plus n’est pas mieux, car chaque redondance apportera de l’espace de stockage supplémentaire, et trop de redondance des données entraînera une pression de stockage excessive sur le système, et une bonne couche DA doit choisir une méthode de redondance appropriée pour trouver un équilibre entre la sécurité et l’efficacité du stockage.
Vérification de la disponibilité des données : la redondance garantit qu’il y a suffisamment d’enregistrements de données dans le réseau, mais les données à utiliser doivent également être vérifiées pour leur exactitude et leur exhaustivité. À ce stade, la méthode de vérification couramment utilisée dans la blockchain est l’algorithme d’engagement cryptographique, qui conserve un petit engagement cryptographique pour que l’ensemble du réseau l’enregistre, et cet engagement est obtenu en mélangeant les données de transaction. Pour tester l’authenticité d’une donnée historique, il est nécessaire de restaurer la promesse cryptographique à travers les données, de vérifier si la promesse cryptographique obtenue par la restauration est cohérente avec les enregistrements de l’ensemble du réseau, et si elle est cohérente, la vérification est réussie. Les algorithmes de vérification de mot de passe couramment utilisés sont Merkle Root et Verkle Root. L’algorithme de vérification de la disponibilité des données de haute sécurité ne nécessite que très peu de données de vérification et peut rapidement vérifier les données historiques.
2.2 Coûts de stockage
En partant du principe d’assurer la sécurité de base, le prochain objectif principal à atteindre dans la couche DA est de réduire les coûts et d’augmenter l’efficacité. La première consiste à réduire les coûts de stockage, c’est-à-dire à réduire l’empreinte mémoire causée par le stockage des données par unité de taille, sans tenir compte de la différence de performance matérielle. À ce stade, le principal moyen de réduire les coûts de stockage dans la blockchain est d’adopter la technologie de partitionnement et d’utiliser le stockage avec récompense pour s’assurer que les données sont stockées efficacement et réduire le nombre de sauvegardes de données. Cependant, il n’est pas difficile de voir à partir des méthodes d’amélioration ci-dessus qu’il existe une relation de jeu entre le coût du stockage et la sécurité des données, et la réduction de l’occupation du stockage signifie souvent une diminution de la sécurité. Par conséquent, une bonne couche DA doit trouver un équilibre entre le coût de stockage et la sécurité des données. En outre, si la couche DA est une chaîne publique distincte, il est également nécessaire de réduire le coût en minimisant le processus intermédiaire d’échange de données, et les données d’index doivent être laissées pour les appels de requête ultérieurs dans chaque processus de transit, de sorte que plus le processus d’appel est long, plus il reste de données d’index et plus le coût de stockage augmente. Enfin, le coût du stockage des données est directement lié à la pérennité des données. En général, plus le coût de stockage des données est élevé, plus il est difficile pour la chaîne publique de stocker les données de manière persistante.
2.3 Vitesse de lecture des données
Une fois la réduction des coûts réalisée, l’étape suivante consiste à gagner en efficacité, c’est-à-dire à appeler rapidement les données hors de la couche DA lorsqu’elles doivent être utilisées. Ce processus implique deux étapes, la première consiste à rechercher les nœuds qui stockent les données, ce processus est principalement destiné à la chaîne publique qui n’a pas atteint la cohérence des données de l’ensemble du réseau, si la chaîne publique a réalisé la synchronisation des données des nœuds de l’ensemble du réseau, la consommation de temps de ce processus peut être ignorée. Deuxièmement, dans les systèmes de blockchain traditionnels à ce stade, y compris Bitcoin, Ethereum et Filecoin, la méthode de stockage des nœuds est la base de données Leveldb. Dans Leveldb, les données sont stockées de trois manières. La première est que les données écrites à la volée sont stockées dans un fichier de type memtable, et lorsque le memtable est plein, le type de fichier passe de memtable à memtable immuable. Les deux types de fichiers sont stockés en mémoire, mais le fichier Memtable immuable ne peut plus être modifié et ne peut lire que les données qu’à partir de celui-ci. Le stockage à chaud utilisé dans le réseau IPFS stocke les données dans cette partie, et elles peuvent être lues rapidement à partir de la mémoire lorsqu’elles sont appelées, mais la mémoire mobile d’un nœud ordinaire est souvent au niveau du gigaoctet, ce qui est facile à écrire lentement, et lorsque le nœud tombe en panne et dans d’autres conditions anormales, les données de la mémoire seront définitivement perdues. Si vous souhaitez que vos données soient stockées de manière persistante, vous devez les stocker sous forme de fichier SST sur un disque SSD, mais vous devez d’abord lire les données en mémoire, ce qui ralentit considérablement la vitesse d’indexation des données. Enfin, pour les systèmes avec stockage partitionné, la restauration des données nécessite d’envoyer des requêtes de données à plusieurs nœuds et de les restaurer, ce qui ralentira également la vitesse de lecture des données.
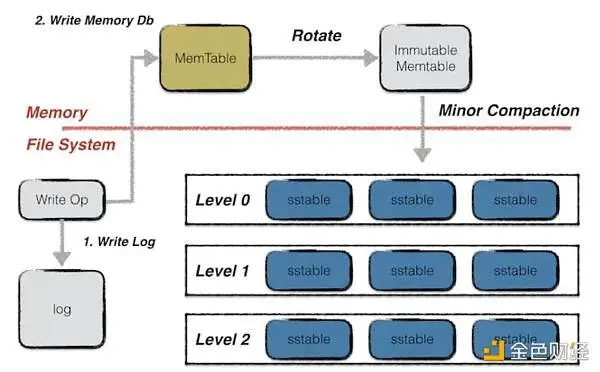
Méthode de stockage des données Leveldb, source de l’image : Leveldb-handbook
2.4 Similitude de la couche DA
Avec le développement de la DeFi et les problèmes des CEX, la demande de transactions inter-chaînes d’actifs décentralisés augmente également. Qu’il s’agisse d’un mécanisme cross-chain de verrouillage de hachage, notaire ou chaîne relais, il est inévitable de déterminer les données historiques sur les deux chaînes en même temps. Le nœud de ce problème réside dans la séparation des données sur les deux chaînes, et la communication directe ne peut pas être réalisée dans différents systèmes décentralisés. Par conséquent, à ce stade, une solution est proposée en changeant le mode de stockage de la couche DA, qui stocke les données historiques de plusieurs chaînes publiques sur la même chaîne publique de confiance, et n’a besoin d’appeler que les données de cette chaîne publique lors de la vérification. Cela nécessite que la couche DA soit capable d’établir une méthode de communication sécurisée avec différents types de chaînes publiques, c’est-à-dire que la couche DA a une bonne polyvalence.
