黄仁勋GTC講演全文:推理の時代到来、ロブスターが新しいオペレーティングシステム
PANews
出典:ウォール街見聞
2026年3月16日、NVIDIA GTC 2026大会が正式に開幕し、NVIDIA創業者兼CEOの黄仁勋(ジェンスン・フアン)が基調講演を行った。
この「AI業界の年次巡礼」と見なされる大会で、黄仁勋はNVIDIAが「チップ会社」から「AIインフラと工場企業」へと変貌を遂げる過程を語った。市場が最も関心を寄せる業績の持続性と成長余地の問題に対し、黄仁勋は未来の成長を支える根底のビジネスロジック――「Token工場経済学」――を詳細に解説した。

業績見通しは極めて楽観的、「2027年には少なくとも1兆ドルの需要」
過去2年間、世界的にAI計算需要は指数関数的に爆発的に拡大した。大規模モデルが「認識」「生成」から「推論」「行動(タスク実行)」へと進化するにつれ、計算能力の消費量は急激に増加している。市場が高い関心を寄せる受注と収益の天井について、黄仁勋は非常に強気の予測を示した。
講演中、黄仁勋は次のように述べた。
昨年の今頃、私は5000億ドルの高確信度の需要を見込んでいると話した。BlackwellとRubinを2026年までカバーしていると。今、まさにこの瞬間に、私は2027年には少なくとも1兆ドルの需要が見込めると確信している。

黄仁勋の兆ドル予測は一時、NVIDIA株価を4.3%以上押し上げた。
さらに、彼はこの数字について補足した。
これは妥当なのか?これについて次に話すつもりだ。実際、供給不足になるほどの需要になると確信している。計算需要はこれよりもはるかに高いはずだ。
黄仁勋は、現在のNVIDIAシステムは「世界最安コストのインフラ」であることを証明していると指摘する。ほぼすべての分野のAIモデルを動かせるNVIDIAの汎用性により、投入された1兆ドルの資金は十分に活用され、長期的なライフサイクルを維持できるという。
現状、NVIDIAの事業の60%はトップ5の超大規模クラウドサービス事業者からのものであり、残りの40%は主権クラウド、企業、工業、ロボット、エッジコンピューティングなど多岐にわたる。
Token工場経済学、ワットあたり性能がビジネスの命運を決める
この1兆ドルの需要の妥当性を説明するために、黄仁勋は世界の企業CEOに対し、新たなビジネス思考を提示した。彼は、未来のデータセンターはもはやファイルの倉庫ではなく、Token(AI生成の基本単位)を生産する「工場」になると指摘する。

黄仁勋は強調した。
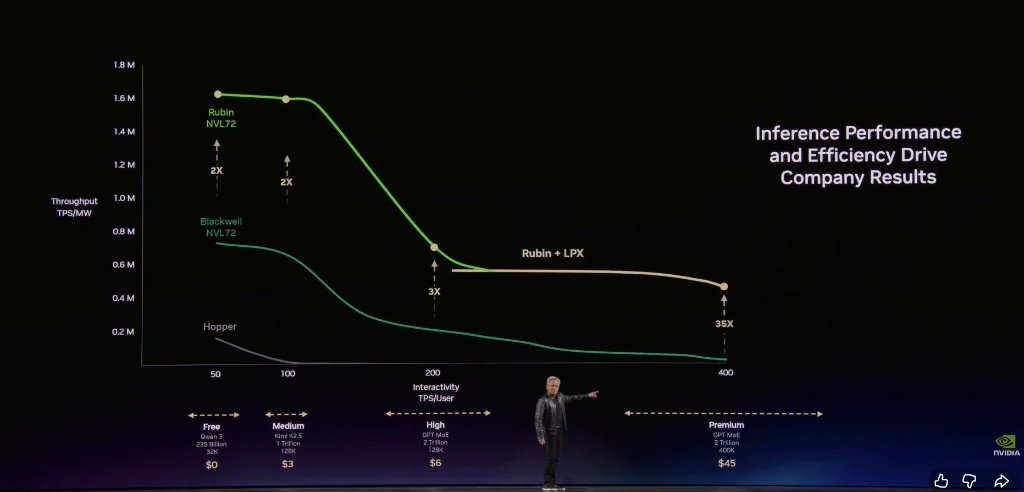
すべてのデータセンター、すべての工場は、定義上電力制約を受けている。一つの1GW(ギガワット)の工場が2GWになることは物理的・原子の法則に反する。固定された電力の下で、誰のワットあたりToken処理能力が高いか、コストが低いかが勝負だ。
彼は、今後のAIサービスを以下のビジネス層に分けて説明した。
無料層(高スループット、低速度)
中級層(~100万Tokenあたり3ドル)
上級層(~100万Tokenあたり6ドル)
高速層(~100万Tokenあたり45ドル)
超高速層(~100万Tokenあたり150ドル)
彼は、モデルが大きくなり、コンテキストが長くなるにつれ、AIはより賢くなるが、Token生成速度は低下すると指摘する。黄仁勋は次のように述べた。
このToken工場において、あなたのスループットとToken生成速度は、翌年の正確な収益に直結する。
黄仁勋は、NVIDIAのアーキテクチャは無料層で極めて高いスループットを実現しつつ、最も価値の高い推論層では性能を35倍に向上させることができると強調した。
