Fuente del artículo: qubits
 Fuente de la imagen: Generada por Unbounded AI
Fuente de la imagen: Generada por Unbounded AI
¡El drama de la pelea palaciega de OpenAI acaba de terminar, e inmediatamente desencadenará otro alboroto!
Reuters reveló que antes de que Altman fuera despedido, varios investigadores escribieron cartas de advertencia a la junta directiva que pueden haber desencadenado todo el incidente:
El modelo de IA de próxima generación, llamado internamente Q (pronunciado Q-Star), es demasiado poderoso y avanzado para amenazar a la humanidad.
Q* está liderado por la figura central de esta tormenta, el científico jefe Ilya Sutskever.
La gente rápidamente vinculó los comentarios anteriores de Altman en la cumbre de APEC:
Ha habido cuatro ocasiones en la historia de OpenAI, la más reciente en las últimas semanas, en las que estuve en la sala cuando atravesamos el velo de la ignorancia y alcanzamos la frontera del descubrimiento, que fue el mayor honor de mi carrera. "
 Q* puede tener las siguientes características básicas que se consideran un paso clave en el camino hacia la AGI o superinteligencia.
Q* puede tener las siguientes características básicas que se consideran un paso clave en el camino hacia la AGI o superinteligencia.
- Supere las limitaciones de los datos humanos y pueda producir grandes cantidades de datos de entrenamiento por sí mismo
