DeepSeek випустила демонстраційні (preview) версії DeepSeek-V4-Pro та DeepSeek-V4-Flash 24 квітня 2026 року; обидві є моделями з відкритими вагами (open-weight) з вікнами контексту на один мільйон токенів і цінами значно нижчими за зіставні західні альтернативи. Модель V4-Pro коштує $1.74 за мільйон вхідних токенів і $3.48 за мільйон вихідних токенів — приблизно 1/20 ціни Claude Opus 4.7 і на 98% менше, ніж GPT-5.5 Pro, згідно з офіційними специфікаціями компанії.
Архітектура моделі та масштаб
DeepSeek-V4-Pro має 1.6 трильйона загальних параметрів, що робить її найбільшою відкритою (open-source) моделлю на ринку LLM станом на сьогодні. Однак для кожного проходу інференсу активуються лише 49 мільярдів параметрів, використовуючи те, що DeepSeek називає підходом Mixture-of-Experts, удосконаленим з V3. Такий дизайн дозволяє всій моделі залишатися у сплячому стані, а активується лише релевантні фрагменти для будь-якого запиту, знижуючи витрати на обчислення при збереженні обсягу знань.
DeepSeek-V4-Flash працює в меншому масштабі: 284 мільярди загальних параметрів і 13 мільярдів активних параметрів. Згідно з бенчмарками DeepSeek, вона «досягає порівнюваної з версією Pro продуктивності в задачах міркування, коли їй дають більший бюджет на “thinking”.»
Обидві моделі підтримують контекст на один мільйон токенів як стандартну функцію — приблизно 750,000 слів, або приблизно вся трилогія «Володар перснів» плюс додатковий текст.
Технічні інновації: механізми уваги в масштабі
DeepSeek вирішив проблему обчислювального масштабування, властиву обробці довгого контексту, винайшовши два нові типи attention, як детально описано в технічній статті компанії, доступній на GitHub.
Стандартні механізми AI attention стикаються із жорсткою проблемою масштабування: щоразу, коли довжина контексту подвоюється, вартість обчислень приблизно чотириразово зростає. Рішення DeepSeek включає два взаємодоповнювальні підходи:
Compressed Sparse Attention працює у два кроки. Спочатку вона стискає групи токенів — наприклад, кожні 4 токени — в один запис. Потім, замість того щоб виконувати attention до всіх стиснених записів, вона використовує «Lightning Indexer», щоб вибрати лише найбільш релевантні результати для будь-якого запиту. Це скорочує область attention моделі з мільйона токенів до значно меншого набору важливих фрагментів.
Heavily Compressed Attention застосовує більш радикальний підхід: згортає кожні 128 токенів в один запис без sparse-обрання. Хоча це втрачає деталізацію, воно дає вкрай дешевий глобальний огляд. Два типи attention працюють у чергувальних шарах, дозволяючи моделі підтримувати і деталізацію, і огляд.