Vera Rubinの2年で350倍の加速、Groqが高速推論を補完
この物理的限界の中、NVIDIAは史上最も複雑なAI計算システム「Vera Rubin」を紹介した。黄仁勋は次のように語る。
以前Hopperについて話したとき、チップを掲げて可愛らしいと感じた。でもVera Rubinについて話すときは、システム全体を思い浮かべる。100%液冷のこのシステムでは、従来2日かかっていたラックの設置がわずか2時間に短縮された。
彼は、極致のエンドツーエンドのソフトウェア・ハードウェア協調設計により、Vera Rubinは同一の1GWデータセンター内で驚異的なデータの飛躍を実現したと述べる。
たった2年で、Tokenの生成速度を2200万から7億に引き上げ、350倍の成長を達成した。ムーアの法則が同時期に約1.5倍の向上しかもたらさなかったのに比べ、圧倒的な差だ。
超高速推論(例:1000Tokens/秒)の帯域幅ボトルネックを解決するため、NVIDIAは買収したGroqの最終案を提示した。非対称の分離推論だ。黄仁勋は解説する。
この2つのプロセッサの特徴は全く異なる。Groqチップは500MBのSRAMを持ち、Rubinチップは288GBのメモリを持つ。
彼は、NVIDIAのDynamoソフトウェアシステムにより、大量計算とメモリを必要とする「プリフィル(Pre-fill)」段階をVera Rubinに任せ、遅延に敏感な「デコード」段階をGroqに任せることを示した。企業の計算能力配置についても提言した。
もしあなたの仕事が高スループット中心なら、100%Vera Rubinを使うべきだ。高価値のプログラミングレベルのToken生成が多い場合は、25%のデータセンター規模をGroqに割り当てると良い。
三星の委託生産によるGroq LP30チップはすでに量産段階に入り、Q3の出荷開始を予定している。最初のVera RubinラックはすでにMicrosoft Azure上で稼働中だ。
また、光インターコネクション技術について、黄仁勋は世界初の量産型共封装光学(CPO)スイッチSpectrum Xを披露し、「銅線退き光進」の路線争いに終止符を打った。
我々は、銅ケーブルの生産能力、光チップの生産能力、CPOの生産能力をさらに増やす必要がある。
Agentが従来のSaaSを終結、「年次Token+AIエージェント」がシリコンバレーの標準に
ハードウェアの壁に加え、黄仁勋はAIソフトウェアとエコシステムの革命に多くの時間を割いた。特に、Agent(インテリジェントエージェント)の爆発的な進展についてだ。
彼は、オープンソースプロジェクト「OpenClaw」を「人類史上最も人気のあるオープンソースプロジェクト」と形容し、わずか数週間でLinuxの30年の成果を超えたと語る。黄仁勋は、OpenClawは本質的にエージェントコンピュータの「OS」だと断言する。
彼は次のように断言した。
すべてのSaaS(Software as a Service)企業は、AaaS(Agent-as-a-Service、インテリジェントエージェント)企業に変わる。これを安全に実現するために、NVIDIAは企業向けNeMo Clawリファレンス設計を発表し、戦略エンジンとプライバシールーターを追加した。
一般の職場の人々にとっても、この変革はすぐそこにある。黄仁勋は、未来の職場の新しい姿を描いた。
将来的には、我々の会社のすべてのエンジニアに年間Token予算が必要になるだろう。彼らの基本年収は数十万ドルかもしれないが、その半分程度をToken枠として提供し、10倍の効率向上を実現させる。これがシリコンバレーの新たな採用条件だ:オファーにいくらTokenが付いているか?