- Capacidad para aprender y mejorar de forma independiente
La noticia rápidamente provocó una gran discusión, y Musk también preguntó con un enlace.
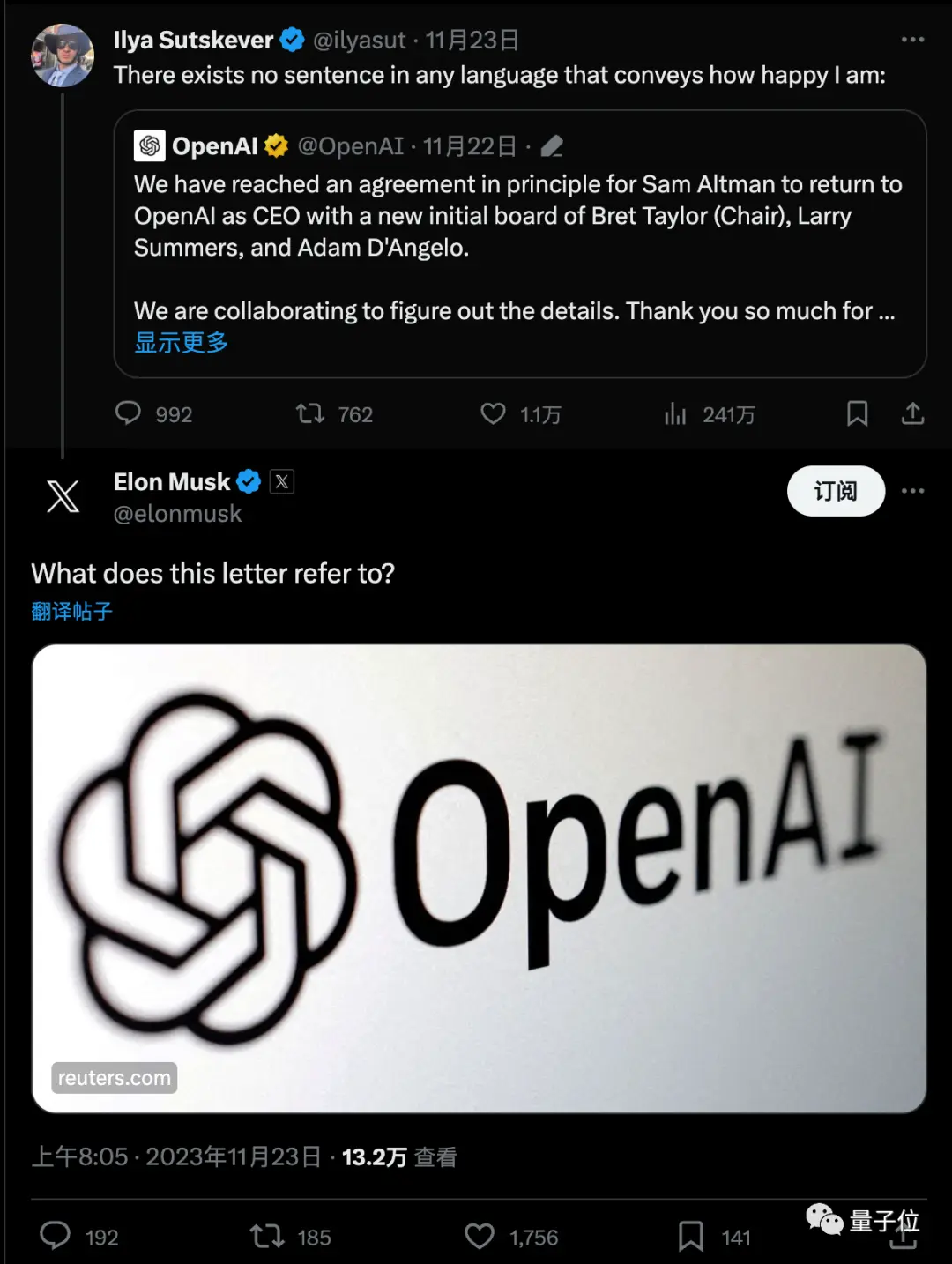 El último meme es que, aparentemente de la noche a la mañana, las personas han pasado de ser expertos en la junta directiva de Ultraman y OpenAI a expertos en Q*.
El último meme es que, aparentemente de la noche a la mañana, las personas han pasado de ser expertos en la junta directiva de Ultraman y OpenAI a expertos en Q*.

Rompiendo los límites de datos
Según las últimas noticias de The Information, Q’* se conocía anteriormente como GPT-Zero, un proyecto iniciado por Ilya Sutskever, con un nombre que rinde homenaje a Alpha-Zero de DeepMind.
Alpha-Zero no necesita aprender partidas de ajedrez humanas, sino que aprende a jugar al Go jugando contra sí mismo.
GPT-Zero permite entrenar modelos de IA de próxima generación utilizando datos sintéticos en lugar de depender de datos del mundo real, como texto o imágenes extraídas de Internet.
En 2021, GPT-Zero se estableció oficialmente y no ha habido muchas noticias directamente relacionadas desde entonces.
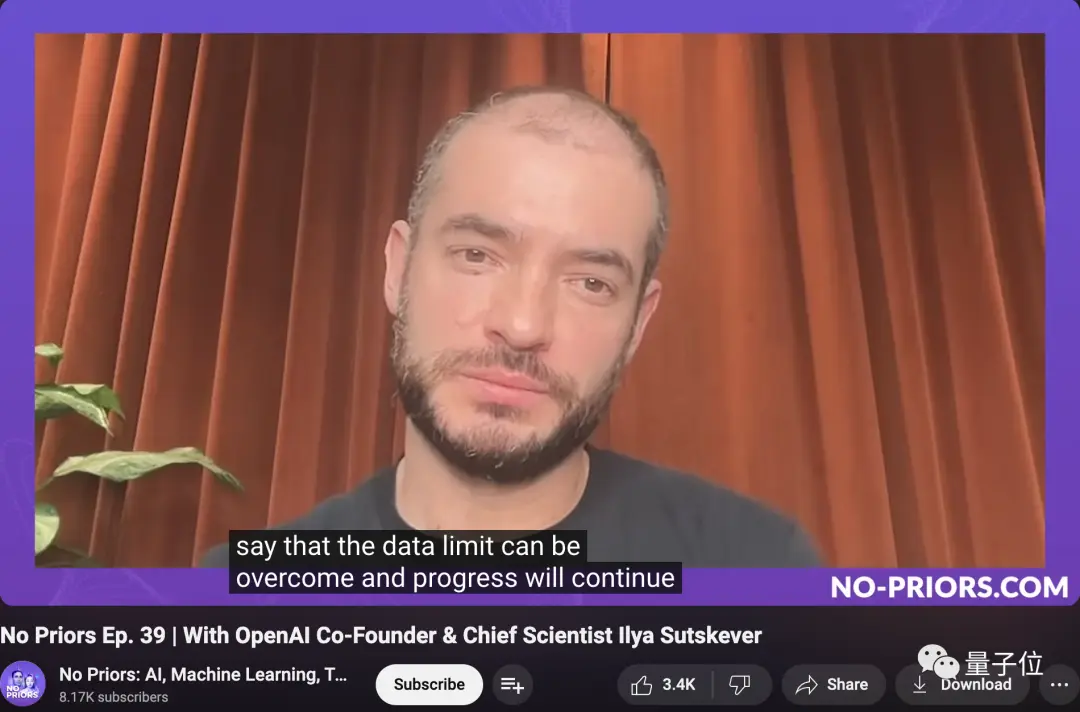
Pero hace apenas unas semanas, Ilya mencionó en una entrevista:
Sin entrar en demasiados detalles, solo quiero decir que las limitaciones de datos se pueden superar y el progreso continuará.