3. Exploration des technologies liées à l’AD
3.1 Partitionnement
- Dans un système distribué traditionnel, un fichier n’est pas stocké sous une forme complète sur un nœud, mais les données d’origine sont divisées en plusieurs blocs et un bloc est stocké dans chaque nœud. Et les blocs ont tendance à ne pas être stockés sur un seul nœud, mais à avoir des sauvegardes appropriées sur d’autres nœuds, ce qui est généralement défini sur 2 dans les systèmes distribués grand public existants. Ce mécanisme de partitionnement permet de réduire la pression de stockage sur un seul nœud, d’étendre la capacité totale du système à la somme de la capacité de stockage de chaque nœud et d’assurer la sécurité du stockage grâce à une redondance appropriée des données. L’approche de sharding adoptée dans une blockchain est globalement similaire, mais il existe des différences dans les spécificités. Tout d’abord, étant donné que chaque nœud de la blockchain n’est pas fiable par défaut, une quantité suffisamment importante de données est nécessaire pour sauvegarder l’authenticité des données ultérieures dans le processus de mise en œuvre du Sharding, de sorte que le nombre de sauvegardes de ce nœud doit être bien supérieur à 2. Idéalement, dans un système blockchain avec ce schéma de stockage, si le nombre total de validateurs est T et le nombre de partitions est N, alors le nombre de sauvegardes devrait être T/N. La seconde est la procédure de stockage de Block, le système distribué traditionnel a moins de nœuds, il s’agit donc souvent d’un nœud pour s’adapter à plusieurs blocs de données, la première consiste à mapper les données à l’anneau de hachage via l’algorithme de hachage cohérent, puis chaque nœud stocke un certain nombre de blocs de données dans une certaine plage, et il peut être accepté qu’un nœud n’alloue pas de tâche de stockage dans un certain stockage. Sur la blockchain, l’affectation de chaque nœud à un bloc n’est plus un événement aléatoire mais un événement inévitable, et chaque nœud sélectionnera au hasard un bloc pour le stockage, ce qui est complété en calculant le nombre de partitions avec le résultat du hachage des données avec les données d’origine du bloc et les propres informations du nœud. En supposant que chaque élément de données est divisé en N blocs, la taille de stockage réelle de chaque nœud n’est que de 1/N de la taille d’origine. En définissant N de manière appropriée, il est possible d’atteindre un équilibre entre la croissance du TPS et la pression de stockage du nœud.
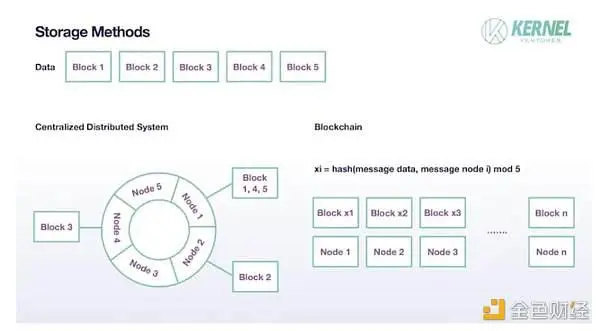
Comment les données sont stockées après le Sharding, source de l’image : Kernel Ventures
3.2 DAS (échantillonnage de la disponibilité des données)
La technologie DAS est basée sur l’optimisation du Sharding en termes de méthodes de stockage. Dans le processus de partitionnement, en raison du simple stockage aléatoire des nœuds, un certain bloc peut être perdu. Deuxièmement, pour les données partitionnées, il est également très important de savoir comment confirmer l’authenticité et l’intégrité des données pendant le processus de restauration. Dans DAS, ces deux problèmes sont résolus par le code Eraser et les engagements polynomiaux KZG.
Code de gomme : Compte tenu du grand nombre de validateurs sur Ethereum, la probabilité qu’un bloc ne soit stocké par aucun nœud est presque nulle, mais théoriquement, il existe toujours la possibilité qu’une telle situation extrême se produise. Afin d’atténuer cette menace possible de perte de stockage, au lieu de diviser directement les données d’origine en blocs pour le stockage, les données d’origine sont mappées aux coefficients d’un polynôme d’ordre n, puis 2n points sont pris sur le polynôme, et le nœud sélectionne au hasard l’un d’entre eux pour le stockage. Pour ce polynôme d’ordre n, seuls n+1 points sont nécessaires pour la restauration, de sorte que seule la moitié des blocs doivent être sélectionnés par les nœuds pour restaurer les données d’origine. Grâce au code Eraser, la sécurité du stockage des données et la capacité du réseau à récupérer les données sont améliorées.
Promesse polynomiale KZG : Une partie très importante du stockage des données est la vérification de l’authenticité des données. Dans les réseaux qui n’utilisent pas le code Eraser, il existe différentes façons de valider le processus, mais si le code Eraser ci-dessus est introduit pour améliorer la sécurité des données, il est plus approprié d’utiliser des engagements polynomiaux KZG. Le polynôme KZG promet de vérifier directement le contenu d’un seul bloc sous forme de polynômes, éliminant ainsi le besoin de restaurer les polynômes en données binaires, et la forme de vérification est généralement similaire à celle de l’arbre de Merkle, mais aucune donnée de nœud de chemin spécifique n’est requise, seules les données de racine et de bloc KZG sont nécessaires pour vérifier son authenticité.
