随着 DeFi、链上分析平台、区块链浏览器和 AI Agent 对链上数据需求不断增长,数据索引网络已经成为 Web3 基础设施的重要组成部分。理解 SQD 与 The Graph 的差异,有助于更清晰地认识当前 Web3 数据层的发展方向以及不同技术路线的特点。
什么是 SQD
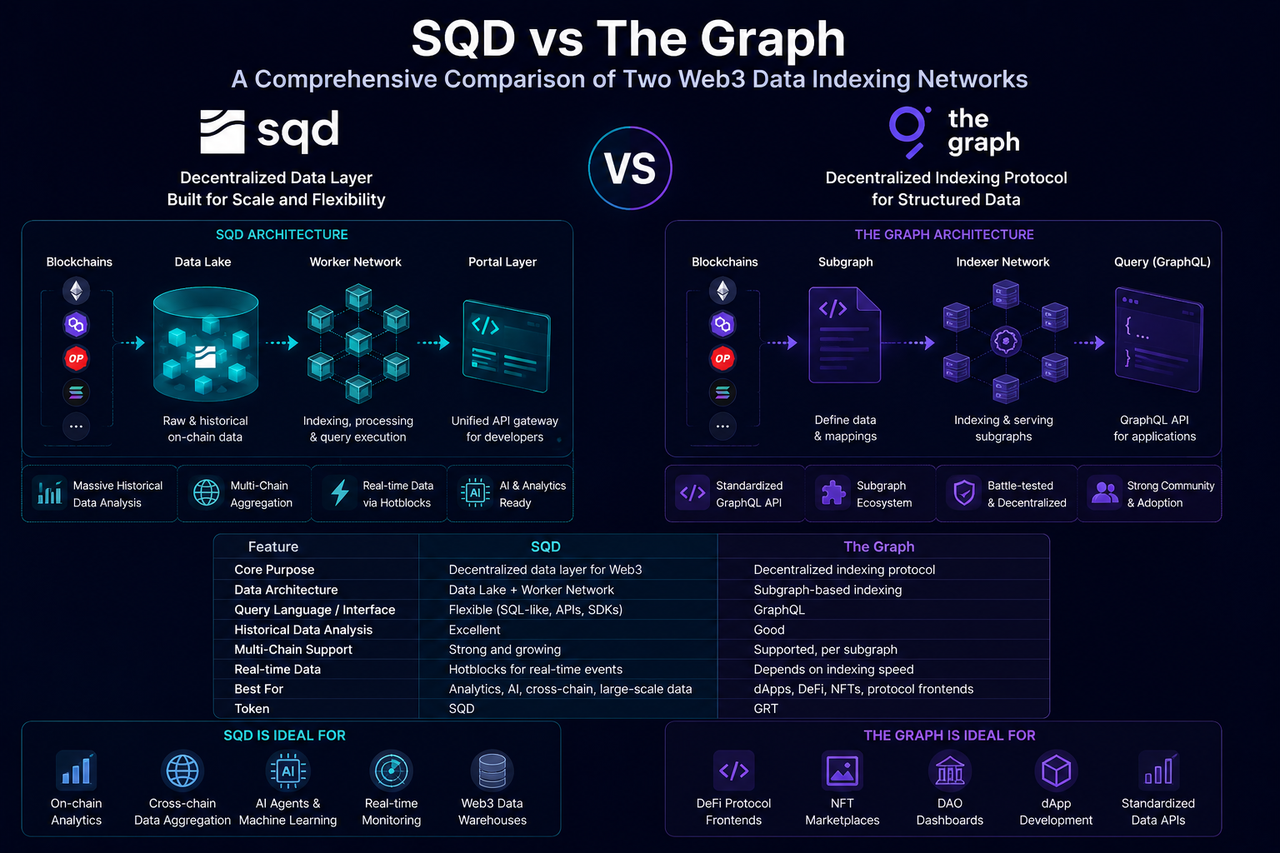
SQD(Subsquid)作为一种去中心化区块链数据网络,通过数据湖(Data Lake)、Worker 节点和 Portal 查询层构建开放的数据访问体系。SQD 的核心目标是让开发者能够快速访问和分析多链数据,而无需自行维护复杂的数据索引系统。
与传统索引方案不同,SQD 会提前采集和存储大量链上历史数据,并通过 Worker 节点建立索引和执行查询。当应用发起请求时,Portal 层负责调度网络资源并返回结构化结果。这种架构使 SQD 更接近一个面向 Web3 的去中心化数据平台。
什么是 The Graph
The Graph 作为 Web3 领域最早实现大规模应用的数据索引协议之一。其核心机制是通过 Subgraph 对特定协议或应用的数据进行定义和索引,然后向开发者提供 GraphQL 查询接口。
开发者需要提前定义需要索引的数据结构和事件类型。Indexer 节点根据 Subgraph 配置同步和处理链上数据,最终生成可供查询的数据集。
The Graph 的设计理念是让每个应用拥有专属的数据索引方案,因此在 DeFi、NFT 和 DAO 生态中获得广泛采用。
数据架构有什么区别
数据架构是两者最核心的差异之一。
The Graph 采用 Subgraph 驱动模式。开发者需要先定义数据模型,再由网络构建对应索引。这种方式类似于提前设计数据库结构,然后根据需求存储数据。
SQD 则采用数据湖架构。大量链上数据会被统一采集并存储在分布式数据湖中,Worker 节点根据查询需求动态处理数据。
从本质上看,The Graph 更像针对特定应用建立索引,而 SQD 更像建立一个覆盖整个区块链生态的数据仓库。
数据查询方式有什么区别
查询模式直接影响开发体验和应用能力。
The Graph 的查询主要依赖 GraphQL 接口。开发者能够通过标准化语法快速获取预定义的数据结果。这种模式适合结构明确且查询逻辑相对固定的应用。
SQD 更强调灵活查询能力。开发者不仅能够访问预处理数据,还能够执行更复杂的历史数据分析和多链聚合查询。
对于需要大规模数据分析的场景,SQD 通常具备更高灵活性。而对于标准化应用接口构建,The Graph 则拥有成熟生态优势。
多链支持能力有什么区别
随着 Web3 进入多链时代,跨链数据访问能力越来越重要。
