Sumber artikel: qubits
 Sumber gambar: Dihasilkan oleh Unbounded AI
Sumber gambar: Dihasilkan oleh Unbounded AI
Drama pertarungan istana OpenAI baru saja berakhir, dan itu akan segera memicu kegemparan lain!
Reuters mengungkapkan bahwa sebelum Altman dipecat, beberapa peneliti menulis surat peringatan kepada dewan direksi yang mungkin telah memicu seluruh insiden:
Model AI generasi berikutnya, yang secara internal bernama Q (diucapkan Q-Star), terlalu kuat dan canggih untuk mengancam umat manusia.
Q * dipimpin oleh tokoh sentral badai ini, Kepala Ilmuwan Ilya Sutskever.
Orang-orang dengan cepat menghubungkan pernyataan Altman sebelumnya di KTT APEC:
Ada empat kali dalam sejarah OpenAI, yang terbaru dalam beberapa minggu terakhir, ketika saya berada di ruangan ketika kami mendorong melalui tabir ketidaktahuan dan mencapai perbatasan penemuan, yang merupakan kehormatan tertinggi dalam karir saya. "
 Q * mungkin memiliki karakteristik inti berikut yang dianggap sebagai langkah kunci di jalan menuju AGI atau superintelligence.
Q * mungkin memiliki karakteristik inti berikut yang dianggap sebagai langkah kunci di jalan menuju AGI atau superintelligence.
- Menerobos keterbatasan data manusia dan dapat menghasilkan sejumlah besar data pelatihan sendiri
- Kemampuan untuk belajar dan meningkatkan secara mandiri
Berita itu dengan cepat memicu diskusi besar, dan Musk juga bertanya dengan tautan.
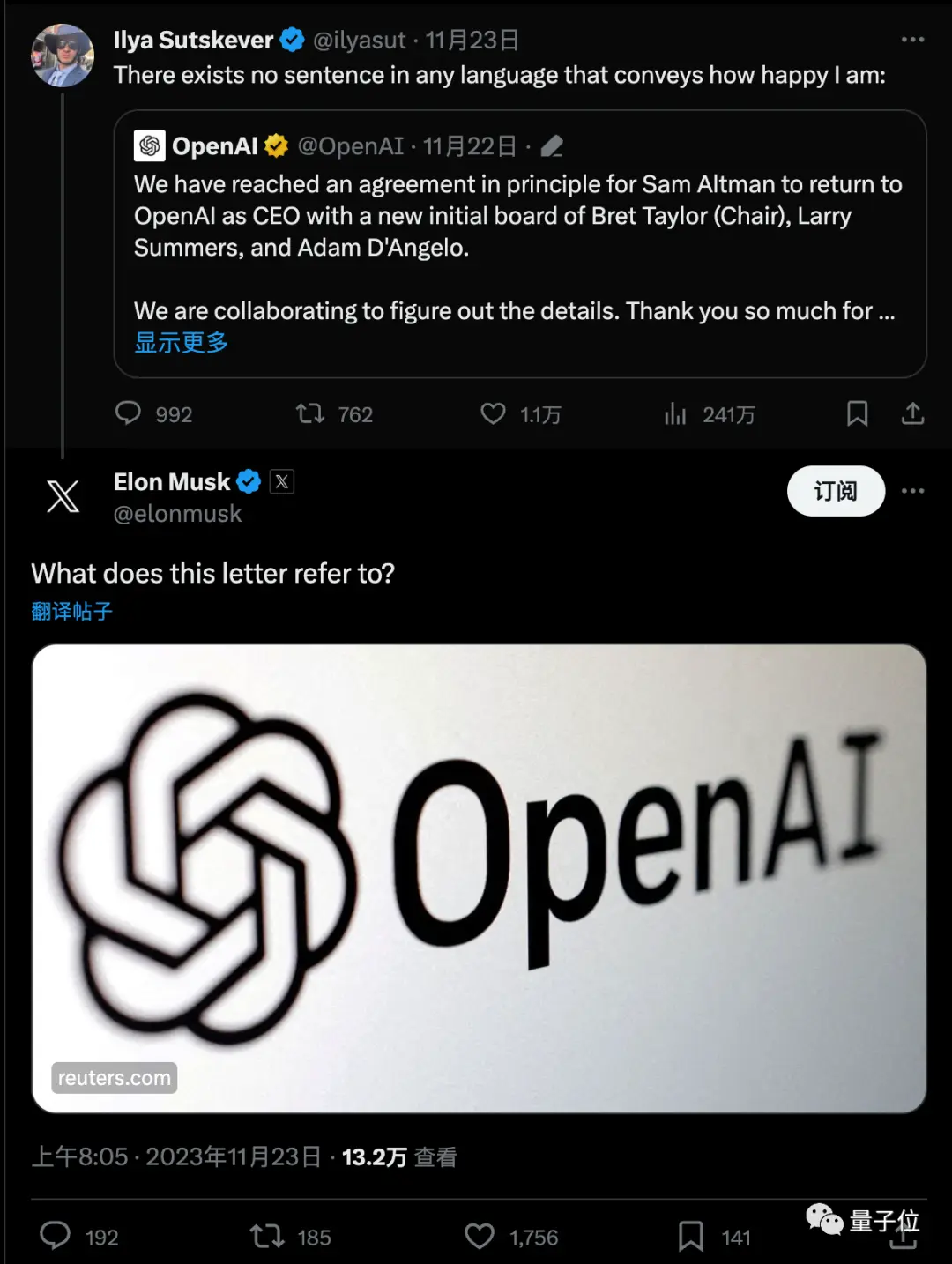 Meme terbaru adalah bahwa, tampaknya dalam semalam, orang-orang telah berubah dari ahli di dewan direksi Ultraman dan OpenAI menjadi ahli Q*.
Meme terbaru adalah bahwa, tampaknya dalam semalam, orang-orang telah berubah dari ahli di dewan direksi Ultraman dan OpenAI menjadi ahli Q*.

Melanggar Batas Data
Menurut berita terbaru dari The Information, Q’* sebelumnya dikenal sebagai GPT-Zero, sebuah proyek yang diprakarsai oleh Ilya Sutskever, dengan nama yang memberi penghormatan kepada Alpha-Zero DeepMind.