3.3 Mode de vérification des données de la couche DA
La validation des données permet de s’assurer que les données appelées à partir du nœud n’ont pas été altérées et n’ont pas été perdues. Afin de réduire autant que possible la quantité de données et le coût de calcul requis dans le processus de vérification, la couche DA adopte actuellement l’arborescence comme méthode de vérification principale. La forme la plus simple consiste à utiliser l’arbre de Merkle pour la vérification, qui est enregistré sous la forme d’un arbre binaire complet, et n’a besoin que de conserver une racine de Merkle et la valeur de hachage de la sous-arborescence de l’autre côté du chemin du nœud à vérifier, et la complexité temporelle de la vérification est de niveau O(logN) (logN par défaut est log2(N) si le nombre n’est pas basé). Bien que le processus de validation ait été grandement simplifié, la quantité de données dans le processus de validation a généralement augmenté avec l’augmentation des données. Afin de résoudre le problème de l’augmentation de la quantité de vérification, une autre méthode de vérification, Verkle Tree, est proposée à ce stade. En plus de stocker de la valeur, chaque nœud de l’arbre de Verkle sera également livré avec un engagement vectoriel, grâce à la valeur du nœud d’origine et à cette preuve d’engagement, vous pouvez rapidement vérifier l’authenticité des données, sans appeler la valeur des autres nœuds frères, ce qui fait que le nombre de calculs pour chaque vérification n’est lié qu’à la profondeur de l’arbre de verkle, qui est une constante fixe, accélérant ainsi considérablement la vitesse de vérification. Cependant, le calcul de l’engagement vectoriel nécessite la participation de tous les nœuds frères de la même couche, ce qui augmente considérablement le coût d’écriture et de modification des données. Cependant, pour les données historiques, qui sont stockées en permanence et ne peuvent pas être altérées, Verkle Tree est extrêmement approprié. En outre, il existe également des variantes de l’arbre de Merkle et de l’arbre de Verkle sous la forme de K-ary, et leur mécanisme d’implémentation spécifique est similaire, mais le nombre de sous-arbres sous chaque nœud est modifié, et la comparaison de leurs performances spécifiques peut être vue dans le tableau suivant.
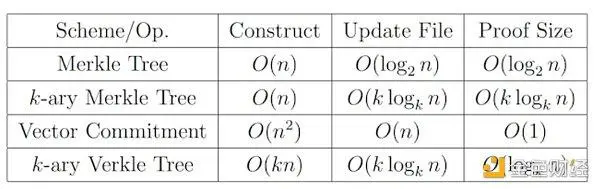
Comparaison des méthodes de vérification des données et des performances temporelles, source de l’image : Verkle Trees
3.4 Intergiciel DA générique
L’expansion continue de l’écologie de la blockchain a entraîné une augmentation du nombre de chaînes publiques. En raison des avantages et de l’irremplaçabilité de chaque chaîne publique dans leurs domaines respectifs, il est presque impossible pour la chaîne publique de couche 1 de s’unifier dans un court laps de temps. Cependant, avec le développement de la DeFi et les problèmes des CEX, la demande d’actifs de trading inter-chaînes décentralisés augmente également. En conséquence, le stockage de données multi-chaînes de la couche DA, qui peut éliminer les problèmes de sécurité dans les échanges de données inter-chaînes, a reçu de plus en plus d’attention. Cependant, afin d’accepter les données historiques de différentes chaînes publiques, il est nécessaire que la couche DA fournisse un protocole décentralisé pour le stockage standardisé et la vérification des flux de données, tel que kvye, un middleware de stockage basé sur Arweave, qui prend l’initiative de capturer les données de la chaîne, et peut stocker toutes les données de la chaîne sous une forme standard à Arweave pour minimiser les différences dans le processus de transmission des données. D’un point de vue relatif, Layer2, qui se spécialise dans le stockage de données de la couche DA pour une certaine chaîne publique, interagit avec les données via des nœuds de partage internes, ce qui réduit le coût de l’interaction et améliore la sécurité, mais présente des limitations relativement importantes et ne peut fournir des services qu’à des chaînes publiques spécifiques.
4. Schéma de stockage de niveau DA
4.1 Chaîne principale DA
4.1.1 classe DankSharding
Il n’y a pas de nom défini pour ce type de schéma de stockage, et le représentant le plus important de ce type de schéma de stockage est DankSharding sur Ethereum, donc le schéma de type DankSharding est utilisé dans cet article. Ce type de solution utilise principalement les deux technologies de stockage DA mentionnées ci-dessus, le Sharding et le DAS. Tout d’abord, le partitionnement divise les données en parties appropriées, puis permet à chaque nœud d’extraire un bloc de données sous la forme d’un DAS pour le stockage. S’il y a suffisamment de nœuds sur l’ensemble du réseau, nous pouvons prendre un plus grand nombre de partitions N, de sorte que la pression de stockage de chaque nœud ne soit que de 1/N de l’original, afin d’obtenir N fois l’expansion globale de l’espace de stockage. Dans le même temps, afin de s’assurer qu’un bloc n’est stocké dans aucun bloc dans les cas extrêmes, DankSharding encode les données à l’aide d’un code d’effacement, et seule la moitié des données peut être entièrement restaurée. Enfin, le processus de validation des données utilise la structure de l’arbre de Verkle et l’engagement polynomial pour obtenir une validation rapide.
4.1.2 Stockage à court terme
L’un des moyens les plus simples de traiter les données pour DA sur la chaîne principale est de stocker les données historiques pendant une courte période. Essentiellement, la blockchain joue le rôle d’un registre public, réalisant des modifications du contenu du grand livre sous la prémisse de l’ensemble du réseau témoin, sans avoir besoin d’un stockage permanent. Si l’on prend l’exemple de Solana, bien que ses données historiques soient synchronisées avec Arweave, les nœuds du réseau principal ne conservent les données de transaction que pour les deux derniers jours. Sur la chaîne publique basée sur les enregistrements de compte, les données historiques de chaque moment conservent l’état final du compte sur la blockchain, ce qui est suffisant pour fournir une base de vérification pour le prochain moment de changement. Pour les projets ayant des besoins particuliers en matière de données avant cette période, ils peuvent les stocker sur d’autres chaînes publiques décentralisées ou par des tiers de confiance. Cela signifie que les personnes qui ont des besoins supplémentaires en matière de données doivent payer pour le stockage des données historiques.