 Basado en GPT-Zero, Q* fue desarrollado por Jakub Pachocki y Szymon Sidor.
Basado en GPT-Zero, Q* fue desarrollado por Jakub Pachocki y Szymon Sidor.
Ambos fueron los primeros miembros de OpenAI, y también fueron los primeros miembros en anunciar que seguirían a Ultraman a Microsoft.
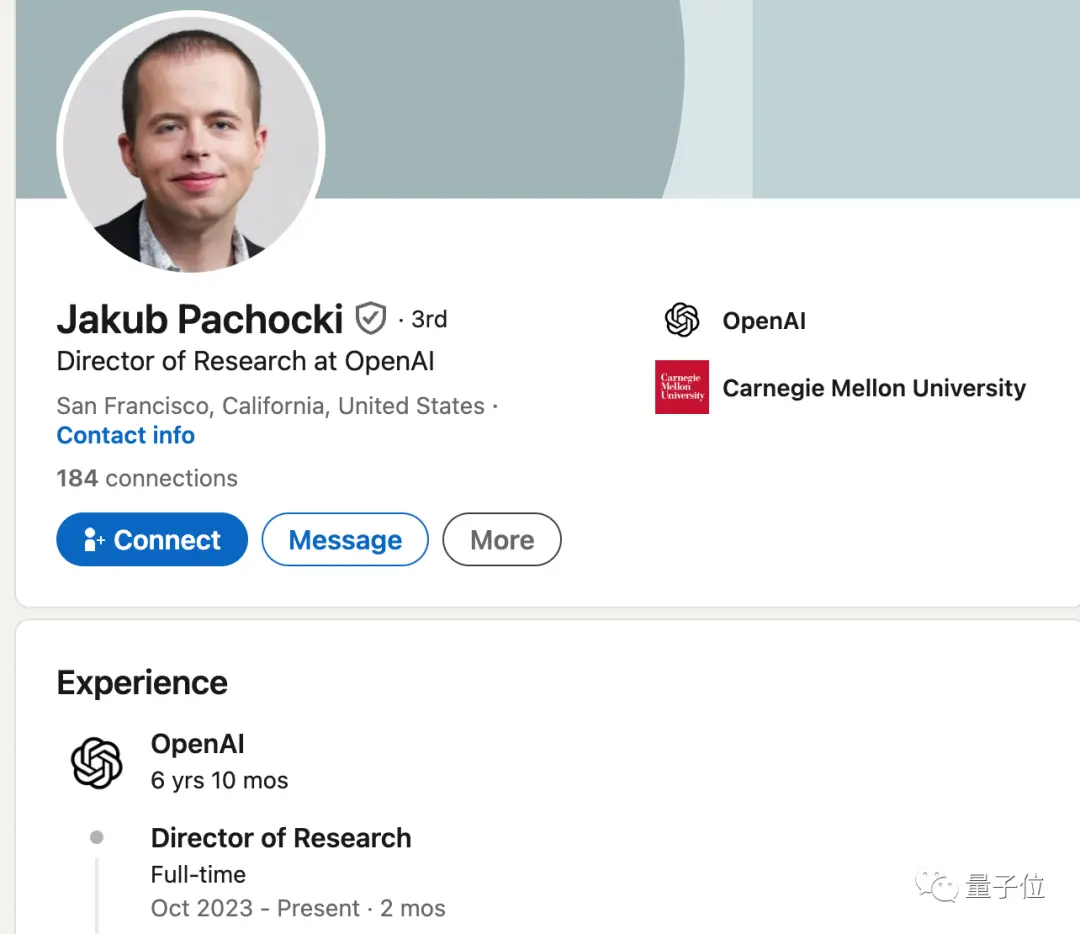
 Jakub Pachocki, quien fue ascendido a Director de Investigación el mes pasado, ha sido un colaborador clave en muchos de sus avances pasados, incluido el proyecto Dota 2 y el entrenamiento previo a GPT-4.