Alpha-Zero tidak perlu mempelajari permainan catur manusia, tetapi belajar bermain Go dengan bermain melawan dirinya sendiri.
GPT-Zero memungkinkan model AI generasi berikutnya dilatih menggunakan data sintetis alih-alih mengandalkan data dunia nyata seperti teks atau gambar yang diambil dari internet.
Pada tahun 2021, GPT-Zero secara resmi didirikan, dan tidak banyak berita terkait langsung sejak saat itu.
Tetapi hanya beberapa minggu yang lalu, Ilya menyebutkan dalam sebuah wawancara:
Tanpa terlalu banyak detail, saya hanya ingin mengatakan bahwa keterbatasan data dapat diatasi dan kemajuan akan terus berlanjut.
 Berdasarkan GPT-Zero, Q dikembangkan oleh Jakub Pachocki dan Szymon Sidor.
Berdasarkan GPT-Zero, Q dikembangkan oleh Jakub Pachocki dan Szymon Sidor.
Keduanya adalah anggota awal OpenAI, dan mereka juga anggota pertama yang mengumumkan bahwa mereka akan mengikuti Ultraman ke Microsoft.
 Jakub Pachocki, yang dipromosikan menjadi Direktur Riset bulan lalu, telah menjadi kontributor inti untuk banyak terobosan masa lalunya, termasuk proyek Dota 2 dan pra-pelatihan GPT-4.
Jakub Pachocki, yang dipromosikan menjadi Direktur Riset bulan lalu, telah menjadi kontributor inti untuk banyak terobosan masa lalunya, termasuk proyek Dota 2 dan pra-pelatihan GPT-4.
 Szymon Sidor juga telah mengerjakan proyek Dota 2, dan bio-nya adalah “membangun AGI, baris demi baris”.
Szymon Sidor juga telah mengerjakan proyek Dota 2, dan bio-nya adalah “membangun AGI, baris demi baris”.
 Dalam pesan Reuters, disebutkan bahwa Q* diberikan sumber daya komputasi yang sangat besar untuk dapat memecahkan masalah matematika tertentu. Meskipun kemampuan matematika saat ini hanya di tingkat sekolah dasar, para peneliti sangat optimis tentang kesuksesan di masa depan.