4.2 DA tiers
4.2.1 DA dédié à la chaîne principale : EthStorage
DA pour la chaîne principale:D La chose la plus importante dans la couche A est la sécurité de la transmission des données, et la plus sûre à cet égard est la DA de la chaîne principale. Cependant, le stockage de la chaîne principale est limité par l’espace de stockage et la concurrence pour les ressources, de sorte que lorsque la quantité de données réseau augmente rapidement, si vous souhaitez obtenir un stockage à long terme des données, la DA tierce sera un meilleur choix. Si le DA tiers a une plus grande compatibilité avec le réseau principal, il peut réaliser le partage de nœuds et avoir une plus grande sécurité dans le processus d’échange de données. Par conséquent, en tenant compte de la sécurité, il y aura d’énormes avantages pour l’AD dédié à la chaîne principale. Si l’on prend l’exemple d’Ethereum, l’une des exigences de base de la DA dédiée à la chaîne principale est qu’elle puisse être compatible avec EVM pour assurer l’interopérabilité avec les données et les contrats Ethereum, et les projets représentatifs incluent Topia, EthStorage, etc. Parmi eux, EthStorage est actuellement le plus développé en termes de compatibilité, car en plus de la compatibilité au niveau EVM, il met également en place des interfaces pertinentes pour se connecter aux outils de développement Ethereum tels que Remix et Hardhat afin d’atteindre la compatibilité au niveau de l’outil de développement Ethereum.
EthStorage : EthStorage est une chaîne publique indépendante d’Ethereum, mais les nœuds qui s’exécutent dessus sont supérieurs aux nœuds Ethereum, c’est-à-dire que les nœuds exécutant EthStorage peuvent également exécuter Ethereum en même temps, et EthStorage peut être directement exploité via l’opcode sur Ethereum. Dans le modèle de stockage d’EthStorage, qui ne conserve qu’une petite quantité de métadonnées sur le réseau principal Ethereum pour l’indexation, crée essentiellement une base de données décentralisée pour Ethereum. Dans la solution actuelle, EthStorage a mis en œuvre l’interaction entre le réseau principal Ethereum et EthStorage en déployant un contrat EthStorage sur le réseau principal Ethereum. Si Ethereum veut déposer des données, il doit appeler la fonction put() dans le contrat, et les paramètres d’entrée sont deux variables d’octet clé, data, où data représente les données à déposer, et key est son identification dans le réseau Ethereum, ce qui peut être considéré comme similaire à l’existence de CID dans IPFS. Une fois que la paire (clé, données) est stockée avec succès dans le réseau EthStorage, EthStorage génère un kvldx et le renvoie au réseau principal Ethereum, qui correspond à la clé sur Ethereum, et cette valeur correspond à l’adresse de stockage des données sur EthStorage, de sorte que le problème du stockage d’une grande quantité de données est maintenant changé pour stocker une seule paire (clé, kvldx), ce qui réduit considérablement le coût de stockage du réseau principal Ethereum. Si vous avez besoin de faire un appel aux données précédemment stockées, vous devez utiliser la fonction get() dans EthStorage et entrer le paramètre key, et vous pouvez effectuer une recherche rapide sur les données sur EthStorage via kvldx stockées sur Ethereum.
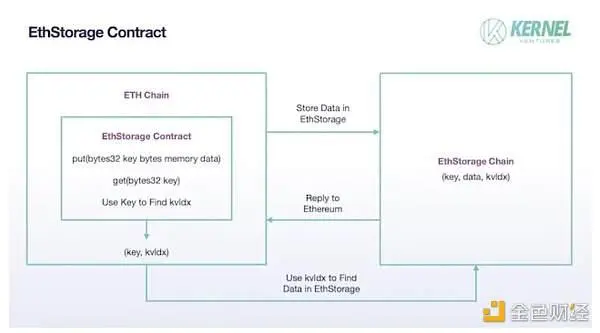
Contrat EthStorage, source de l’image : Kernel Ventures
En ce qui concerne la façon dont les nœuds stockent les données, EthStorage emprunte au modèle d’Arweave. Tout d’abord, un grand nombre de paires (k,v) d’ETH sont partitionnées, et chaque partitionnement contient un nombre fixe de paires de données (k,v), dont il existe également une limite sur la taille spécifique de chaque paire (k,v), afin d’assurer l’équité de la taille de la charge de travail dans le processus de stockage des récompenses pour les mineurs. Pour l’émission de récompenses, vous devez vérifier si le nœud stocke des données. Dans ce processus, EthStorage divise un sharding (taille d’un téraoctet) en un grand nombre de morceaux et conserve une racine de Merkle sur le réseau principal d’Ethereum pour validation. Ensuite, le mineur doit fournir un nonce pour générer les adresses de plusieurs morceaux par le biais d’un algorithme aléatoire avec le hachage du bloc précédent sur EthStorage, et le mineur doit fournir les données de ces morceaux pour prouver qu’il a effectivement stocké l’ensemble du sharding. Cependant, ce nonce ne peut pas être sélectionné arbitrairement, sinon le nœud sélectionnera un nonce approprié qui ne correspond qu’à son bloc stocké pour passer la vérification, de sorte que ce nonce doit faire en sorte que le morceau généré réponde aux exigences du réseau après le mélange et le hachage, et seul le premier nœud à soumettre le nonce et la preuve d’accès aléatoire peut obtenir la récompense.
4.2.2 DA modulaire : Celestia
Module Blockchain : À ce stade, les transactions qui doivent être exécutées par la chaîne publique de couche 1 sont principalement divisées en quatre parties suivantes : (1) concevoir la logique sous-jacente du réseau, sélectionner les validateurs d’une certaine manière, écrire des blocs et distribuer des récompenses aux mainteneurs du réseau, (2) empaqueter et traiter les transactions et publier les transactions associées, (3) vérifier les transactions à mettre sur la chaîne et déterminer l’état final, et (4) stocker et maintenir les données historiques sur la blockchain. En fonction des fonctions accomplies, on peut diviser la blockchain en quatre modules, à savoir la couche consensus, la couche d’exécution, la couche de règlement, et la couche de disponibilité des données (couche DA).
Conception modulaire de la blockchain : Pendant longtemps, ces quatre modules ont été intégrés dans une chaîne publique, et une telle blockchain est appelée blockchain monolithique. Ce formulaire est plus stable et facile à maintenir, mais il met également beaucoup de pression sur une seule chaîne publique. Dans la pratique, ces quatre modules se contraignent les uns les autres et se disputent les ressources limitées de calcul et de stockage de la chaîne publique. Par exemple, l’augmentation de la vitesse de traitement de la couche de traitement exercera une pression de stockage plus importante sur la couche de disponibilité des données, et la sécurité de la couche d’exécution nécessitera des mécanismes d’authentification plus complexes qui ralentissent le traitement des transactions. Par conséquent, le développement des chaînes publiques est souvent confronté à des arbitrages entre ces quatre modules. Afin de briser le goulot d’étranglement de l’amélioration des performances de cette chaîne publique, les développeurs ont proposé un schéma de blockchain modulaire. L’idée de base de la blockchain modulaire est de séparer un ou plusieurs des quatre modules ci-dessus et de les confier à une implémentation de chaîne publique distincte. De cette façon, sur la chaîne publique, vous ne pouvez vous concentrer que sur l’amélioration de la vitesse de transaction ou de la capacité de stockage, et dépasser les limitations précédentes causées par l’effet short-board sur les performances globales de la blockchain.