最後に、黄仁勋は次世代の計算アーキテクチャ「Feynman」を“リーク”した。銅線とCPOの共同水平拡張を初めて実現し、さらに、英伟达は宇宙空間に展開されるデータセンターコンピュータ「Vera Rubin Space-1」の開発・展開も進めており、AI計算能力の地球外への拡張の想像を完全に開いた。
黄仁勋のGTC 2026基調講演全文(AIツール支援による翻訳):
司会者: ようこそ、英伟达創業者兼CEOの黄仁勋(ジェンスン・フアン)登壇。
黄仁勋、創業者兼CEO:
GTCへようこそ。皆さんにお伝えしたいのは、これは技術の大会だということだ。これだけ多くの人が早朝から並び、皆さんがここにいることに私は非常に喜びを感じている。
GTCでは、技術、プラットフォーム、エコシステムの3つのテーマに焦点を当てる。英伟达は現在、CUDA-Xプラットフォーム、システムプラットフォーム、そして最新のAI工場プラットフォームの3つを持つ。
正式に始める前に、プレイベントの司会を務めたConvictionのSarah Guo、シリコンバレーのVCであるAlfred Lin(英伟达の最初のベンチャーキャピタリスト)、そして英伟达の最初の主要機関投資家Gavin Bakerに感謝したい。彼らは深い技術洞察を持ち、エコシステム全体に大きな影響を与えている。もちろん、今日招待したゲストの皆さんにも感謝を申し上げる。スター選手のチームだ。
また、今日参加しているすべての企業に感謝したい。英伟达はプラットフォーム企業であり、技術、プラットフォーム、豊富なエコシステムを持つ。今日の参加企業は、価値10兆ドルの産業のほぼすべてのプレイヤーを代表し、450社がこのイベントを後援している。
この大会には、1000の技術フォーラムと2000人の講演者が登壇し、AIの「五層ケーキ」アーキテクチャの各層――土地、電力、データセンターの基盤から、チップ、プラットフォーム、モデル、そして最終的に産業を牽引するさまざまなアプリケーションまで――を網羅する。
CUDA:20年の技術蓄積
すべての始まりはここにある。今年はCUDA誕生20周年だ。
20年にわたり、私たちはこのアーキテクチャの研究開発に取り組んできた。CUDAは革命的な発明だ――SIMT(Single Instruction Multiple Thread)技術により、開発者はスカラーコードを書き、それをマルチスレッドアプリに拡張できる。従来のSIMDアーキテクチャよりもはるかにプログラミングが容易だ。最近では、テンソルコア(Tensor Core)をより簡単にプログラムできるTiles機能や、AIに不可欠な数学演算構造も追加された。現在、CUDAには数千のツール、コンパイラ、フレームワーク、ライブラリがあり、オープンソースコミュニティには数十万の公開プロジェクトが存在し、あらゆる技術エコシステムに深く統合されている。
この図は、英伟达の100%戦略ロジックを示している。最も難しく、最も重要な要素は、図の底部にある「搭載量」だ。20年の歳月を経て、私たちは世界中で数億のGPUと計算システムをCUDA上で稼働させてきた。
私たちのGPUはすべてのクラウドプラットフォームをカバーし、ほぼすべてのコンピュータメーカーや産業にサービスを提供している。CUDAの巨大な搭載量こそ、この回転輪の加速の根幹だ。搭載量は開発者を惹きつけ、新たなアルゴリズムとブレークスルーを生み出し、その結果、新たな市場とエコシステムを形成し、より多くの企業を引き込み、搭載量はさらに拡大していく――このサイクルは加速度的に進行している。
英伟达のライブラリのダウンロード数は驚異的な速度で増加し、その規模と成長率はともに拡大し続けている。この回転輪は、私たちの計算プラットフォームが膨大なアプリケーションと次々に新たなブレークスルーを支える基盤となる。