Jakub Pachocki, quien fue ascendido a Director de Investigación el mes pasado, ha sido un colaborador clave en muchos de sus avances pasados, incluido el proyecto Dota 2 y el entrenamiento previo a GPT-4.
 Szymon Sidor también ha trabajado en el proyecto de Dota 2, y su biografía es “construyendo AGI, línea por línea”.
Szymon Sidor también ha trabajado en el proyecto de Dota 2, y su biografía es “construyendo AGI, línea por línea”.
 En el mensaje de Reuters, se mencionó que a Q* se le dieron enormes recursos de cómputo para poder resolver ciertos problemas matemáticos. Aunque la habilidad matemática actual es solo a nivel de escuela primaria, los investigadores son muy optimistas sobre el éxito futuro.
En el mensaje de Reuters, se mencionó que a Q* se le dieron enormes recursos de cómputo para poder resolver ciertos problemas matemáticos. Aunque la habilidad matemática actual es solo a nivel de escuela primaria, los investigadores son muy optimistas sobre el éxito futuro.
Además, se mencionó que OpenAI ha establecido un nuevo equipo de “científicos de IA”, que es una fusión de los dos equipos de “Code Gen” y “Math Gen” en los primeros días, y está explorando y optimizando para mejorar la capacidad de razonamiento de la IA y, finalmente, llevar a cabo la exploración científica.
Tres conjeturas
No hay información más específica sobre qué es exactamente Q*, pero algunos han especulado por el nombre que puede tener algo que ver con Q-Learning.
Q-Learning, que data de 1989, es un algoritmo de aprendizaje por refuerzo sin modelo que no requiere modelado del entorno, ni siquiera para funciones de transferencia con factores aleatorios o funciones de recompensa, y puede adaptarse sin cambios especiales.
A diferencia de otros algoritmos de aprendizaje por refuerzo, Q-Learning se centra en aprender el valor de cada par estado-acción para decidir qué acción aportará el mayor rendimiento a largo plazo, en lugar de aprender directamente la estrategia de acción en sí.
La segunda conjetura tiene que ver con el lanzamiento de OpenAI en mayo de que resuelve problemas matemáticos a través de la “supervisión de procesos” en lugar de la “supervisión de resultados”.