DA modulaire : L’approche complexe consistant à détacher la couche DA de l’activité blockchain et à la confier à une seule chaîne publique est considérée comme une solution viable pour les données historiques croissantes de la couche 1. L’exploration dans cette zone n’en est qu’à ses débuts, Celestia étant le projet le plus représentatif à l’heure actuelle. En ce qui concerne la méthode de stockage spécifique, Celestia emprunte à la méthode de stockage de Danksharding, qui consiste à diviser les données en plusieurs blocs, à en extraire une partie par chaque nœud pour le stockage et à vérifier l’intégrité des données avec l’engagement polynomial KZG. Dans le même temps, Celestia utilise un codage d’effacement RS 2D avancé pour réécrire les données d’origine sous la forme d’une matrice kk, et finalement seulement 25% des données d’origine peuvent être récupérées. Cependant, le stockage par partitionnement de données ne multiplie essentiellement la pression de stockage des nœuds sur l’ensemble du réseau que par un facteur sur le volume total de données, et la pression de stockage et le volume de données des nœuds maintiennent toujours une croissance linéaire. Alors que la couche 1 continue d’améliorer la vitesse de transaction, la pression de stockage des nœuds peut encore atteindre un seuil inacceptable un jour. Pour résoudre ce problème, le composant IPLD a été introduit dans Celestia pour le traitement. Pour les données de la matrice kk, elles ne sont pas stockées directement sur Celestia, mais dans le réseau LL-IPFS, et seul le code CID de ces données sur IPFS est conservé dans le nœud. Lorsqu’un utilisateur demande un élément de données historiques, le nœud envoie le CID correspondant au composant IPLD et utilise le CID pour appeler les données brutes sur IPFS. Si des données existent sur IPFS, elles sont renvoyées via des composants et des nœuds IPLD, et si ce n’est pas le cas, elles ne peuvent pas être renvoyées.
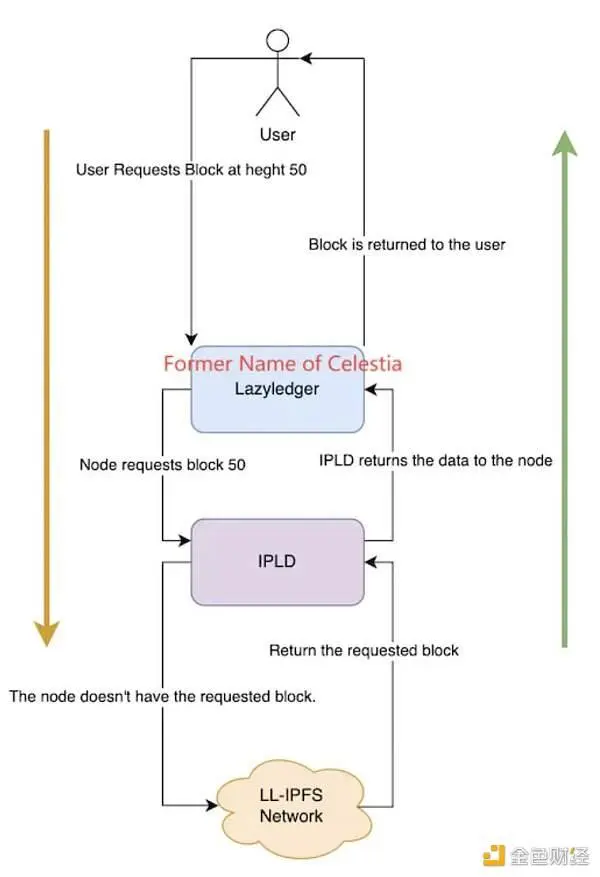
Comment les données Celestia sont lues, source de l’image : Celestia Core
Celestia : En prenant l’exemple de Celestia, nous pouvons avoir un aperçu de l’application de la blockchain modulaire pour résoudre le problème de stockage d’Ethereum. Le nœud Rollup enverra les données de transaction packagées et vérifiées à Celestia et stockera les données sur Celestia, dans ce processus, Celestia ne stocke que les données sans trop s’en rendre compte, et enfin en fonction de la taille de l’espace de stockage, le nœud Rollup paiera les jetons tia correspondants à Celestia en tant que frais de stockage. Le stockage dans Celstia exploite le DAS et le codage d’effacement similaires à ceux de EIP4844, mais le codage d’effacement polynomial dans EIP4844 est mis à niveau vers le codage d’effacement RS 2D et la sécurité du stockage est à nouveau mise à niveau, ne nécessitant que 25 % de fractures pour restaurer l’ensemble des données de transaction. Essentiellement, il s’agit simplement d’une chaîne publique de points de vente à faible coût, et si vous souhaitez résoudre le problème de stockage des données historiques d’Ethereum, vous avez besoin de nombreux autres modules spécifiques pour fonctionner avec Celestia. Par exemple, en termes de rollups, l’un des modes de rollup les plus recommandés sur le site officiel de Celestia est Sovereign Rollup. Contrairement aux cumuls courants de la couche 2, seule la transaction est calculée et vérifiée, c’est-à-dire que l’opération de la couche d’exécution est terminée. Le Sovereign Rollup englobe l’ensemble du processus d’exécution et de règlement, ce qui minimise le traitement des transactions sur Celestia, ce qui peut maximiser la sécurité du processus de transaction global lorsque la sécurité globale de Celestia est plus faible que celle d’Ethereum. Pour ce qui est d’assurer la sécurité des données appelées par Celestia sur le réseau principal d’Ethereum, la solution la plus courante est le contrat intelligent de pont de gravité quantique. Pour les données stockées sur Celestia, il génère une racine de Merkle (preuve de disponibilité des données) et reste sur le contrat de pont gravitationnel quantique sur le réseau principal d’Ethereum, et chaque fois qu’Ethereum appelle des données historiques sur Celestia, il compare son résultat de hachage avec la racine de Merkle, et si c’est le cas, cela signifie qu’il s’agit bien de données historiques vraies.