さらに重要なのは、これらのインフラに長寿命をもたらすことだ。理由は明白だ。NVIDIA CUDA上で動作するアプリは非常に多様で、AIのライフサイクルの各段階、さまざまなデータ処理プラットフォーム、科学的問題解決器などを網羅している。したがって、一度英伟达GPUを導入すれば、その実用価値は非常に高い。これが、6年前にリリースしたAmpereアーキテクチャGPUのクラウド価格がむしろ上昇している理由だ。
このすべての根底にあるのは、搭載量の巨大さと回転輪の強さ、そして広範な開発者エコシステムだ。これらの要素が相乗効果を生み出し、ソフトウェアの継続的な更新とともに、計算コストは常に低下していく。高速化された計算はアプリの性能を大きく向上させるとともに、長期的なソフトウェアのメンテナンスと改善により、ユーザーは初期の性能向上だけでなく、継続的なコスト低減も享受できる。私たちは、全世界のすべてのGPUに長期的なサポートを提供したいと考えている。なぜなら、それらはアーキテクチャ上完全に互換性があるからだ。
こうした取り組みを続ける理由は、搭載量が非常に大きいためだ。新たな最適化を行うたびに、何百万ものユーザーに恩恵をもたらすことができる。このダイナミックな組み合わせにより、英伟达のアーキテクチャは、カバレッジを拡大し続けるとともに、自身の成長を加速させ、最終的には計算コストを引き下げ、新たな成長を促進している。CUDAはこのすべての中心だ。
GeForceからCUDAへ:25年の進化の軌跡
私たちとCUDAの旅は、実は25年前に始まっている。
GeForce――多くの人がこの名前とともに育っただろう。GeForceは英伟达の最も成功したマーケティングプロジェクトだ。私たちは、あなたたちがまだ製品を買えなかった頃から、未来の顧客を育ててきた。あなたたちの親が英伟达の最初のユーザーとなり、年を追うごとに製品を購入し続け、やがて優秀なコンピュータサイエンティストとなり、真の顧客・開発者となった。
これが25年前にGeForceが築いた基盤だ。25年前、私たちはプログラマブルシェーダ(Shader)を発明した。これは、アクセラレータをプログラム可能にした明白かつ意義深い発明であり、世界初のプログラマブルアクセラレータ、ピクセルシェーダだ。その5年後、私たちはCUDAを創出した。これは私たちにとって最も重要な投資の一つだ。当時、資金は限られていたが、利益の大部分をこのために投じ、CUDAをGeForceからすべてのコンピュータに拡張しようとした。私たちがこれほどまでに固執したのは、その潜在能力を深く信じていたからだ。初期は苦難の連続だったが、13世代、20年にわたり信念を貫き、今やCUDAはあらゆる場所に浸透している。
ピクセルシェーダはGeForceの革命を推進した。そして約8年前、私たちはRTXをリリースした。これは現代のコンピュータグラフィックス時代におけるアーキテクチャの全面革新だ。GeForceはCUDAを世界中に届け、その結果、Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton、Andrew Ngなど多くの学者がGPUを深層学習の加速器として発見し、10年前のAIブームの火付け役となった。
10年前、私たちはプログラマブルシェーダと2つの新理念を融合させた。一つはハードウェアのレイトレーシング(Ray Tracing)だ。これは技術的に非常に挑戦的だった。もう一つは、約10年前に予見したAIの計算革命だ。GeForceがAIを世界中に届けたように、AIは今や逆に、コンピュータグラフィックスの実現方式を根底から変えつつある。
今日、私は皆さんに未来を示す。次世代のグラフィックス技術、「神経レンダリング(Neural Rendering)」だ。これは3DグラフィックスとAIの深い融合だ。これがDLSS 5だ。ご覧ください。