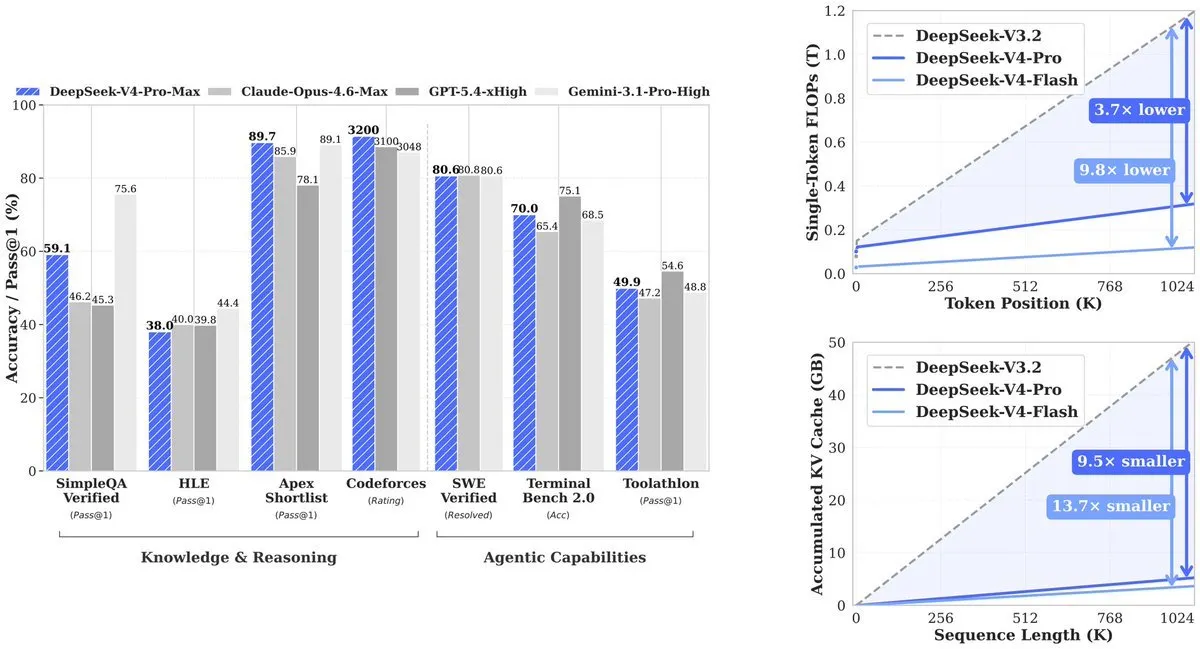
Результат: V4-Pro використовує 27% від обчислень, які попередник (V3.2) вимагав. KV cache — пам’ять, потрібна для відстеження контексту — падає до 10% від V3.2. V4-Flash просуває ефективність ще далі: 10% обчислень і 7% пам’яті порівняно з V3.2.
Продуктивність у бенчмарках і конкурентні позиції
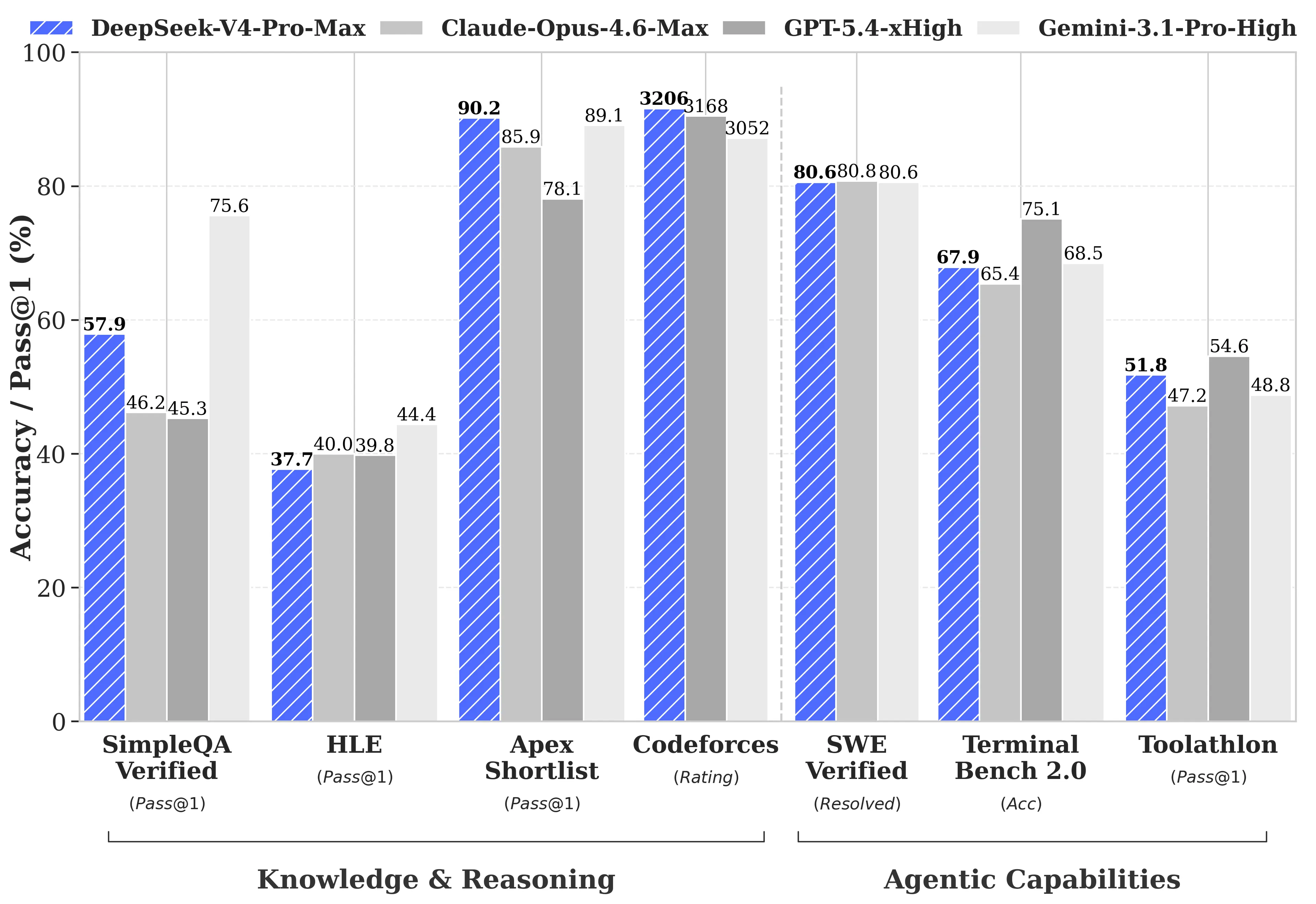
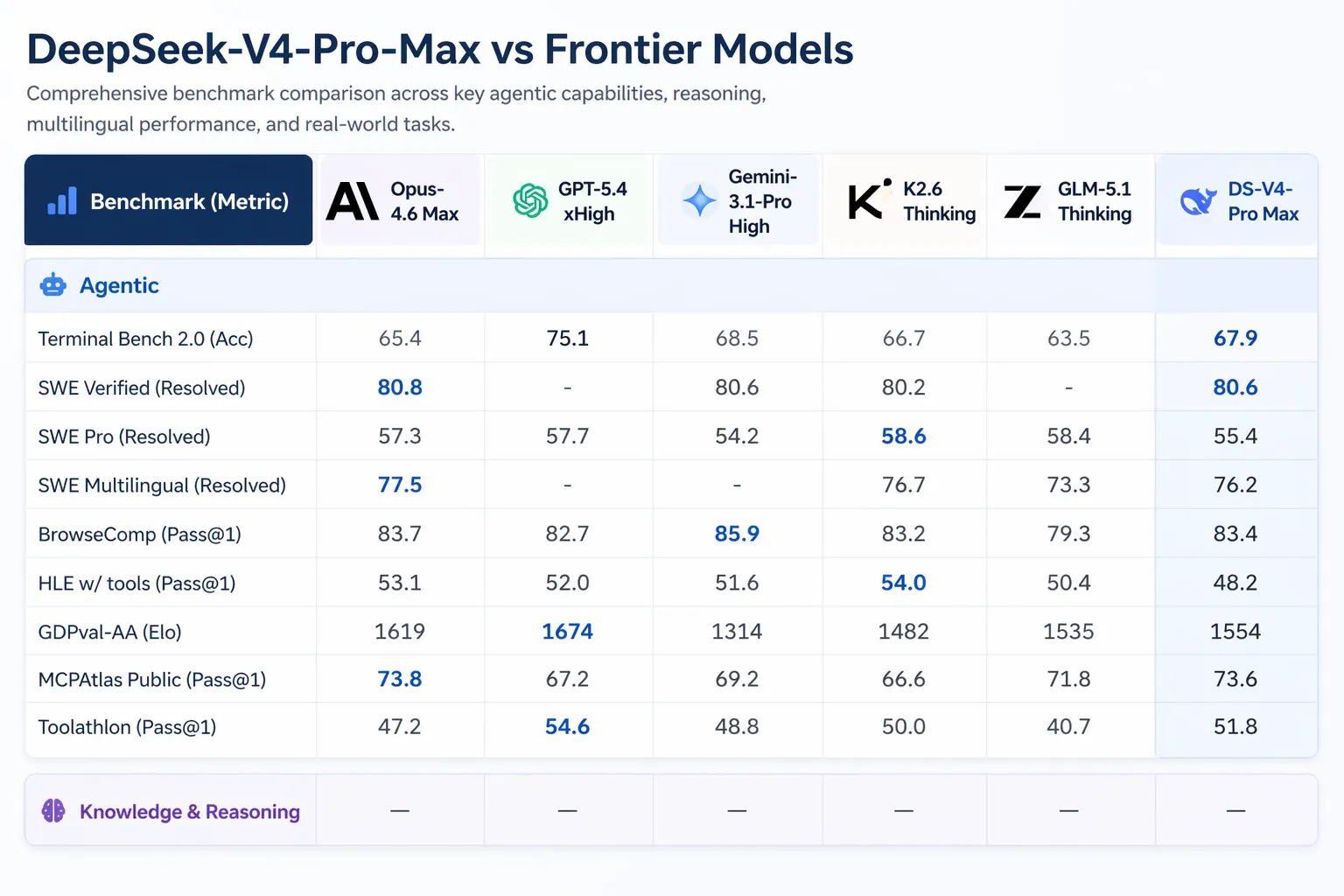
DeepSeek опублікувала вичерпні порівняння бенчмарків проти GPT-5.4 і Gemini-3.1-Pro, включно з напрямами, де V4-Pro поступається конкурентам. У задачах міркування міркування V4-Pro відстають від GPT-5.4 і Gemini-3.1-Pro приблизно на три–шість місяців, згідно з технічним звітом DeepSeek.
Де V4-Pro попереду:
- Codeforces (competitive programming): V4-Pro набрала 3,206, посівши приблизно 23-тє місце серед фактичних учасників людських змагань