4.2.3 Chaîne publique de magasins DA
En ce qui concerne le principe de la technologie DA de la chaîne principale, de nombreuses technologies similaires au Sharding sont empruntées à la chaîne publique de stockage. Parmi les DA tiers, certains d’entre eux ont effectué certaines tâches de stockage directement à l’aide de la chaîne publique de stockage, telles que les données de transaction spécifiques dans Celestia sont placées sur le réseau LL-IPFS. Dans la solution DA tierce, en plus de créer une chaîne publique distincte pour résoudre le problème de stockage de la couche 1, un moyen plus direct consiste à connecter directement la chaîne publique de stockage à la couche 1 pour stocker les énormes données historiques sur la couche 1. Pour les blockchains haute performance, le volume de données historiques est encore plus important, et la taille des données de la chaîne publique haute performance Solana est proche de 4 PG lorsqu’elle fonctionne à pleine vitesse, ce qui est complètement au-delà de la plage de stockage des nœuds ordinaires. La solution choisie par Solana était de stocker les données historiques sur Arweave, un réseau de stockage décentralisé, et de ne conserver que 2 jours de données sur les nœuds du réseau principal à des fins de vérification. Afin d’assurer la sécurité du processus stocké, Solana et la chaîne Arweave ont conçu un protocole de pont de stockage, Solar Bridge. Les données vérifiées par le nœud Solana sont synchronisées avec Arweave et la balise correspondante est renvoyée. Grâce à cette balise, les nœuds Solana peuvent consulter à tout moment les données historiques de la blockchain Solana. Sur Arweave, il n’est pas nécessaire que les nœuds du réseau maintiennent la cohérence des données et l’utilisent comme seuil pour participer au fonctionnement du réseau, mais adoptent plutôt la méthode de stockage des récompenses. Tout d’abord, Arweave n’utilise pas une structure de chaîne traditionnelle pour construire des blocs, mais plutôt une structure de graphe. Dans Arweave, un nouveau bloc pointe non seulement vers le bloc précédent, mais aussi vers un bloc de rappel généré aléatoirement. L’emplacement exact d’un bloc de rappel est déterminé par le hachage de son bloc précédent et sa hauteur de bloc, et l’emplacement du bloc de rappel est inconnu jusqu’à ce que le bloc précédent soit miné. Cependant, dans le processus de génération de nouveaux blocs, les nœuds doivent disposer des données de Recall Block pour utiliser le mécanisme POW afin de calculer le hachage de la difficulté spécifiée, et seuls les mineurs qui calculent en premier le hachage qui correspond à la difficulté peuvent être récompensés, ce qui encourage les mineurs à stocker autant de données historiques que possible. Dans le même temps, moins il y a de personnes qui stockent un bloc historique, moins le nœud aura de concurrents lorsqu’il générera une difficulté nonce, ce qui encouragera les mineurs à stocker des blocs avec moins de sauvegardes dans le réseau. Enfin, afin de s’assurer que les nœuds peuvent stocker des données en permanence dans Arweave, le mécanisme de notation des nœuds de WildFire est introduit. Les nœuds ont tendance à communiquer avec des nœuds qui peuvent fournir plus de données historiques plus rapidement, tandis que les nœuds avec des notes plus faibles n’ont souvent pas accès aux dernières données de bloc et de transaction en premier lieu, de sorte qu’ils ne peuvent pas prendre la tête de la concurrence pour POW.
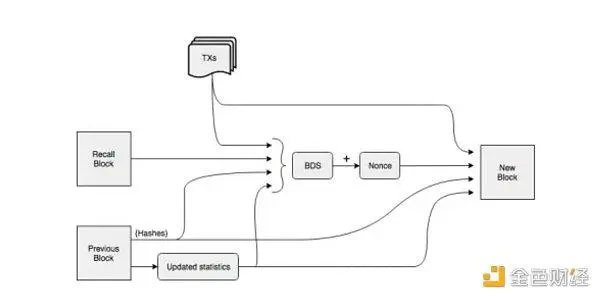
Comment les blocs Arweave sont construits, source de l’image : Arweave Yellow-Paper
5. Comparaison complète
Ensuite, nous comparerons les avantages et les inconvénients de chacun des cinq scénarios de stockage en fonction des quatre dimensions des mesures de performance DA.
Sécurité : La plus grande source de problèmes de sécurité des données est la perte causée par la transmission de données et la falsification malveillante de nœuds malhonnêtes, et dans le processus inter-chaînes, en raison de l’indépendance et de l’état des deux chaînes publiques ne sont pas partagées, c’est le domaine le plus durement touché de la sécurité de la transmission de données. De plus, la couche 1 qui nécessite une couche DA dédiée à ce stade dispose souvent d’un groupe de consensus fort, et sa propre sécurité sera beaucoup plus élevée que celle des chaînes publiques de stockage ordinaires. Par conséquent, le schéma de la chaîne principale DA a une sécurité plus élevée. Après s’être assuré de la sécurité de la transmission des données, l’étape suivante consiste à assurer la sécurité des données d’appel. Si l’on ne considère que les données historiques à court terme utilisées pour vérifier les transactions, les mêmes données sont sauvegardées par l’ensemble du réseau dans le réseau stocké temporairement, alors que le nombre moyen de sauvegardes de données dans le schéma de type DankSharding n’est que de 1/N du nombre de nœuds dans l’ensemble du réseau, une redondance de données plus importante peut rendre les données moins susceptibles d’être perdues et peut également fournir plus d’échantillons de référence pour la vérification. Par conséquent, le stockage temporaire aura une sécurité des données plus élevée. Dans le schéma DA tiers, le DA dédié à la chaîne principale utilise des nœuds communs avec la chaîne principale, et les données peuvent être directement transmises via ces nœuds relais pendant le processus inter-chaînes, de sorte qu’il aura également une sécurité relativement plus élevée que les autres solutions DA.
