Alaya AIの技術アーキテクチャ:分散型AIデータネットワークの動作メカニズムとは?
AIモデルがマルチモーダル化、垂直ユースケース、そして知的エージェント(Agent)へと進化するにつれ、業界の共通認識は「データは多ければ多いほど良い」から「高忠実度で、追跡可能かつプライバシーに準拠したデータこそが希少資源である」へとシフトしています。従来の中央集権型ラベリングプラットフォームは、コスト、ロングテール需要への応答、そして貢献者への公平な価値配分の面で限界に直面しています。分散型AIデータネットワークは、群知能、トークンによる協調、そしてオープンなインターフェースを通じて、データの生成関係そのものを再構築しようとしています。Alaya AIの動作を理解するには、その技術レイヤー、自動ラベリングパイプライン、サンプリングロジック、そしてオンチェーン上の経済メカニズムを詳細に検討する必要があり、単なる「ブロックチェーンを利用したラベリングの外部委託サービス」と片付けるべきではありません。
産業アーキテクチャの観点から見ると、Alaya AIは、Web3とAIがデータレイヤーで融合した存在です。データへの貢献にインセンティブが付与され、タスクの権限はNFT化され、モデル開発はAGTのステーキングプールを通じたコミュニティ支援によって資金調達されます。さらに、オープンデータプラットフォーム(ODP)が需要と供給を結びつけます。以下のセクションでは、本ネットワークのコアアーキテクチャ、効率化メカニズム、Web3との統合、ステーキングと貢献システム、従来型プラットフォームとの差異、現実世界での課題、そして将来の方向性を分析し、その技術的実現性とエコシステムとしての価値を評価するための枠組みを提供します。
Alaya AIのコア技術アーキテクチャの詳細
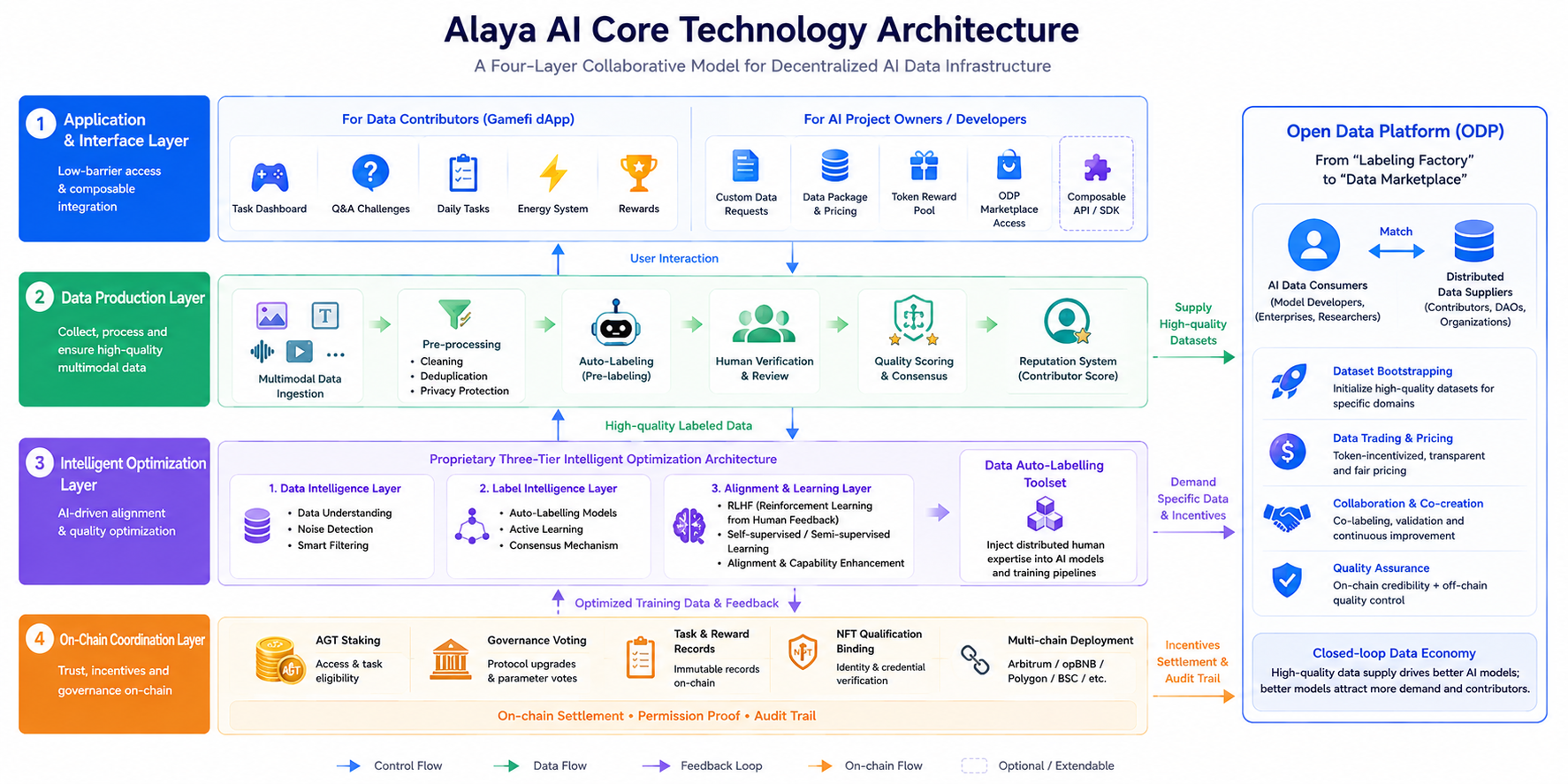
Alaya AIの全体アーキテクチャは、4層からなる協調モデルとして説明できます。各層は明確に分離された責務を持ち、データと制御の流れが独立しているため、「すべてをオンチェーンに載せる」ことによるパフォーマンスのオーバーヘッドを回避しています。
-
アプリケーション・インターフェース層:データ提供者向けのゲーム化されたDApp(分散型アプリケーション)(タスクパネル、クイズチャレンジ、デイリータスクなどを含む)と、AIプロジェクトチーム向けのカスタムデータリクエスト、データパッケージの提供、ODPマーケットプレイスへの入り口で構成されます。この層は、低い参入障壁と柔軟なアクセス手段を重視しており、開発者はカスタムトークンの報酬プールを通じて、垂直領域のデータニーズを公開できます。
-
データ生成層:マルチモーダルデータ(テキスト、画像、動画、音声)の取り込み、前処理(クリーニング、重複排除、プライバシー保護)、自動ラベリング、手動検証、品質スコアリングを担当します。Alaya AIは群知能の原理を採用しており、同一タスクを複数の提供者がクロスラベリングし、コンセンサスまたは多数決メカニズムによってラベルの一貫性を高めます。同時に、過去の正確性に基づく提供者の評判が、将来のタスク割り当てに影響を与えます。
-
インテリジェント最適化層:中核となるのは、独自の3層インテリジェント最適化アーキテクチャによって駆動されるデータ自動ラベリングツールセットです。RLHF(人間のフィードバックからの強化学習)によるファインチューニングと組み合わせることで、分散された人間の専門知識を自己教師あり学習や半教師あり学習のプロセスに注入し、アライメントとモデル性能の向上を支援します。
-