Dalam pesan Reuters, disebutkan bahwa Q* diberikan sumber daya komputasi yang sangat besar untuk dapat memecahkan masalah matematika tertentu. Meskipun kemampuan matematika saat ini hanya di tingkat sekolah dasar, para peneliti sangat optimis tentang kesuksesan di masa depan.
Selain itu, disebutkan bahwa OpenAI telah membentuk tim baru “ilmuwan AI”, yang merupakan penggabungan dari dua tim “Code Gen” dan “Math Gen” di masa-masa awal, dan sedang mengeksplorasi dan mengoptimalkan untuk meningkatkan kemampuan penalaran AI, dan akhirnya melakukan eksplorasi ilmiah.
Tiga tebakan
Tidak ada kata yang lebih spesifik tentang apa sebenarnya Q * itu, tetapi beberapa berspekulasi dari namanya bahwa itu mungkin ada hubungannya dengan Q-Learning.
Q-Learning, yang berasal dari tahun 1989, adalah algoritma pembelajaran penguatan bebas model yang tidak memerlukan pemodelan lingkungan, bahkan untuk fungsi transfer dengan faktor acak atau fungsi penghargaan, dan dapat diadaptasi tanpa perubahan khusus.
Berbeda dengan algoritma pembelajaran penguatan lainnya, Q-Learning berfokus pada pembelajaran nilai masing-masing pasangan tindakan keadaan untuk memutuskan tindakan mana yang akan membawa pengembalian terbesar dalam jangka panjang, daripada langsung mempelajari strategi tindakan itu sendiri.
Tebakan kedua berkaitan dengan rilis OpenAI pada bulan Mei bahwa ia memecahkan masalah matematika melalui “pengawasan proses” daripada “pengawasan hasil”.
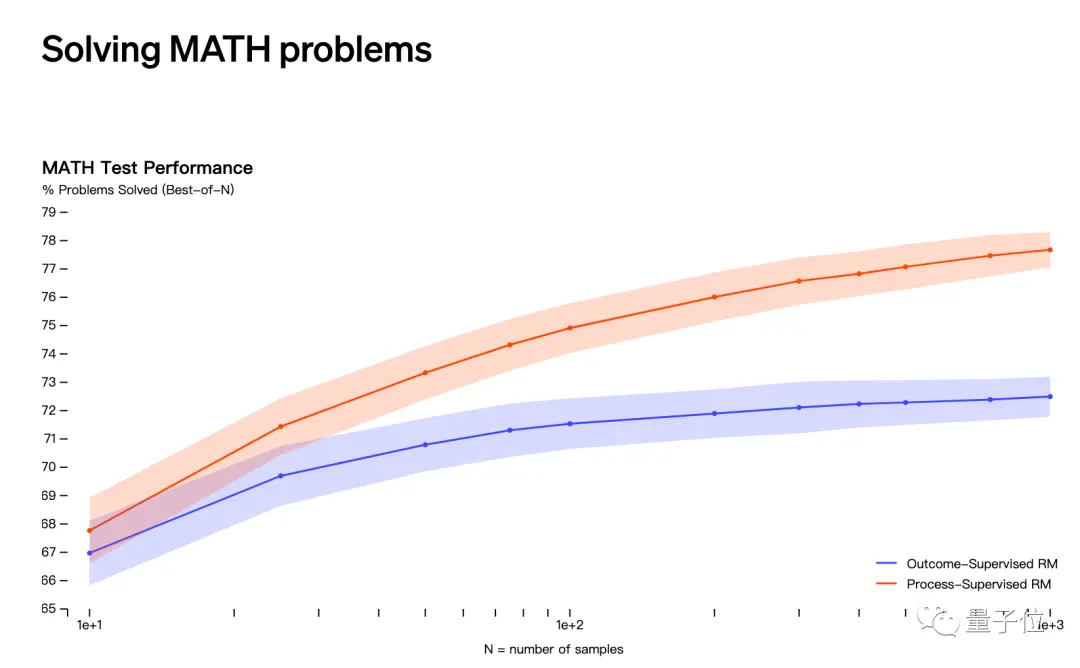 Namun, nama Jakub Pachocki dan Szymon Sidor tidak muncul dalam daftar kontributor penelitian ini.
Namun, nama Jakub Pachocki dan Szymon Sidor tidak muncul dalam daftar kontributor penelitian ini.