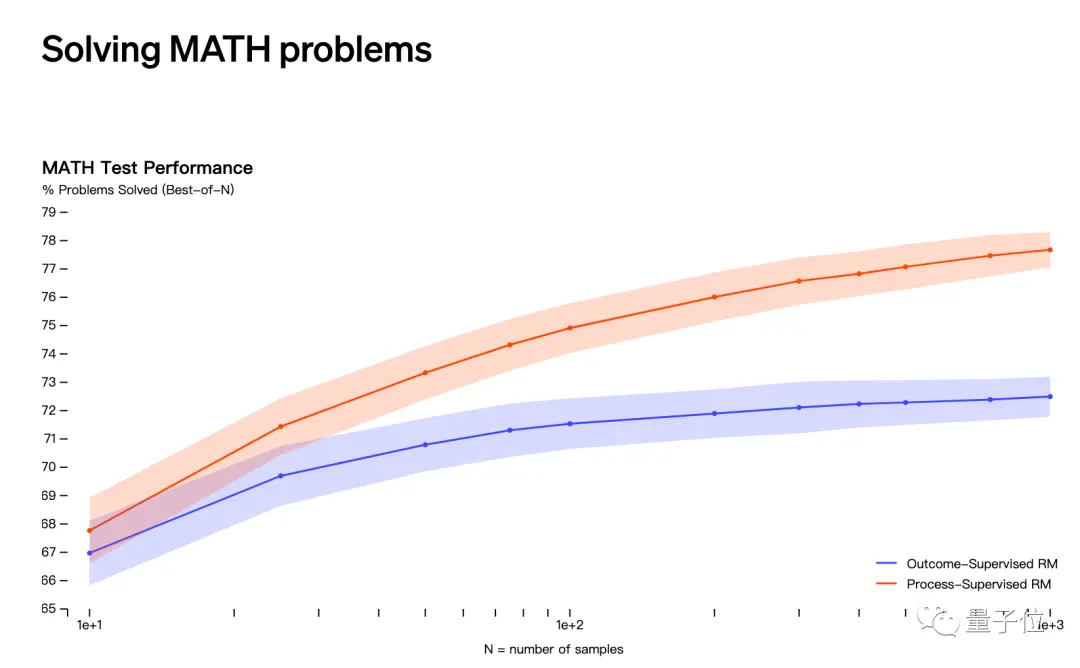 Sin embargo, los nombres de Jakub Pachocki y Szymon Sidor no aparecen en la lista de colaboradores de este estudio.
Sin embargo, los nombres de Jakub Pachocki y Szymon Sidor no aparecen en la lista de colaboradores de este estudio.
 También se especula que Noam Brown, el “padre de Depo AI” que se unió a OpenAI en julio, también podría estar involucrado en el proyecto.
También se especula que Noam Brown, el “padre de Depo AI” que se unió a OpenAI en julio, también podría estar involucrado en el proyecto.
 Cuando se unió, dijo que quería generalizar los métodos que solían ser solo aplicables a los juegos, y que el razonamiento podría ser 1000 veces más lento y más caro, pero podría descubrir nuevas drogas o probar conjeturas matemáticas.
Cuando se unió, dijo que quería generalizar los métodos que solían ser solo aplicables a los juegos, y que el razonamiento podría ser 1000 veces más lento y más caro, pero podría descubrir nuevas drogas o probar conjeturas matemáticas.