オンチェーン協調層:AGTのステーキング、ガバナンス投票、タスクと報酬のステータス記録、NFTの資格連携といった主要な調整情報は、ブロックチェーンに依存します(エコシステムはArbitrum、opBNB、Polygon、BSCなど複数のチェーンに展開されています。詳細は公式発表をご参照ください)。チェーン自体は大量の生データを保存しませんが、インセンティブの決済、許可の証明、監査証跡の固定を処理します。これは、「オフチェーンで計算し、オンチェーンで信頼する」という、一般的なWeb3 AIの設計パラダイムに従っています。
2024年11月にローンチされたオープンデータプラットフォーム(ODP)は、本ネットワークを「ラベリング工場」から「データマーケットプレイス」へと拡張します。AIデータの消費者と分散された提供者が、カスタマイズ可能なトークンインセンティブを通じて直接結びつき、データセットの立ち上げ、取引、そして協力を促進し、需要と供給の循環を生み出します。
自動ラベリングシステムがAIデータの効率を高める仕組み
自動ラベリングは、Alaya AIが限界コストを削減し、納品サイクルを短縮するための中核モジュールです。このプロジェクトは、これを自己教師ありAI進化の次の段階として位置づけています。すなわち、機械がまず候補ラベルを生成し、人間は曖昧なサンプルや領域固有の判断に集中することで、すべてのデータをゼロから手動でラベリングする必要をなくします。
技術プロセスは、通常以下の手順で構成されます。
-
マルチモーダル取り込み:ツールチェーンは、静的および動的な視覚データ、テキスト、センサー入力を受け入れ、これらすべてが統一された前処理パイプラインに入力されます。
-
アルゴリズムによる前処理:自動クリーニングと重複排除が実行されます。機密性の高いデータパスにはゼロ知識暗号化(ZK暗号化)が適用され、プレーンテキストの露出を最小限に抑えながら計算を可能にし、エンタープライスクライアントのプライバシーとコンプライアンス要件に対応します。
-
モデルによる事前ラベリング:独自の自動ラベリングモデルが初期ラベルを生成します。一般的なAIデータカテゴリでは、80%を超える検証率が達成されているとされ、動的な視覚ストリームをリアルタイムで処理できることは、自動運転のフレームラベリングや産業用品質検査ビデオなど、重要なシナリオで不可欠です。
-
RLHF最適化ループ:提供者による検証結果がモデルにフィードバックされ、手動レビューの割合が継続的に削減されます。業界の実践では、RLHFループ内で人間の介入を高難度サンプルの約20%に集中させることで、全体のコストと期間を大幅に削減できることが示されています(正確な割合はタスクの種類によって異なります)。
-
エキスパート真実層:エンタープライズグレードの高忠実度注文に対しては、プラットフォームは社内の領域専門家チーム(エンジニア、言語学者、視覚専門家など)を最終的な判断層として配置できます。これにより、クラウドソーシング結果と並行して、「自動処理によるスループット」と「専門家による精度」という二重のトラック構造が構築されます。2026年の資料では、大量のノイズデータが運用上のボトルネックになりつつあること、そして高忠実度の垂直データこそが次世代モデルとエージェントにとって不可欠な燃料であることも強調されています。
このハイブリッドアーキテクチャの価値は、公開ネットワークが規模と速度を提供する一方で、閉じたエキスパートパイプラインがリスクの高い業界で品質の基準を維持し、分散化が「低品質なクラウドソーシング」と誤解されることを防ぐ点にあります。
分散型データサンプリングメカニズムの仕組み
「完全なランダムスクレイピング」とは異なり、Alaya AIはインテリジェントな最適化と対象を絞ったサンプリングを重視します。モデルの目的に基づいて情報密度の高いサンプルを選択し、「大規模データセットだが有効なシグナルが少ない」という問題を緩和します。
