DeepSeek V4-Pro は GPT-5.5 Pro より 98% 低コストでローンチ
DeepSeekは2026年4月24日にDeepSeek-V4-ProとDeepSeek-V4-Flashのプレビュー版を公開した。いずれもオープンウェイトのモデルで、100万トークンのコンテキストウィンドウを備え、同等の西側代替品より大幅に低い価格設定だ。V4-Proモデルの料金は、1,000,000入力トークンあたり$1.74、1,000,000出力トークンあたり$3.48で、同社の公式仕様によればClaude Opus 4.7の約1/20の価格であり、GPT-5.5 Proより98%低い。
モデルアーキテクチャと規模
DeepSeek-V4-Proは合計1.6兆パラメータを備えており、これまでのLLM市場において最大のオープンソース・モデルだ。だが、推論パスで有効化されるのは49 billionパラメータのみで、V3以降に洗練されたDeepSeekのMixture-of-Experts(モード混合の専門家)アプローチを用いている。この設計により、モデル全体を休眠状態に置いたまま、各リクエストに関連する適切な断片だけを活性化できる。これにより、知識の保持能力を維持しつつ計算コストを削減する。
DeepSeek-V4-Flashは、合計2840億パラメータと、13 billionの有効化パラメータでより小規模に動作する。DeepSeekのベンチマークによれば、「より大きな思考予算を与えると、Pro版に匹敵する推論性能を達成する」という。
両モデルは標準機能として100万トークンのコンテキストをサポートしている。これはおよそ750,000語、または「ロード・オブ・ザ・リング」三部作全体に追加のテキストを加えた規模に相当する。
技術革新:大規模な注意機構(Attention Mechanisms)
DeepSeekは、長いコンテキスト処理に固有の計算スケーリング問題に対処するため、同社のGitHub上で公開されている技術論文で詳述されている2種類の新しいattentionタイプを発明した。
標準的なAIの注意機構は、冷酷なスケーリング問題に直面する。コンテキスト長が2倍になるたびに、計算コストは概ね4倍になる。DeepSeekの解決策は、2つの相補的アプローチを用いる:
**Compressed Sparse Attention(圧縮スパース注意)**は2ステップで動作する。まず、例えば4トークンごとといった具合に、トークンのグループを1つのエントリに圧縮する。次に、全ての圧縮エントリに注意を向けるのではなく、「Lightning Indexer」を使って、任意のクエリに対して最も関連性の高い結果のみを選択する。これにより、モデルのattention範囲は100万トークンから、重要なチャンクのはるかに小さな集合へと削減される。
**Heavily Compressed Attention(強く圧縮された注意)**は、さらに攻めたアプローチで、スパースな選択をせずに128トークンごとを単一のエントリへと圧縮する。細かな情報は失われるものの、非常に安価なグローバルな見通しが得られる。2種類のattentionタイプは交互の層で動作し、モデルが詳細と俯瞰の両方を維持できるようにする。
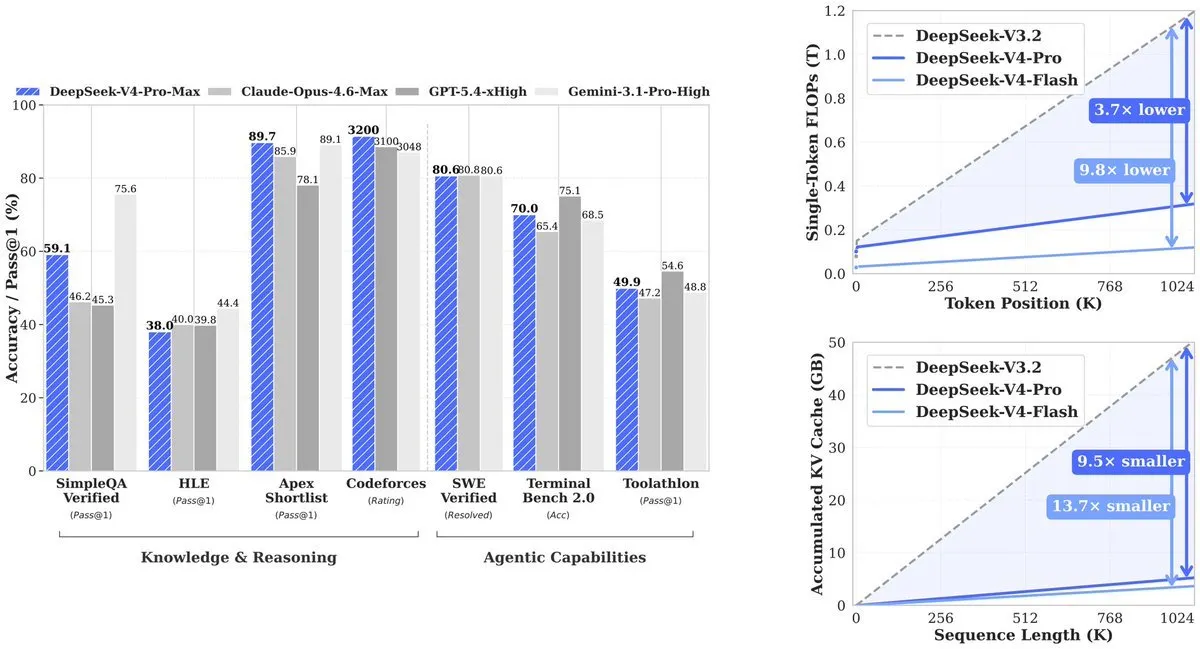
結果:V4-Proは、先行モデルの必要とした計算量 (V3.2) のうち27%を使用する。KVキャッシュ(コンテキストを追跡するためのメモリ)はV3.2の10%まで低下する。V4-Flashはさらに効率を押し上げ、V3.2に比べて計算が10%、メモリが7%だ。
ベンチマーク性能と競争上の立ち位置
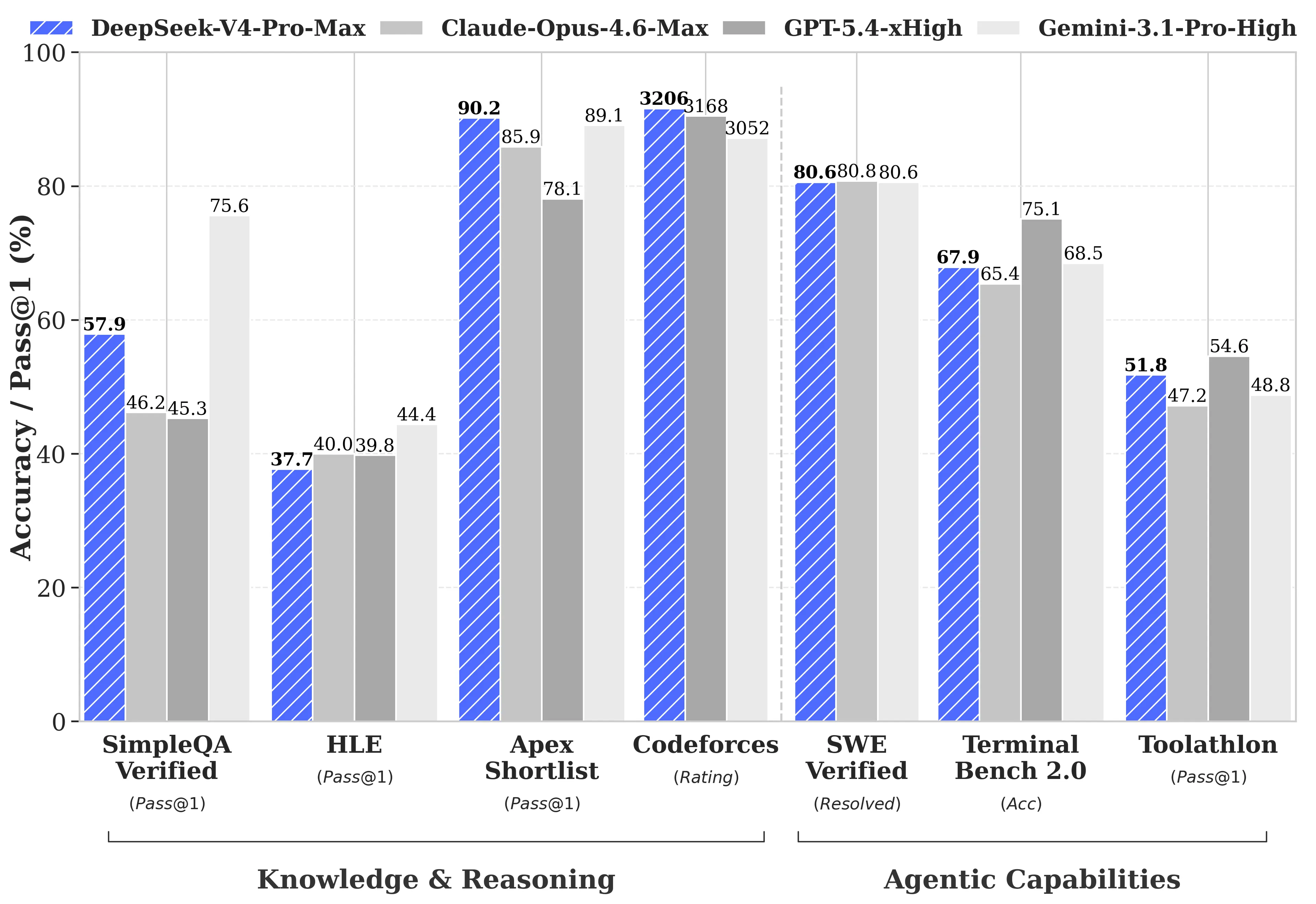
DeepSeekは、GPT-5.4およびGemini-3.1-Proに対する包括的なベンチマーク比較を公開しており、V4-Proが競合に劣る領域も含まれている。DeepSeekの技術レポートによれば、推論タスクではV4-Proの推論性能はGPT-5.4およびGemini-3.1-Proに対して、約3〜6か月遅れている。
V4-Proがリードする点:
- Codeforces (競技プログラミング): V4-Proは3,206点を獲得し、実際の人間のコンテスト参加者の中では約23位だった
- Apex Shortlist (選りすぐりの数学およびSTEM問題): Opus 4.6の85.9%およびGPT-5.4の78.1%に対し、90.2%の合格率
- SWE-Verified (GitHub issue解決): 80.6%で、Claude Opus 4.6と同率
V4-Proが劣る点:
- MMLU-Pro (マルチタスキング): Gemini-3.1-Proは91.0%であるのに対し、V4-Proは87.5%
- GPQA Diamond (専門知識): Geminiは94.3に対し、V4-Proは90.1
- Humanity’s Last Exam (大学院レベル): Gemini-3.1-Proは44.4%であるのに対し、V4-Proは37.7%