Está en línea con las descripciones rumoreadas de “requerir enormes recursos informáticos” y “ser capaz de resolver ciertos problemas matemáticos”.
 Si bien todavía se está especulando más, si los datos sintéticos y el aprendizaje por refuerzo pueden llevar la IA al siguiente nivel se ha convertido en uno de los temas más discutidos en la industria.
Si bien todavía se está especulando más, si los datos sintéticos y el aprendizaje por refuerzo pueden llevar la IA al siguiente nivel se ha convertido en uno de los temas más discutidos en la industria.
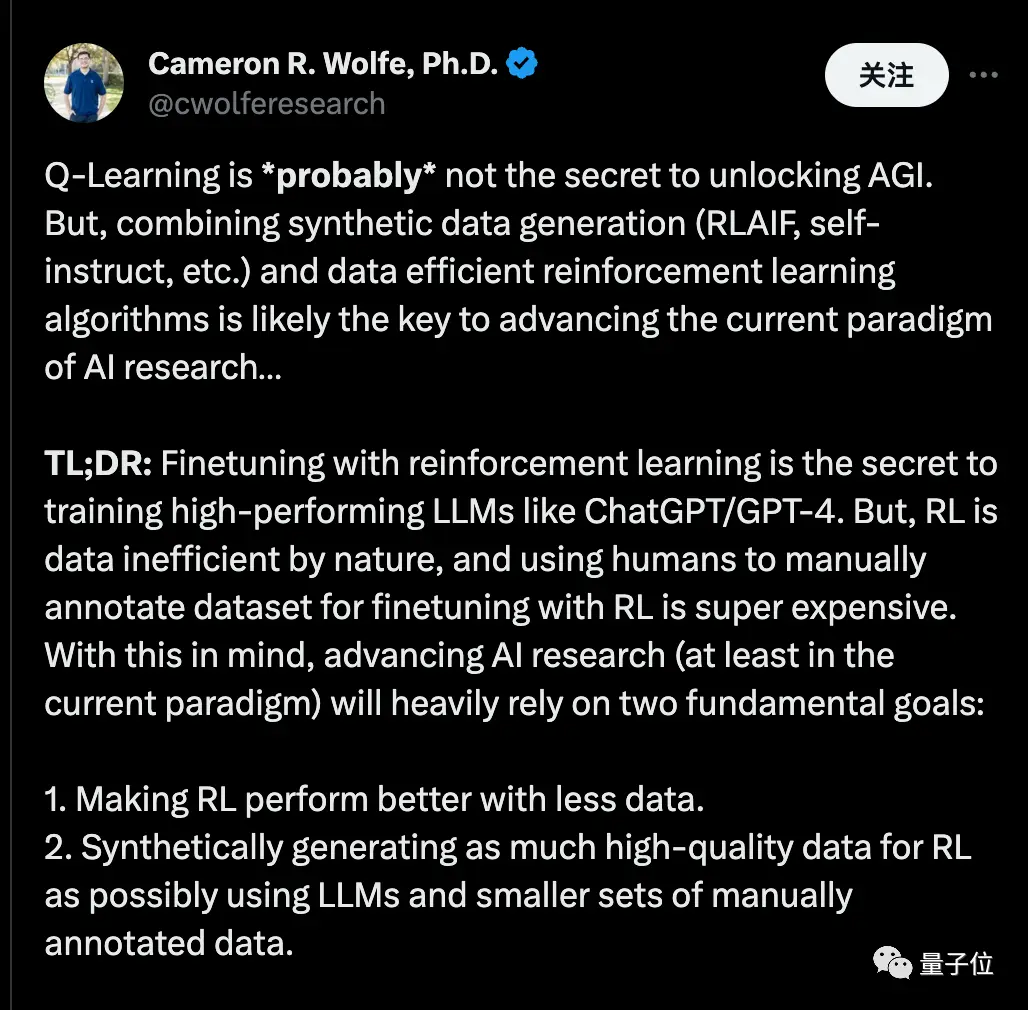
El científico de Nvidia, Fan Linxi, cree que los datos sintéticos proporcionarán billones de tokens de entrenamiento de alta calidad, y la pregunta clave es cómo mantener la calidad y evitar caer en cuellos de botella prematuramente.
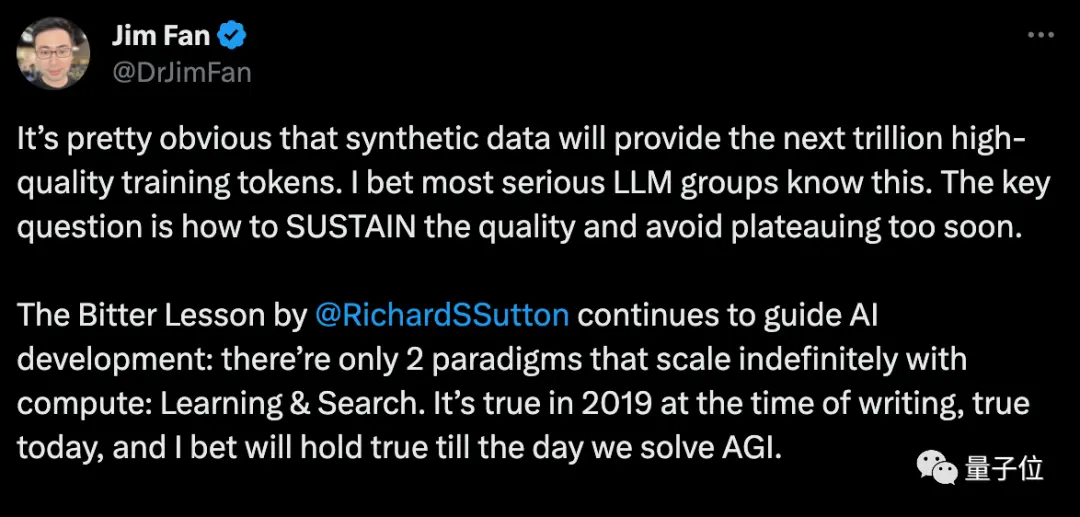 Musk está de acuerdo, mencionando que todos los libros escritos por un humano pueden caber en un disco duro, y los datos sintéticos serán mucho más allá de eso.