The Graph 最初主要围绕 Ethereum 生态发展,随后逐步扩展至多个 Layer 1 和 Layer 2 网络。不同链通常需要对应的 Subgraph 配置。
SQD 从架构设计阶段就强调多链数据整合能力。由于底层采用统一数据湖结构,不同区块链的数据能够在同一框架下进行处理和查询。
对于需要跨链分析、跨链资产追踪和统一数据访问的应用而言,SQD 的架构更容易实现多链聚合。
实时数据处理能力有什么区别
链上监控系统和 AI Agent 对实时数据具有较高要求。
The Graph 主要围绕事件索引和查询构建,其实时性通常取决于索引同步速度和网络状态。
SQD 在数据湖之外还构建了 Hotblocks 实时数据层,用于处理新区块和实时事件。这使其能够同时覆盖历史分析和实时监控需求。
对于交易监控、自动化策略执行和实时数据流处理场景,SQD 的实时架构设计具有一定优势。
开发者体验有什么区别
两种方案都希望降低链上数据获取难度,但实现路径有所不同。
The Graph 的优势在于成熟的 GraphQL 查询体系。对于已有 Web 开发经验的团队而言,GraphQL 的学习成本相对较低。
SQD 则更加关注数据分析能力和灵活性。开发者能够直接利用已有数据湖资源,而无需为每个应用单独构建完整索引体系。
如果需求以标准化数据接口为主,The Graph 往往更容易上手;如果涉及复杂分析和多链数据处理,SQD 提供更丰富的数据访问能力。
节点网络与激励机制有什么区别
两者都采用代币激励模式维持网络运行。
The Graph 网络主要由 Indexer、Curator 和 Delegator 等角色组成。Indexer 负责索引和查询服务,其他参与者通过经济激励维护网络生态。
SQD 网络则围绕 Worker 节点、Portal 服务提供者和 Delegator 构建。Worker 节点负责数据处理和查询执行,是整个网络的核心执行层。
虽然两种模式都属于去中心化数据网络,但节点职责划分和资源协调机制存在差异。
哪些场景更适合 SQD
SQD 更适合以下场景:
-
多链数据分析平台
-
链上行为分析系统
-
AI Agent 数据层
-
区块链数据仓库
-
实时监控系统
-
大规模历史数据分析
这些场景通常需要访问大量历史数据,并执行复杂计算和聚合任务。
哪些场景更适合 The Graph
The Graph 更适合以下场景:
-
DeFi 协议前端
-
NFT 平台数据接口
-
DAO 数据展示
-
标准化 Web3 API
-
特定协议数据服务
这些应用通常拥有固定的数据结构和明确查询需求。
SQD 与 The Graph 核心对比
| 对比维度 | SQD | The Graph |
|---|---|---|