サンプリングメカニズムは、以下の3つの側面から理解できます。
-
需要主導:AIクライアントがカスタムリクエスト(例:特定の方言、専門的な医用画像、地域の交通状況)を提出します。プラットフォームは、必要なNFTレベル、言語、または専門的背景に一致する提供者プールに作業単位を振り分け、労働力とタスクの大まかなマッチングを実現します。
-
グループ冗長サンプリング:複数の個人が同一のデータバッチを独立してラベリングします。一貫性の検出により外れ値ラベルが特定され、一貫性の低いサンプルは自動的にレビューキューまたはエキスパートチャネルに送られます。これにより、単一の品質検査担当者による全数監視が、分散された冗長性に置き換えられます。
-
動的・静的振り分け:静的な画像タスクと動的な動画ストリームタスクでは、異なるスループット戦略が適用されます。動的ビジョンでは、自動セグメンテーションとフレームレベルのラベリングを統合することで、フレームあたりの手動コストを削減できます。
-
時間・シナリオサンプリング:公式のシナリオでは、通勤時間などの細切れの時間を活用した軽量タスクへの参加が想定されており、アイドル状態のマンパワーをデータ生産能力に変換します。ゲーム化されたUI(経験値、エネルギー値)が長期的な定着を促進し、サンプリングプールを一度限りのクラウドソーシングではなく、継続的なものにします。
前処理段階でのクリーニングと重複排除は、サンプリングバイアスを根本的に低減します。重複サンプル、破損ファイル、または誤ったメタデータがトレーニングセットに混入すると、モデルの幻覚やバイアスを増幅させるためです。したがって、サンプリングは「どれだけサンプリングするか」だけでなく、「何を、誰が、どのように検証するか」を含む、体系的なエンジニアリングの取り組みです。
Web3とAIネットワークの融合
Alaya AIのWeb3としての特性は、「トークンで支払う」ことだけに留まりません。データネットワークの主要な調整要素をトークン化、NFT化、そしてガバナンスの対象とすることに本質があります。
-
トークンによる調整:ネイティブトークンであるAGTは、ステーキングの最低要件、ガバナンス投票、高度なタスクの解除、NFTのアップグレード、モデルステーキングプールへの資金提供の入り口として機能します。ステーキングの設計は、サンクコストとセキュリティを重視しています。プロジェクトは、AGTのステーキング自体は受動的な収益を生み出さないと明言しており、投機的な資本がラベリング品質へのインセンティブを損なうことを防いでいます。
-
NFTによる権限管理:Alaya NFTとMedallion NFTは二重のアイデンティティシステムを形成し、アクセス可能なタスクの種類、レベル上限、達成システムを決定します。上位レベルへのアップグレードは特定のノードでAGTを消費し、オンチェーン上のアイデンティティをオフラインの労働成果と結びつけます。
-
オープンなインセンティブの組み合わせ:プロジェクトはAGTまたは自社トークンを使用してカスタムデータプールを作成でき、Web3ネイティブなAIチームの決済好みに対応できます。中小規模の開発者は、ODPを通じてより低い現金コストでデータセットを立ち上げることができます。
-
オンチェーン監査と来歴:エンタープライスクライアント向けに、プラットフォームはエンドツーエンドの暗号学的整合性と改ざん不可能な監査証跡を強調し、データの来歴を追跡可能にしてコンプライアンスレビューを支援します。
-
ゲーミフィケーションとソーシャルグロース:デイリータスク、紹介コミッション、毎月のAGT交換(ユーザーがタスクで獲得したAIAクレジットを、一定期間の交換プールでAGTと交換する)などのメカニズムにより、オフラインの活動が定期的にオンチェーン上の価値分配にマッピングされます。