長いコンテキストのタスクでは、V4-Proはオープンソース・モデルの中でリードしており、CorpusQA (100万トークンでの実際のドキュメント解析をシミュレート) でGemini-3.1-Proに勝つ。しかし、長文の奥深くに埋め込まれた特定情報の検索を測定するMRCRではClaude Opus 4.6に敗れる。
エージェント型およびコーディング能力
V4-ProはClaude Code、OpenCode、その他のAIコーディングツールで動かせる。DeepSeekの、V4-Proを主なコーディングエージェントとして使った85人の開発者に関する社内調査によると、52%が「デフォルトモデルとして準備ができている」と回答し、39%が「はい寄り」と答え、9%未満が「いいえ」と答えた。DeepSeekの社内テストでは、V4-ProはClaude Sonnetを上回り、エージェント型コーディングタスクではClaude Opus 4.5に迫ることが示された。
Artificial Analysisは、GDPval-AAにおいてGDPval-AAの対象となる全オープンウェイト・モデルの中でV4-Proを1位にランク付けした。これは、金融・法務・研究タスクにまたがる経済的に価値のある知識作業をテストするベンチマークだ。V4-Pro-Maxは1,554 Eloを獲得し、GLM-5.1 (1,535) およびMiniMaxのM2.7 (1,514) を上回った。同一ベンチマークでのClaude Opus 4.6は1,619だ。
V4は「interleaved thinking(インタリーブ推論)」を導入する。これはツール呼び出し間を通して、推論の完全なチェーン・オブ・ソートを保持する。以前のモデルでは、エージェントが複数回のツール呼び出し――例えばウェブ検索、コード実行、そして再度検索――を行うと、ラウンド間でモデルの推論コンテキストがフラッシュされていた。V4はステップをまたいで推論の連続性を維持し、複雑な自動化ワークフローでのコンテキスト喪失を防ぐ。
競争環境と価格の文脈
V4のリリースは、AI分野での大きな動きのさなかに到来する。Anthropicは2026年4月16日にClaude Opus 4.7を出荷した。OpenAIは2026年4月23日にGPT-5.5をローンチし、GPT-5.5 Proの価格は $30 1,000,000入力トークンあたり$180 および (1,000,000出力トークンあたり) とされた。GPT-5.5はTerminal Bench 2.0 (82.7% 対 70.0%) でV4-Proを上回る。これは、複雑なコマンドラインのエージェントワークフローをテストする。