神経レンダリング:構造化データと生成AIの融合
驚くべきことではないか?これにより、コンピュータグラフィックスは新たな命を吹き込まれる。
私たちは何をしたのか?制御可能な3Dグラフィックス(仮想世界のリアルな基盤)と、その構造化データを結びつけ、生成式AIと確率計算を融合させた。完全に決定論的な側面と、確率的で非常にリアルな側面を一体化し、構造化データによる正確な制御とリアルタイム生成を実現した。結果として、コンテンツは美しく、驚くほどリアルでありながら、完全に制御可能だ。
構造化情報と生成式AIの融合は、さまざまな産業で繰り返し現れるだろう。構造化データは信頼できるAIの基盤だ。
構造化データと非構造化データの高速化プラットフォーム
次に、技術アーキテクチャの図を見てみよう。
構造化データ――皆さんも馴染みのSQL、Spark、Pandas、Velox、Snowflake、Databricks、Amazon EMR、Azure Fabric、Google BigQueryなどの重要プラットフォームが扱うデータフレーム(Data Frame)だ。これらは巨大な表計算のようなもので、ビジネスのすべての情報を担い、企業の計算の基本的な事実(Ground Truth)となる。
AI時代においては、AIがこれらの構造化データを使い、極限まで高速化する必要がある。過去は、構造化データ処理の高速化は企業の効率化のためだったが、未来のAIは人間を超える速度でこれらのデータを利用し、AIエージェントも大量に構造化データベースを呼び出す。
非構造化データは、ベクトルデータベース、PDF、動画、音声など、世界のほとんどのデータ形態を構成する。毎年生成されるデータの約90%は非構造化データだ。過去には、これらのデータはほぼ使い物にならなかった。読み取ってファイルシステムに保存するだけだった。クエリも検索もできず、意味や文脈を理解し索引付けする術もなかった。だが今や、AIはこれを可能にしている。多モーダル認知と理解技術を駆使し、PDFの内容を読み取り、その意味を理解し、より大きな構造に埋め込むことができる。
NVIDIAはこれに対応し、2つの基盤ライブラリを作った。
- cuDF:データフレームや構造化データの高速処理
- cuVS:ベクトルストレージ、セマンティックデータ、非構造化AIデータの処理
これらのプラットフォームは、今後最も重要な基盤の一つとなる。
本日、複数の企業と協業を発表した。IBM――SQL言語の発明者は、cuDFを使ってWatsonX Dataプラットフォームを高速化。Dellは、cuDFとcuVSを統合したDell AIデータプラットフォームを共同開発し、NTT Dataの実証プロジェクトで大幅な性能向上を実現。Google Cloudは、Vertex AIだけでなくBigQueryも高速化し、Snapchatと協力して計算コストを約80%削減した。
高速化計算のメリットは三位一体だ:速度、規模、コスト。これはムーアの法則の論理と一脈通じる――高速化により性能を飛躍的に向上させつつ、アルゴリズムの最適化を続け、すべての人が継続的に計算コストの低減を享受できる。
英伟达は高速計算プラットフォームを構築し、多数のライブラリを集積している。RTX、cuDF、cuVSなどだ。これらのライブラリは、世界中のクラウドサービスやOEM体系に統合され、グローバルユーザーに届けられている。
クラウドサービス事業者との深い連携
主要クラウド事業者との協業例。
Google Cloud:Vertex AIとBigQueryの高速化を推進し、JAX/XLAと深く連携。PyTorchでも優れたパフォーマンスを発揮――英伟达は、PyTorchとJAX/XLAの両方で最も優れた加速器だ。Base10、CrowdStrike、Puma、Salesforceなどの顧客をGoogle Cloudエコシステムに導入。