-
マルチチェーン展開:異なるエコシステムのユーザーにとっての障壁を低減します。同一のデータネットワークが、Arbitrum、opBNBなど様々なチェーン上のユーザー層にリーチできます。ロードマップでは、BNB ChainやOptimismなどへの拡張も言及されており、手数料や速度の違いに適応することを目指しています。
2026年のエコシステムのストーリーは、Alaya AIをAIエージェントのためのデータ基盤としてさらに位置づけています。エージェントは継続的な人間のフィードバックとニッチな知識を必要としますが、Web3のクラウドソーシングと自動ラベリングの組み合わせは、拡張可能なフィードバックパイプラインを提供します。外部で議論されているOpenClawのような機能を持つリアルタイム対話型エージェントフレームワークとのシナジーは、「その場で学習する」ループと「大規模検証済みデータセット」のループという二重構造の未来を示唆しています。
AIモデルステーキングとデータ貢献システムの分析
AIモデルのトークン化は、Alaya AIを一般的なラベリングプラットフォームと区別する重要なメカニズムです。コミュニティは、AGTステーキングプールを通じて特定のモデル開発やファインチューニングに資金を提供し、データ労働力を提供することができます。これにより、「データを提供した者がモデル改善の恩恵を受ける」というインセンティブの一致が促進されます。
-
提供者としての道筋:dAppに登録 → 基本タスクを完了して評判を構築 → AGTをステークして上位レベルのタスク(検証、キャリブレーション、自動ラベリング協力)を解放 → より高い報酬倍率を獲得。同時にAIAクレジットを獲得し、毎月のAGT交換に参加します。
-
プロジェクトとしての道筋:プラットフォーム上でカスタムデータリクエストを公開 → AGTまたはサードパーティトークンの報酬プールを設定 → プラットフォームがタスクを適切な提供者に割り当て → 自動ラベリングと手動品質管理を経てデータセットを納品 → 任意でODPに上場または取引。
-
ステーキングのセキュリティロジック:AGTはプルーフ・オブ・ステーク(PoS)型の調整ツールとして機能し、悪意のあるラベリングやボリュームファーミングの経済的コストを高めます。Medallion NFTと組み合わせることで、上位レベルのタスクへのアクセスをさらに制限し、高価値のデータ注文を保護します。
-
価値の還流:公式の計画では、プラットフォームのデータサービス収益をAGTの買い戻しに充て、それをユーザー報酬プールに注入することで、「顧客需要 → 収益 → 再インセンティブ → より高品質なデータ」というビジネスの好循環を生み出そうとしています。その実際の効果は、エンタープライズ注文の量と買い戻しの透明性に依存します。
このシステムは、データへの貢献を一回限りの労働から、参加型のネットワーク協力へと変革します。提供者、ステーカー、プロジェクトは、同一のルールセットの下で競争し協力します。これは、従来のSaaS型ラベリングプラットフォームではネイティブに実現できないWeb3の構造です。
Alaya AIと従来のAIデータプラットフォームの違い
| 側面 | Alaya AI | 従来のプラットフォーム(例:Scale AI、Labelbox) |
|---|---|---|
| 組織形態 | 分散型コミュニティ+オープンプラットフォーム | 集中運用とエンタープライズ契約 |
| インセンティブ | AGT、AIA、NFT、ゲーミフィケーション | 主に法定通貨による報酬 |
| データのカスタマイズ | カスタムトークンプール、P2Pリクエスト | 標準SLAと調達プロセス |