Musk está de acuerdo, mencionando que todos los libros escritos por un humano pueden caber en un disco duro, y los datos sintéticos serán mucho más allá de eso.
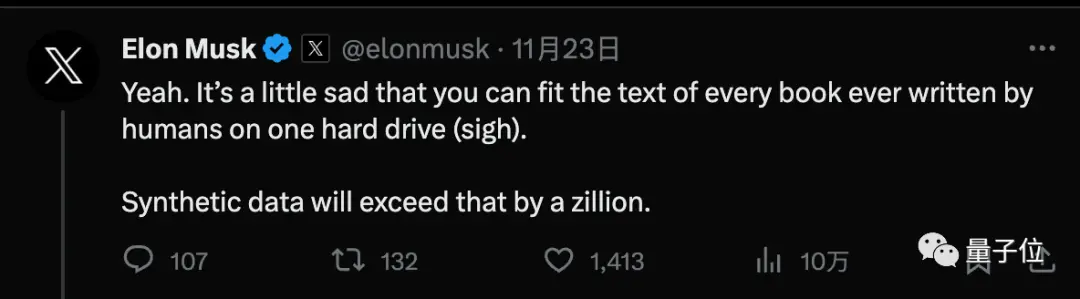 Pero LeCun, uno de los miembros del triunvirato del Premio Turing, argumenta que más datos sintéticos es una medida provisional, y que la IA tendrá que aprender en última instancia con muy pocos datos, al igual que los humanos o los animales.
Pero LeCun, uno de los miembros del triunvirato del Premio Turing, argumenta que más datos sintéticos es una medida provisional, y que la IA tendrá que aprender en última instancia con muy pocos datos, al igual que los humanos o los animales.
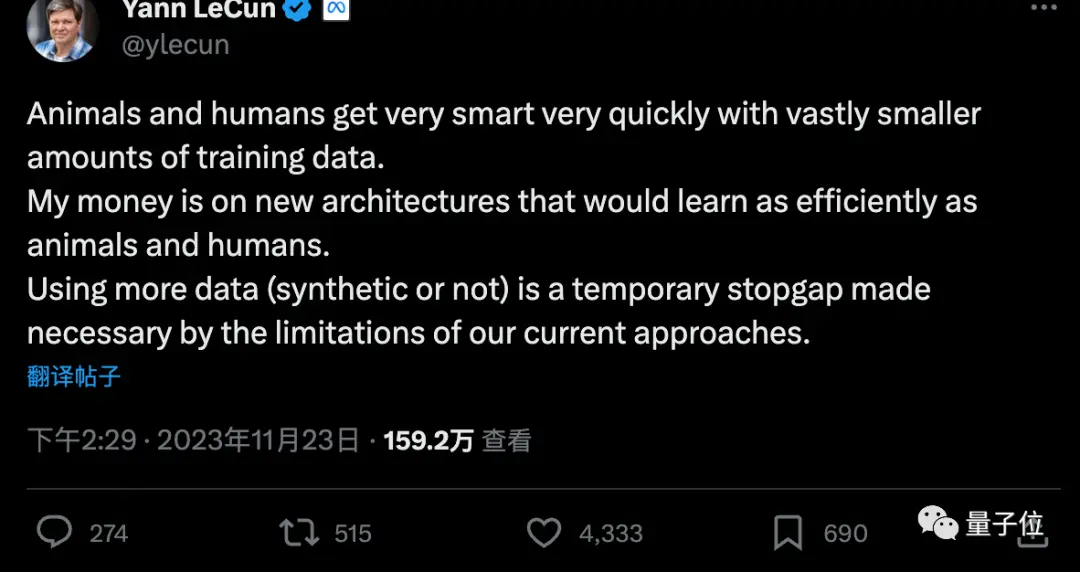 Cameron R. Wolfe, Ph.D. de la Universidad de Rice, dijo que Q-Learning puede no ser el secreto para desbloquear AGI.