 Ada juga spekulasi bahwa Noam Brown, “bapak Depo AI” yang bergabung dengan OpenAI pada bulan Juli, mungkin juga terlibat dalam proyek tersebut.
Ada juga spekulasi bahwa Noam Brown, “bapak Depo AI” yang bergabung dengan OpenAI pada bulan Juli, mungkin juga terlibat dalam proyek tersebut.
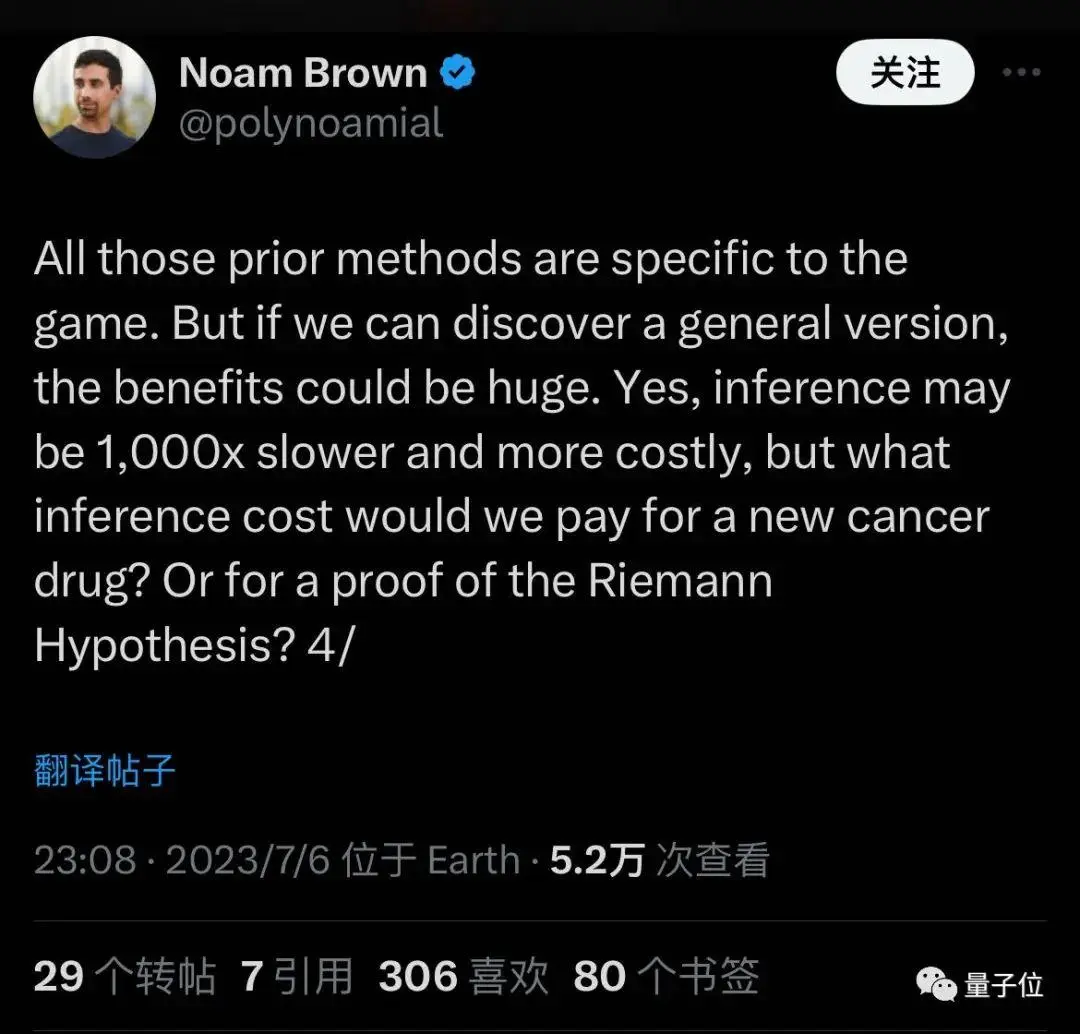
 Ketika dia bergabung, dia mengatakan bahwa dia ingin menggeneralisasi metode yang dulu hanya berlaku untuk permainan, dan penalaran itu mungkin 1000 kali lebih lambat dan lebih mahal, tetapi mungkin menemukan obat baru atau membuktikan dugaan matematika.