Coût de stockage : le plus grand contributeur aux coûts de stockage est la quantité de redondance des données. Dans la solution de stockage à court terme de la chaîne principale DA, la synchronisation des données des nœuds de l’ensemble du réseau est utilisée pour le stockage, et toutes les données nouvellement stockées doivent être sauvegardées par les nœuds de l’ensemble du réseau, ce qui a le coût de stockage le plus élevé. Le coût élevé du stockage détermine à son tour que cette méthode ne convient qu’au stockage temporaire dans les réseaux à haut TPS. La seconde est la méthode de stockage du partitionnement, y compris le partitionnement dans la chaîne principale et le partitionnement dans les DA tiers. Étant donné que la chaîne principale a tendance à avoir plus de nœuds, il y aura plus de sauvegardes pour chaque bloc, de sorte que la solution de partitionnement de la chaîne principale aura un coût plus élevé. Le coût de stockage le plus bas est le DA de la chaîne publique de stockage qui adopte la méthode de stockage par récompense, et la quantité de redondance des données dans ce schéma fluctue souvent autour d’une constante fixe. Dans le même temps, un mécanisme d’ajustement dynamique a également été introduit dans la chaîne de stockage publique DA pour inciter les nœuds à stocker moins de données de sauvegarde en augmentant les récompenses pour assurer la sécurité des données.
Vitesse de lecture des données : la vitesse de stockage des données est principalement affectée par l’emplacement de stockage des données dans l’espace de stockage, le chemin d’accès à l’index des données et la distribution des données dans les nœuds. Parmi eux, l’endroit où les données sont stockées sur le nœud a un impact plus important sur la vitesse, car le stockage des données en mémoire ou sur SSD peut faire varier la vitesse de lecture de plusieurs dizaines de fois. La chaîne de stockage publique DA adopte principalement le stockage SSD, car la charge sur la chaîne comprend non seulement les données de la couche DA, mais également les données personnelles à forte occupation de la mémoire telles que les vidéos et les images téléchargées par les utilisateurs. Si le réseau n’utilise pas de SSD comme espace de stockage, il est difficile de résister à l’énorme pression de stockage et de répondre aux besoins de stockage à long terme. Deuxièmement, pour les DA tiers et les DA de la chaîne principale qui utilisent des données de stockage en mémoire, le DA tiers doit d’abord rechercher les données d’index correspondantes dans la chaîne principale, puis transférer les données d’index vers le DA tiers à travers la chaîne et renvoyer les données via le pont de stockage. En revanche, les DA de la chaîne principale peuvent interroger les données directement à partir des nœuds et ont donc des vitesses de récupération de données plus rapides. Enfin, à l’intérieur de la chaîne principale DA, la méthode Sharding doit appeler le bloc à partir de plusieurs nœuds et restaurer les données d’origine. Par conséquent, le stockage à court terme est plus lent que le stockage à court terme sans partitionnement.
Universalité de la couche DA : L’universalité DA de la chaîne principale est proche de zéro, car il est impossible de transférer des données d’une chaîne publique avec un espace de stockage insuffisant vers une autre chaîne publique avec un espace de stockage insuffisant. Dans les DA tiers, la polyvalence de la solution et sa compatibilité avec une chaîne principale particulière sont deux indicateurs contradictoires. Par exemple, dans un schéma DA spécifique à la chaîne principale conçu pour une certaine chaîne principale, un grand nombre d’améliorations ont été apportées au niveau du type de nœud et du consensus du réseau pour s’adapter à la chaîne publique, de sorte que ces améliorations peuvent être un énorme obstacle lors de la communication avec d’autres chaînes publiques. Cependant, au sein de la DA tierce, par rapport à la DA modulaire, la DA de la chaîne publique de stockage est plus performante en termes de polyvalence. La chaîne publique de stockage DA dispose d’une plus grande communauté de développeurs et de plus d’installations d’expansion, qui peuvent s’adapter à la situation des différentes chaînes publiques. Dans le même temps, la DA de la chaîne publique de stockage obtient des données plus activement par le biais de la capture de paquets, plutôt que de recevoir passivement des informations transmises par d’autres chaînes publiques. Par conséquent, il peut encoder les données à sa manière, réaliser le stockage standardisé des flux de données, faciliter la gestion des informations de données provenant de différentes chaînes principales et améliorer l’efficacité du stockage.
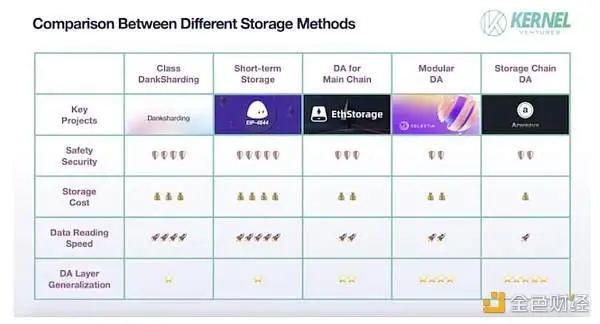
Comparaison des performances de la solution de stockage, source de l’image : Kernel Ventures
6. résumé
À ce stade, les blockchains subissent une transition de la crypto vers un Web3 plus inclusif, apportant plus qu’une simple multitude de projets sur la blockchain. Afin de s’adapter à autant de projets s’exécutant en même temps sur la couche 1, tout en assurant l’expérience des projets Gamefi et Socialfi, la couche 1, représentée par Ethereum, a adopté des méthodes telles que les rollups et les blobs pour améliorer le TPS. Parmi les blockchains naissantes, le nombre de blockchains performantes est également en augmentation. Mais un TPS plus élevé signifie non seulement des performances plus élevées, mais aussi une plus grande pression de stockage sur le réseau. Pour les données historiques massives, une variété de méthodes d’AD basées sur la chaîne principale et des tiers sont proposées à ce stade pour s’adapter à la croissance de la pression de stockage on-chain. Il y a des avantages et des inconvénients à chaque méthode d’amélioration, et elle a une applicabilité différente dans différents contextes.