Cameron R. Wolfe, Ph.D. de la Universidad de Rice, dijo que Q-Learning puede no ser el secreto para desbloquear AGI.
Pero la combinación de “datos sintéticos” con “algoritmos de aprendizaje por refuerzo eficientes en cuanto a datos” puede ser la clave para avanzar en el paradigma actual de investigación de la IA.
Dijo que el ajuste fino a través del aprendizaje por refuerzo es el secreto para entrenar modelos grandes de alto rendimiento, como ChatGPT/GPT-4. Sin embargo, el aprendizaje por refuerzo es inherentemente ineficiente en cuanto a datos, y es muy costoso ajustar el aprendizaje por refuerzo utilizando conjuntos de datos etiquetados manualmente por humanos. Con esto en mente, el avance de la investigación en IA (al menos en el paradigma actual) dependerá en gran medida de dos objetivos fundamentales:
- Hacer que el aprendizaje por refuerzo funcione mejor con menos datos.
- Sintetice y genere datos de alta calidad utilizando modelos grandes y una pequeña cantidad de datos anotados manualmente siempre que sea posible.
… Si nos atenemos a la predicción del siguiente paradigma de token (es decir, preentrenado -> SFT -> RLHF) utilizando Decoder-only Transformer… La combinación de estos dos métodos dará a todos acceso a técnicas de capacitación de vanguardia, ¡no solo a equipos de investigación con mucho dinero!
Una cosa más
Nadie dentro de OpenAI ha respondido aún al mensaje de Q.
Pero Altman acaba de revelar que tuvo unas horas de conversación amistosa con el fundador de Quora, Adam D’Angelo, quien permaneció en la junta.
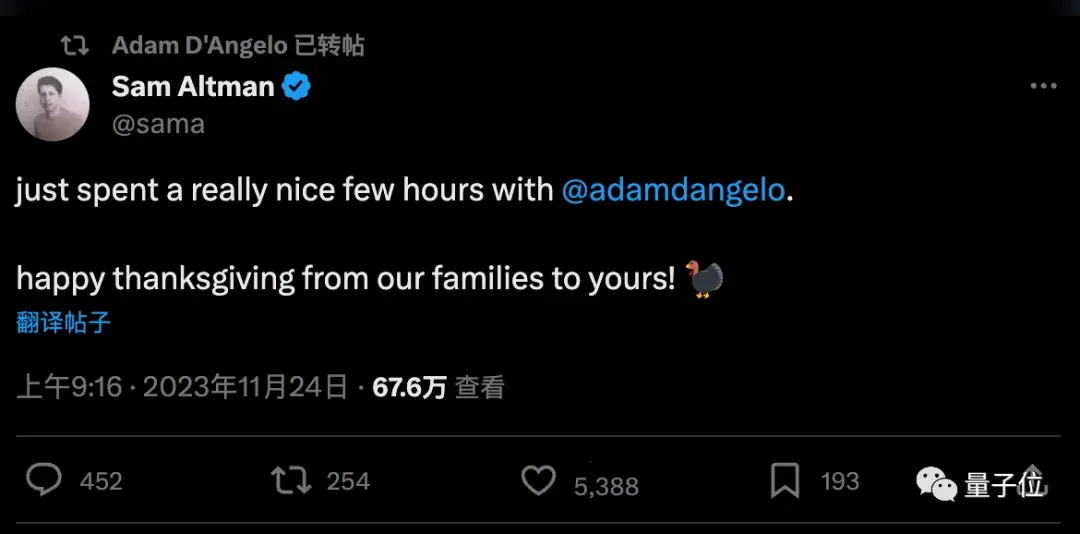 Parece que si Adam D’Angelo estuvo o no detrás del incidente, como todo el mundo había especulado, ahora se ha llegado a un acuerdo.
Parece que si Adam D’Angelo estuvo o no detrás del incidente, como todo el mundo había especulado, ahora se ha llegado a un acuerdo.
Enlaces de referencia:
[1]
[2]
[3]
[4]
[5]
[6]