Ketika dia bergabung, dia mengatakan bahwa dia ingin menggeneralisasi metode yang dulu hanya berlaku untuk permainan, dan penalaran itu mungkin 1000 kali lebih lambat dan lebih mahal, tetapi mungkin menemukan obat baru atau membuktikan dugaan matematika.
Hal ini sejalan dengan deskripsi yang dikabarkan “membutuhkan sumber daya komputasi yang besar” dan “mampu memecahkan masalah matematika tertentu”.
 Sementara lebih banyak spekulasi masih dibuat, apakah data sintetis dan pembelajaran penguatan dapat membawa AI ke tingkat berikutnya telah menjadi salah satu topik yang paling banyak dibahas di industri.
Sementara lebih banyak spekulasi masih dibuat, apakah data sintetis dan pembelajaran penguatan dapat membawa AI ke tingkat berikutnya telah menjadi salah satu topik yang paling banyak dibahas di industri.
Ilmuwan Nvidia Fan Linxi percaya bahwa data sintetis akan memberikan triliunan token pelatihan berkualitas tinggi, dan pertanyaan kuncinya adalah bagaimana mempertahankan kualitas dan menghindari kemacetan sebelum waktunya.
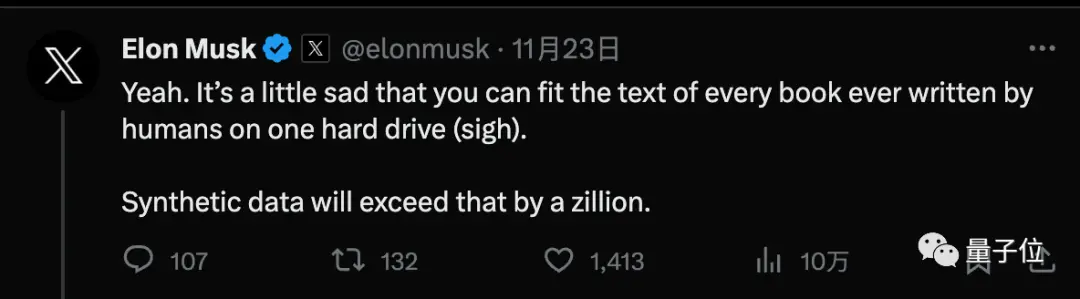
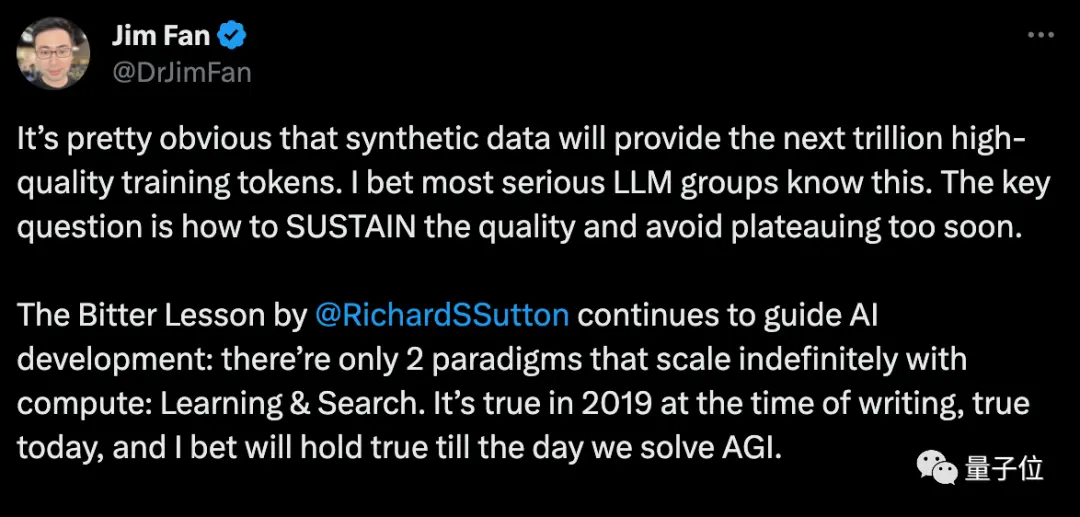 Musk setuju, menyebutkan bahwa setiap buku yang ditulis oleh manusia dapat ditampung di hard drive, dan data sintetis akan jauh melampaui itu.