| 所有権の表現 | NFTとオンチェーン記録が貢献の株式性を強調 | 契約条件で定義 |
| 自動化 | 3層自動ラベリング+RLHF+エキスパートレビュー | 成熟したパイプライン、多くの垂直分野の深い事例(例:自動車) |
| クライアントタイプ | Web3ネイティブおよび中小AIチーム、エンタープライズ拡大中 | 大手テクノロジー企業、政府プロジェクトが中心 |
Alaya AIの優位性は、ロングテール需要、国境を越えた対応、迅速なプール形成、そして透明性の高いインセンティブにあります。一方、従来のプラットフォームは、納品の確実性、法的な成熟度、業界認証、そして超大規模プロジェクトの経験で優れています。分散型ネットワークは、すべてのシナリオで中央集権型のサプライヤーを置き換えるわけではなく、「予算に敏感で、垂直ニッチな、暗号資産ネイティブ」という交差点において差別化を確立します。
さらに、Alayaは無限のデータ量を積み上げるのではなく、高忠実度の垂直データを重視しており、これは従来の「大規模データセット」競争のロジックとは異なります。このアプローチは、パラメータ効率の良い小型モデルやエージェントにとって有利ですが、クライアントがハイブリッドパイプライン(自動+エキスパート)の価格設定と納品モデルを受け入れる必要もあります。
分散型AIデータネットワークが直面する課題
アーキテクチャは完成されていますが、分散型AIデータネットワークは現実的な制約に直面しています。
-
品質と規模のバランス:数百万の登録ユーザーのうち、一貫して高品質なラベリングを提供する者の割合を外部から検証することは困難です。インセンティブがボリュームファーミングを促進する方向に働けば、AIクライアントのリニューアルやネットワークの評判に悪影響を及ぼします。
-
エンタープライズ導入の壁:法務、SOC2、専任プロジェクトマネージャー、事故補償などは、エンタープライズ調達の標準要件です。オンチェーン上の透明性だけでは大口契約を獲得するには不十分であり、監査可能な実績の継続的な蓄積が必要です。
-
ユーザーエクスペリエンスの複雑さ:ウォレット、NFT、デュアルトークン(AGT/AIA)、ステーキング、交換ルールは、新規ユーザーの学習コストを高め、非Web3ユーザーの流入を制限する可能性があります。
-
規制の不確実性:国境を越えたデータ、トークンで報酬が支払われる労働、医療などの機密データに関するコンプライアンスは国によって異なります。政策の変化は、運営地域やトークンの設計に影響を与える可能性があります。
-
流動性とインセンティブの持続可能性:AGTの時価総額と取引量は、市場全体と比較するとまだ小規模です。プラットフォームの収益と買い戻しが、アンロックや交換による供給に追いつかない場合、インセンティブは内部のキャッシュフローではなく、新規ユーザーに依存することになる可能性があります。
-
技術的リスク:スマートコントラクトの脆弱性、ウォレットのバインディングエラーによる交換の受け取り不能、ロングテールカテゴリにおける自動ラベリングモデルのエラー増幅などには、継続的なエンジニアリング投資が必要です。
-
競争圧力:中央集権型の大手企業は潤沢な資金と高い顧客維持率を持っています。また、他のWeb3データプロジェクトも同様のストーリーを競っており、差別化は実際に納品されたデータによって証明されなければなりません。
Alaya AI技術の今後の発展方向
公式ロードマップと2025〜2026年の動向を踏まえると、技術の進化は以下の方向に焦点を当てると考えられます。
-
自動ラベリングとRLHFの深い統合:動的ビジョン、多言語、エージェントフィードバックデータのリアルタイム処理能力を向上させ、「収集→ラベリング→モデルへの再デプロイ」のサイクルを短縮します。
-