- Apex Shortlist (curated math and STEM problems): 90.2% прохідності проти Opus 4.6 з 85.9% та GPT-5.4 з 78.1%
- SWE-Verified (GitHub issue resolution): 80.6%, що відповідає Claude Opus 4.6
Де V4-Pro поступається:
- MMLU-Pro (multitasking): Gemini-3.1-Pro має 91.0% проти V4-Pro на рівні 87.5%
- GPQA Diamond (expert knowledge): Gemini має 94.3 проти V4-Pro 90.1
- Humanity’s Last Exam (graduate-level): Gemini-3.1-Pro має 44.4% проти V4-Pro 37.7%
У задачах з довгим контекстом V4-Pro випереджає відкриті (open-source) моделі та обганяє Gemini-3.1-Pro на CorpusQA (simulating real document analysis at one million tokens), але поступається Claude Opus 4.6 на MRCR, що вимірює отримання (retrieval) конкретної інформації, похованої глибоко в довгому тексті.
Агентні та кодингові можливості
V4-Pro може працювати в Claude Code, OpenCode та інших AI-інструментах для програмування. Згідно з внутрішнім опитуванням DeepSeek серед 85 розробників, які використовували V4-Pro як свого основного агенту для кодування, 52% сказали, що він готовий бути їхньою моделлю за замовчуванням, 39% схилялися до «так», і менше ніж 9% сказали «ні». Внутрішнє тестування DeepSeek показало, що V4-Pro перевершує Claude Sonnet і наближається до Claude Opus 4.5 у агентних задачах кодування.
Artificial Analysis поставила V4-Pro першим серед усіх моделей з відкритими вагами на GDPval-AA — бенчмарку, що тестує економічно цінну роботу зі знаннями в межах фінансів, права та дослідницьких задач. V4-Pro-Max набрала 1,554 Elo, випереджаючи GLM-5.1 (1,535) та MiniMax’s M2.7 (1,514). Claude Opus 4.6 набирає 1,619 на цьому ж бенчмарку.