Musk setuju, menyebutkan bahwa setiap buku yang ditulis oleh manusia dapat ditampung di hard drive, dan data sintetis akan jauh melampaui itu.
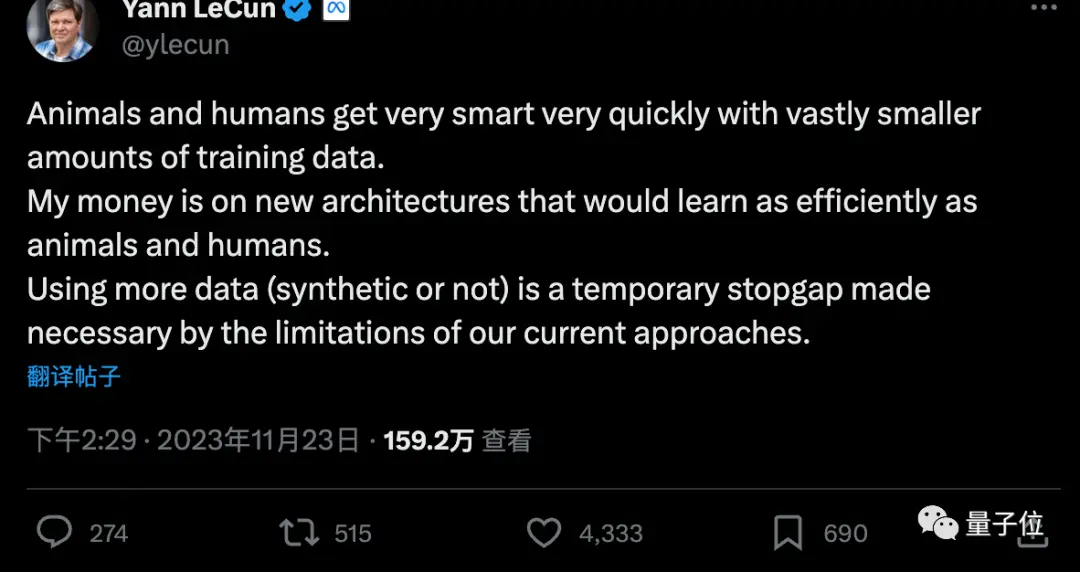
 Tetapi LeCun, salah satu dari tiga serangkai Turing Award, berpendapat bahwa lebih banyak data sintetis adalah tindakan sementara, dan bahwa AI pada akhirnya perlu belajar dengan data yang sangat sedikit, seperti manusia atau hewan.
Tetapi LeCun, salah satu dari tiga serangkai Turing Award, berpendapat bahwa lebih banyak data sintetis adalah tindakan sementara, dan bahwa AI pada akhirnya perlu belajar dengan data yang sangat sedikit, seperti manusia atau hewan.
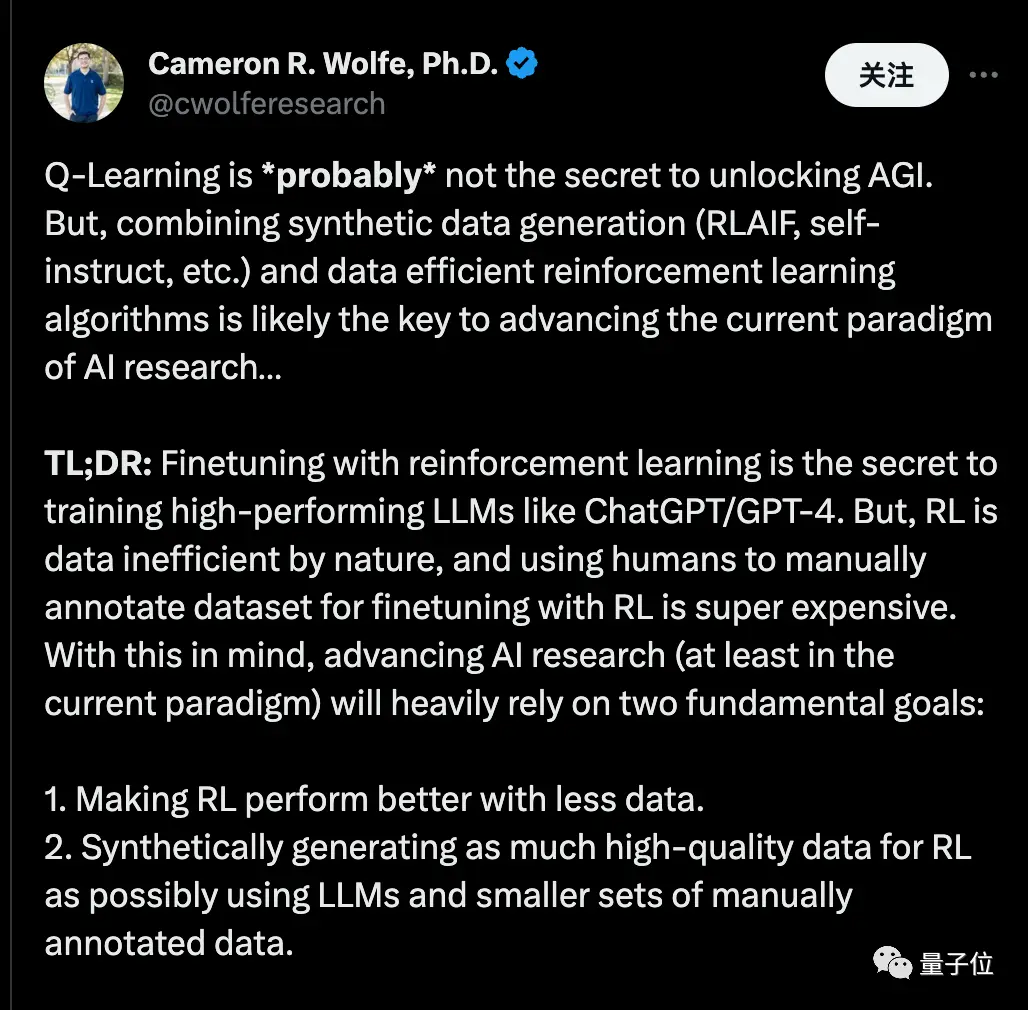
 Cameron R. Wolfe, Ph.D. di Rice University, mengatakan Q-Learning mungkin bukan rahasia untuk membuka kunci AGI.
Cameron R. Wolfe, Ph.D. di Rice University, mengatakan Q-Learning mungkin bukan rahasia untuk membuka kunci AGI.
Tetapi menggabungkan “data sintetis” dengan “algoritma pembelajaran penguatan data-efisien” mungkin menjadi kunci untuk memajukan paradigma penelitian AI saat ini.
Dia mengatakan bahwa fine-tuning melalui pembelajaran penguatan adalah rahasia untuk melatih model besar berkinerja tinggi, seperti ChatGPT / GPT-4. Namun, pembelajaran penguatan secara inheren tidak efisien data, dan