AWS:EMR、SageMaker、Bedrockの高速化を推進し、深く連携。今年特に注目すべきは、OpenAIをAWSに導入し、AWSクラウドの消費を大きく促進、OpenAIの地域展開と計算規模拡大を支援。
Microsoft Azure:英伟达の100PFLOPS超級スーパーコンピュータはAzure上に最初に展開された超級計算機であり、OpenAIとの協力の礎となった。AzureのクラウドサービスとAIファウンドリーの高速化を推進し、Azure地域の拡張やBing検索との連携も深めている。特に、私たちの「Confidential Computing(秘密計算)」能力――運営者さえもユーザーデータやモデルを閲覧できなくする――は、世界初のサポートGPUであり、OpenAIやAnthropicのモデルを安全にクラウド展開できる。例として、SynopsysのEDAやCADワークフローの高速化も実現し、Microsoft Azureに展開済み。
Oracle:英伟达はOracleの最初のAI顧客だ。AIクラウドの概念を初めて説明できたことを誇りに思う。その後、Cohere、Fireworks、OpenAIなど多くのパートナーを導入。
CoreWeave:世界初のAIネイティブクラウド。GPUホスティングとAIクラウドサービスに特化し、優れた顧客層と高い成長を誇る。
Palantir+Dell:三者連携で新たなAIプラットフォームを構築。PalantirのOntology PlatformとAIプラットフォームを基盤とし、いかなる国や気隙隔離環境でも、完全ローカルでAIを展開可能。データ処理(ベクトル化・構造化)からAIの高速計算まで、全てをカバー。
英伟达は、これらのクラウド事業者と深い協力関係を築き、顧客をクラウドに導入するエコシステムを形成している。
垂直統合と横展開:英伟达のコア戦略
英伟达は、世界初の垂直統合かつ横展開の企業だ。
このモデルの必要性は非常にシンプルだ。高速計算はチップの問題でもシステムの問題でもなく、アプリケーションの加速に他ならない。CPUはコンピュータ全体を高速化できるが、その道はすでに行き詰まった。未来は、アプリケーションや特定分野に特化した加速を通じてのみ、性能の飛躍とコストの低減を持続できる。
だからこそ、私たちは一つ一つのライブラリ、分野、垂直産業に深く入り込み、理解し、アルゴリズムを深く理解し、それをあらゆるシナリオに展開できる必要がある――データセンター、クラウド、オンプレ、エッジ、ロボットシステムまで。
同時に、英伟达は横展開も積極的に行い、技術をパートナーのプラットフォームに統合し、世界中の恩恵を享受させる。
今回のGTCの参加者構成は、これを如実に示している。最も多いのは金融サービス業界――彼らは開発者を求めている。私たちのエコシステムは、上流・下流のサプライチェーンを網羅している。創立50年、70年、150年の企業も、昨年は史上最高の年を迎えた。私たちは、非常に重要な、非常に大きな変革の始まりに立っている。
CUDA-X:各産業の高速計算エンジン
各垂直分野において、英伟达は深く展開している。
- 自動運転:範囲広く、影響も大きい
- 金融:クオンツ投資は、人工的特徴工学からスーパーコンピュータ駆動の深層学習へと移行し、「Transformer時代」を迎える
- 医療:AIによる薬剤発見、診断支援、医療カスタマーサポートなど、「ChatGPT時代」を迎える
- 工業:世界最大の建設ラッシュが進行中。AI工場、半導体工場、データセンターが次々と稼働
- エンタメ・ゲーム:リアルタイムAIプラットフォームによる翻訳、ライブ配信、ゲームインタラクション、スマートショッピング代理