| 核心定位 | 去中心化数据层 | 去中心化索引协议 |
| 数据架构 | Data Lake | Subgraph |
| 查询模式 | 灵活查询 | GraphQL 查询 |
| 历史数据分析 | 强 | 中等 |
| 多链聚合 | 强 | 中等 |
| 实时数据能力 | Hotblocks 支持 | 依赖索引同步 |
| 节点角色 | Worker Network | Indexer Network |
| AI Agent 适配 | 较强 | 一般 |
| 应用接口构建 | 强 | 强 |
| 学习门槛 | 中等 | 较低 |
总结
SQD 与 The Graph 都是 Web3 数据基础设施的重要代表,但两者采用了不同的技术路线。The Graph 通过 Subgraph 为特定应用提供标准化索引服务,在 DeFi 和 NFT 生态中拥有成熟应用基础。SQD 则通过数据湖、Worker 网络和实时数据层构建通用型去中心化数据平台,更强调历史数据分析、多链聚合和复杂查询能力。
从行业发展趋势来看,两种模式并非完全竞争关系。随着 Web3 数据规模持续增长,标准化查询服务和通用数据层都将成为区块链基础设施的重要组成部分。
FAQs
SQD 和 The Graph 的最大区别是什么?
最大的区别在于数据架构。The Graph 基于 Subgraph 建立应用级索引,而 SQD 基于分布式数据湖和 Worker 网络构建通用数据层,因此数据组织和查询方式存在明显差异。
SQD 能否替代 The Graph?
两者解决的问题部分重叠,但设计目标不同。The Graph 更适合构建标准化数据接口,SQD 更适合复杂分析和多链数据访问,因此并不存在完全替代关系。
为什么 AI Agent 更关注 SQD?
AI Agent 通常需要访问大量历史数据和多链信息。SQD 的数据湖架构和灵活查询能力能够为 AI 系统提供更丰富的数据来源。
The Graph 是否支持多链数据?
支持。The Graph 已扩展至多个区块链网络,但通常需要为不同网络配置对应的 Subgraph。
SQD 为什么采用 Data Lake 架构?
Data Lake 能够统一存储大规模链上历史数据,并支持后续灵活分析。这种架构更适合复杂查询和跨链数据聚合场景。
开发者应该选择 SQD 还是 The Graph?
选择取决于具体需求。如果重点是标准化协议数据接口,The Graph 是成熟方案;如果需要复杂分析、多链数据整合或 AI 数据层支持,SQD 更具优势。


相关文章

不可不知的比特币减半及其重要性

如何选择比特币钱包?


CKB:闪电网络促新局,落地场景需发力

Master Protocol:激活 BTC 生息潜力