Xiaomiは2026年4月22日にMiMo V2.5 Proをリリースし、フルのマルチモーダル機能 $1 image, audio, video$3 を (1,000,000トークンあたり入力) および 1,000,000トークンあたり出力 で提供した。同日、TencentはGPT-5.5と同じ日にHy3をリリースした。
価格面の見取り図として:Cline CEOのSaoud Rizwanは、もしUberがClaudeの代わりにDeepSeekを使っていたなら、その2026年のAI予算(報道では4か月分の使用に十分だった)であっても、7年は持ったはずだと述べた。
![Pricing comparison and Uber budget analysis]https://img-cdn.gateio.im/social/moments-0ee5a4bf95-cbc5686e31-8b7abd-badf29
デプロイと提供状況
V4-ProとV4-FlashはいずれもMITライセンスで、Hugging Faceで利用可能だ。現時点では両モデルともテキストのみ対応であり、DeepSeekはマルチモーダル機能の開発に取り組んでいると述べている。両モデルはローカルのハードウェア上で無料で実行でき、また会社のニーズに基づいてカスタマイズも可能だ。
DeepSeekの既存のdeepseek-chatおよびdeepseek-reasonerエンドポイントは既に、非思考モードおよび思考モードそれぞれでV4-Flashへルーティングしている。旧のdeepseek-chatおよびdeepseek-reasonerエンドポイントは2026年7月24日に廃止される。
DeepSeekはV4を一部でHuaweiのAscendチップスで学習させており、米国の輸出規制を回避した。同社は、2026年後半に950の新しいスーパーノードがオンラインになると、Proモデルのすでに低い価格がさらに下がると述べた。
実務上の含意
企業にとっては、価格体系により費用対効果の計算が変わる可能性がある。入力1,000,000トークンあたり$1.74でオープンソースのベンチマークをリードするモデルは、大規模なドキュメント処理、法務レビュー、コード生成パイプラインを、6か月前より大幅に安価にする。100万トークンのコンテキストにより、全コードベースや規制上の提出書類を、複数回の呼び出しに分割せずに単一のリクエストで処理できる。
開発者や個人で作る人にとっては、V4-Flashが主な検討対象だ。入力$0.14、出力$0.28(いずれも1,000,000トークンあたり)では、1年前に予算向けオプションとして検討されていたモデルより安く、多くのタスクでPro版が扱えるものをカバーする。