- ロボット:10年以上の蓄積。訓練用コンピュータ、シミュレーション用コンピュータ、搭載用コンピュータの3大アーキテクチャを完備。今回の展示には110台のロボットが登場
- 通信:約2兆ドル規模の産業。基地局は単なる通信機能からAIインフラへと進化。関連プラットフォーム「Aerial」は、ノキアやT-Mobileと深く連携
これらすべての分野のコアは、我々のCUDA-Xライブラリだ。これこそ、英伟达がアルゴリズム企業としての根幹を成す資産だ。これらのライブラリは、計算プラットフォームの実用価値を各産業で発揮させるための最重要資産だ。
中でも最も重要なライブラリの一つがcuDNN(CUDA深層ニューラルネットワークライブラリ)だ。これにより、AIは一大ブレークスルーをもたらし、現代AIの爆発的進展を引き起こした。
(CUDA-Xデモ映像を再生)
先ほど見たすべてはシミュレーションだ。物理原理に基づくソルバー、AIエージェントの物理モデル、物理AIロボットモデルも含む。すべてがシミュレーションであり、手作業のアニメーションや関節のバインディングは一切ない。これが英伟达のコア能力だ。アルゴリズムの深い理解と計算プラットフォームの有機的結合により、これらの機会を解き放つ。
AIネイティブ企業と新たな計算時代
皆さんは、ウォルマート、ロレアル、JPモルガン・チェース、ロシュ、トヨタなどの産業巨頭を見た一方、未だ聞いたことのない企業も多いだろう。私たちはこれらを総称して「AIネイティブ企業」と呼ぶ。リストは非常に膨大で、OpenAI、Anthropic、そしてさまざまな垂直分野の新興企業も含まれる。
過去2年、この業界は驚異的な飛躍を遂げた。ベンチャーキャピタルの投資額は史上最高の1500億ドルに達し、資金流入の規模は過去最大だ。しかも、単一投資額は数百万ドルから数億ドル、時には数十億ドルにまで跳ね上がった。理由は明白だ。これは史上初めて、これらの企業が大量の計算資源とTokenを必要とし、生成し、価値を高めているからだ。彼らはTokenを創造し、生成し、価値を高めている。
PC革命、インターネット革命、モバイルクラウド革命が時代を画したように、この計算プラットフォームの変革も、次世代の影響力ある企業を生み出すだろう。未来の世界をリードする重要な力となる。
これを推進する三つの歴史的ブレークスルー
過去2年、何が起きたのか?大きく3つだ。
第一:ChatGPT、生成式AIの時代の幕開け(2022年末~2023年)
それは、認識と理解だけでなく、独自のコンテンツも生成できる。私は、生成式AIとコンピュータグラフィックスの融合を示した。生成式AIは、根本的に計算のあり方を変えた――検索から生成へとシフトし、計算アーキテクチャや展開方式、全体の意味合いに深い影響を与えた。
第二:推論AI(Reasoning AI)、代表例はo1
推論能力により、AIは自己反省や計画、問題の分解が可能となる。o1は、生成式AIを信頼できるものにし、実際の情報に基づく推論を可能にした。そのために、入力のコンテキストToken数と思考に使う出力Token数が大幅に増加し、計算量も顕著に拡大した。
第三:Claude Code、最初のインテリジェントエ
免責事項:このページの情報は第三者から提供される場合があり、Gateの見解または意見を代表するものではありません。このページに表示される内容は参考情報のみであり、いかなる金融、投資、または法律上の助言を構成するものではありません。Gateは情報の正確性または完全性を保証せず、当該情報の利用に起因するいかなる損失についても責任を負いません。仮想資産への投資は高いリスクを伴い、大きな価格変動の影響を受けます。投資元本の全額を失う可能性があります。関連するリスクを十分に理解したうえで、ご自身の財務状況およびリスク許容度に基づき慎重に判断してください。詳細は免責事項をご参照ください。
コメント
0/400
コメントなし