Les blockchains basées sur le paiement ont des exigences extrêmement élevées en matière de sécurité des données historiques et ne poursuivent pas un TPS particulièrement élevé. Si ce type de chaîne publique est encore en phase préparatoire, vous pouvez adopter une méthode de stockage de type DankSharding, qui permet d’augmenter considérablement la capacité de stockage tout en garantissant la sécurité. Cependant, s’il s’agit d’une chaîne publique comme Bitcoin, qui a été formée et compte un grand nombre de nœuds, il y a un risque énorme à apporter des améliorations hâtives au niveau de la couche de consensus, il est donc possible d’adopter une DA dédiée à la chaîne principale avec une haute sécurité dans le stockage hors chaîne pour prendre en compte les problèmes de sécurité et de stockage. Mais il convient de noter que la fonctionnalité de la blockchain n’est pas statique mais en constante évolution. Par exemple, au début, les fonctions d’Ethereum se limitaient principalement aux paiements et à l’utilisation de contrats intelligents pour automatiser simplement les actifs et les transactions, mais avec l’expansion continue du territoire de la blockchain, divers projets Socialfi et Defi ont progressivement été ajoutés à Ethereum, ce qui a permis à Ethereum de se développer dans une direction plus complète. Récemment, avec l’apparition de l’écologie de l’inscription sur Bitcoin, les frais de transaction du réseau Bitcoin ont été multipliés par près de 20 depuis août, ce qui reflète le fait que la vitesse de transaction du réseau Bitcoin à ce stade ne peut pas répondre à la demande de transaction, et que les traders ne peuvent qu’augmenter les frais de transaction afin que la transaction puisse être traitée dès que possible. Maintenant, la communauté Bitcoin doit faire un compromis, soit accepter des frais élevés et des vitesses de transaction lentes, soit réduire la sécurité du réseau pour augmenter la vitesse des transactions mais aller à l’encontre de l’objectif initial du système de paiement. Si la communauté Bitcoin choisit cette dernière option, le schéma de stockage correspondant devra également être ajusté face à la pression croissante des données.
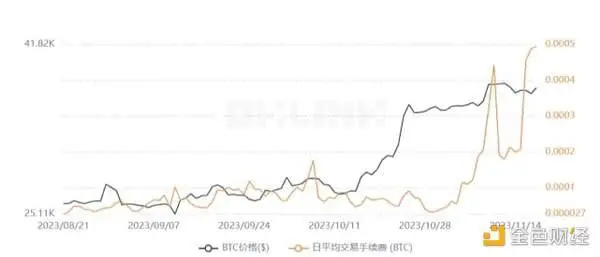
Les frais de transaction du réseau principal Bitcoin fluctuent, source de l’image : OKLINK
Pour la chaîne publique avec des fonctions complètes, il y a une plus grande poursuite du TPS, et la croissance des données historiques est encore plus importante, et il est difficile de s’adapter à la croissance rapide du TPS à long terme en adoptant une solution de type DankSharding. Par conséquent, il est plus approprié de migrer les données vers un DA tiers pour le stockage. Parmi eux, le DA dédié à la chaîne principale a la plus grande compatibilité, et peut être plus avantageux si l’on ne considère que le problème de stockage d’une seule chaîne publique. Cependant, dans la chaîne publique de couche 1 d’aujourd’hui, le transfert d’actifs inter-chaînes et l’interaction des données sont également devenus une activité courante de la communauté blockchain. Si l’on considère le développement à long terme de l’ensemble de l’écosystème blockchain, le stockage des données historiques de différentes chaînes publiques sur la même chaîne publique peut éliminer de nombreux problèmes de sécurité dans le processus d’échange et de vérification des données, de sorte que la voie de la DA modulaire et du stockage de la DA de la chaîne publique peut être un meilleur choix. Dans le cadre d’une stricte universalité, l’AD modulaire se concentre sur la fourniture de services de la couche DA de la blockchain, et introduit des données historiques de gestion des données d’index plus raffinées, ce qui peut faire une classification raisonnable des données de différentes chaînes publiques, et présente plus d’avantages par rapport au stockage des chaînes publiques. Cependant, le schéma ci-dessus ne prend pas en compte le coût de l’ajustement de la couche consensuelle sur la chaîne publique existante, ce qui est extrêmement risqué, et une fois qu’il y a un problème, cela peut conduire à des vulnérabilités systémiques et faire perdre à la chaîne publique le consensus de la communauté. Par conséquent, s’il s’agit d’une solution transitoire dans le processus de mise à l’échelle de la blockchain, le stockage temporaire le plus simple de la chaîne principale peut être plus approprié. Enfin, les discussions ci-dessus sont basées sur la performance dans le processus d’exploitation réel, mais si l’objectif d’une chaîne publique est de développer sa propre écologie et d’attirer plus de parties et de participants au projet, elle peut également préférer des projets soutenus et financés par sa propre fondation. Par exemple, dans le cas de performances globales identiques ou même légèrement inférieures à celles du système de stockage de la chaîne publique, la communauté Ethereum préférera également EthStorage en tant que projet de couche 2 soutenu par la Fondation Ethereum pour continuer à développer l’écosystème Ethereum.
Dans l’ensemble, la complexité croissante des blockchains d’aujourd’hui entraîne également des exigences accrues en matière d’espace de stockage. S’il y a suffisamment de validateurs de couche 1, les données historiques n’ont pas besoin d’être sauvegardées par tous les nœuds de l’ensemble du réseau, et n’ont besoin d’être sauvegardées qu’à un certain nombre pour assurer une sécurité relative. Dans le même temps, la division du travail des chaînes publiques devient de plus en plus détaillée, la couche 1 étant responsable du consensus et de l’exécution, le rollup responsable du calcul et de la vérification, puis l’utilisation d’une blockchain distincte pour le stockage des données. Chaque partie peut se concentrer sur une fonction sans être limitée par les performances des autres. Cependant, la quantité ou le pourcentage de nœuds à stocker pour les données historiques afin d’atteindre un équilibre entre sécurité et efficacité, et comment assurer l’interopérabilité sécurisée entre les différentes blockchains, est une question à laquelle les développeurs de blockchain doivent réfléchir et s’améliorer constamment. Pour les investisseurs, ils peuvent prêter attention au projet DA dédié à la chaîne principale sur Ethereum, car Ethereum a déjà suffisamment de partisans à ce stade pour qu’il n’ait pas besoin de compter sur d’autres communautés pour étendre son influence. D’autres ont besoin d’améliorer et de développer leurs propres communautés et d’attirer plus de projets dans l’écosystème Ethereum. Cependant, pour les chaînes publiques en position de chasseurs, telles que Solana et Aptos, la chaîne unique elle-même ne dispose pas d’un écosystème aussi complet, elle peut donc être plus encline à unir les forces d’autres communautés pour construire un énorme écosystème inter-chaînes afin d’étendre son influence. Par conséquent, pour la couche 1 émergente, les DA tiers génériques méritent plus d’attention.
Source : Golden Finance (en anglais seulement)