ODPとソーシャルデータコラボレーション:データセットの立ち上げから、より活発な取引、共有、コラボレーション機能へと拡張し、ネットワーク効果を強化します。
-
DAOとガバナンスの強化:より多くの意思決定(例:自動ラベリング機能の優先順位、経済パラメータ)をAGTステーカーの投票に委ね、コミュニティ主権というストーリーの信頼性を高めます。
-
マルチチェーンとコンピュートエコシステムの連携:DePIN、分散コンピューティング(例:Akash、Golem)、モデルマーケットプロトコル(例:Bittensor)との統合を進め、「データ→トレーニング→推論」のオープンスタックを探求し、単一プラットフォームへのロックインを低減します。
-
エージェント時代へのポジショニング:高忠実度でヒューマン・イン・ザ・ループのデータをエージェントの推論基盤として強化し続け、リアルタイムエージェント学習フレームワークと連携して、高速・低速の二重ループを形成します。
-
エンタープライズコンプライアンスの強化:ZK暗号化、来歴監査、エキスパートレビューの適用範囲を拡大し、医療や金融など高度に規制された業界での受注を目指します。
2026年の毎月のAGT交換のようなメカニズムは、運用面が一定のリズムで提供者の期待を維持しようとしていることを示しています。技術面がこの運用のリズムに追いつくかどうかは、自動ラベリングの精度、タスクルーティングアルゴリズム、エキスパート層への持続的な投資にかかっています。
まとめ
Alaya AIの分散型AIデータネットワークは、本質的には階層化された協調システムです。アプリケーション層は参加の障壁を低くし、データ生成層は自動ラベリングと分散サンプリングによって効率を高め、インテリジェント最適化層はRLHFを通じて人間の知識を取り込み、オンチェーン協調層はAGT、NFT、ガバナンスルールによってインセンティブとセキュリティを調整します。オープンデータプラットフォームは、ネットワークをタスクプラットフォームから構成可能なデータマーケットプレイスへと進化させ、モデルステーキングプールはコミュニティの資本と労働をモデルのファインチューニングループに取り込みます。
その運用ロジックがAI業界にとって持つ意義は、以下の点にあります。高品質な垂直データがボトルネックとなったとき、中央集権的な調達だけではロングテール領域や世界中に散らばったマンパワーをカバーできません。Web3のアーキテクチャは、代替となる供給曲線を提供します。同時に、品質検証、エンタープライズSLA、規制、インセンティブの持続可能性といった課題は現実のものであり、この技術アーキテクチャが「実証可能」な段階から「スケーラブルに商業化可能」な段階へと移行できるかどうかを左右します。
技術的な観察者にとって、Alaya AIを評価する際には、オンチェーンの取引量やユーザー登録数だけでなく、自動ラベリングの検証率、ODPの取引量、エンタープライズ顧客のリニューアル率、買い戻しの実行状況といったハードな指標を追跡することが重要です。これらの指標は総合的に、一つの問いに答えます。すなわち、分散型AIデータネットワークは、効率性と信頼性において、従来型プラットフォームのコアな強みを同時に上回ることができるのか、ということです。
共有
内容


関連記事

ONDOトークン経済モデル:プラットフォームの成長とユーザーエンゲージメントをどのように推進するのか

Render、io.net、Akash:DePINハッシュレートネットワークの比較分析

AI分野におけるRenderの申請理由:分散型ハッシュレートが人工知能の発展を支える仕組み

Plasma(XPL)トークノミクス分析:供給、分配、価値捕捉

0xプロトコルの主要コンポーネントは何でしょうか。Relayer、Mesh、APIアーキテクチャの概要をご紹介します。