sangat mahal untuk menyempurnakan pembelajaran penguatan menggunakan kumpulan data yang diberi label secara manual oleh manusia. Dengan pemikiran ini, memajukan penelitian AI (setidaknya dalam paradigma saat ini) akan sangat bergantung pada dua tujuan mendasar:
- Buat pembelajaran penguatan berkinerja lebih baik dengan lebih sedikit data.
- Mensintesis dan menghasilkan data berkualitas tinggi menggunakan model besar dan sejumlah kecil data beranotasi manual bila memungkinkan.
… Jika kita tetap berpegang pada prediksi paradigma token berikutnya (yaitu pra-terlatih -> SFT -> RLHF) menggunakan Transformer khusus Decoder… Kombinasi kedua metode ini akan memberi semua orang akses ke teknik pelatihan mutakhir, bukan hanya tim peneliti dengan banyak uang!
Satu Hal Lagi
Belum ada seorang pun di dalam OpenAI yang menanggapi pesan Q.
Tetapi Altman baru saja mengungkapkan bahwa dia memiliki beberapa jam percakapan ramah dengan pendiri Quora Adam D’Angelo, yang tetap berada di dewan.
 Tampaknya apakah Adam D’Angelo berada di balik insiden itu, seperti yang dispekulasikan semua orang, kini telah mencapai penyelesaian.
Tampaknya apakah Adam D’Angelo berada di balik insiden itu, seperti yang dispekulasikan semua orang, kini telah mencapai penyelesaian.
Link Referensi:
[1]
[2]
[3]
[4]
[5]
[6]