V4 вводить «interleaved thinking», який зберігає повний ланцюжок міркувань (chain of thought) у викликах до інструментів (tool calls). У попередніх моделях, коли агент робив кілька викликів інструментів — наприклад, пошук у вебі, запуск коду, а потім знову пошук — контекст міркувань моделі очищався між раундами. V4 зберігає безперервність міркувань між кроками, запобігаючи втраті контексту в складних автоматизованих робочих процесах.
Конкурентне середовище та контекст ціноутворення
Реліз V4 виходить на тлі значної активності в AI-сфері. Anthropic випустила Claude Opus 4.7 16 квітня 2026 року. GPT-5.5 від OpenAI запущено 23 квітня 2026 року; GPT-5.5 Pro коштує $30 за мільйон вхідних токенів і $180 за мільйон вихідних токенів. GPT-5.5 обганяє V4-Pro на Terminal Bench 2.0 (82.7% проти 70.0%) — бенчмарку, що тестує складні робочі процеси агентів командного рядка.
Xiaomi випустила MiMo V2.5 Pro 22 квітня 2026 року, запропонувавши повні багатомодальні можливості (image, audio, video) за $1 вхід і $3 вихід на мільйон токенів. Tencent випустила Hy3 того ж дня, що й GPT-5.5.
Для перспективи цін: CEO Cline Saoud Rizwan зазначив, що якби Uber використав DeepSeek замість Claude, його бюджет на AI у 2026 році — як повідомляється, достатній для чотирьох місяців використання — вистачив би на сім років.
Розгортання та доступність
І V4-Pro, і V4-Flash мають ліцензію MIT та доступні на Hugging Face. На даний момент моделі є лише текстовими; DeepSeek заявив, що працює над багатомодальними можливостями. Обидві моделі можна запускати безкоштовно на локальному обладнанні або налаштовувати залежно від потреб компанії.
Поточні endpoint-адреси deepseek-chat та deepseek-reasoner від DeepSeek вже маршрутизують запити до V4-Flash у режимах non-thinking і thinking відповідно. Старі endpoint-адреси deepseek-chat та deepseek-reasoner вийдуть з експлуатації 24 липня 2026 року.
DeepSeek частково навчала V4 на чипах Huawei Ascend, обходячи обмеження експорту зі США. Компанія заявила, що коли 950 нових супернод (supernodes) запрацюють пізніше у 2026 році, вже низька ціна моделі Pro знизиться ще більше.
Практичні наслідки
Для підприємств структура ціноутворення може змінити розрахунки співвідношення витрат і вигод. Модель, що лідирує в бенчмарках open-source за $1.74 за мільйон вхідних токенів, робить обробку великих обсягів документів, юридичну перевірку та конвеєри генерації коду суттєво дешевшими, ніж за шість місяців до цього. Контекст на один мільйон токенів дозволяє обробляти цілі кодові бази або регуляторні подання одним запитом, а не фрагментувати їх на кілька викликів.
Для розробників і незалежних творців (solo builders) V4-Flash є основним міркуванням. За $0.14 за вхід і $0.28 за вихід на мільйон токенів вона дешевша, ніж моделі, які рік тому вважалися бюджетними варіантами, при цьому справляється з більшістю задач, які виконує версія Pro.
Застереження: Інформація на цій сторінці може походити від третіх осіб і не відображає погляди або думки Gate. Вміст, що відображається на цій сторінці, є лише довідковим і не є фінансовою, інвестиційною або юридичною порадою. Gate не гарантує точність або повноту інформації і не несе відповідальності за будь-які збитки, що виникли в результаті використання цієї інформації. Інвестиції у віртуальні активи пов'язані з високим ризиком і піддаються значній ціновій волатильності. Ви можете втратити весь вкладений капітал. Будь ласка, повністю усвідомлюйте відповідні ризики та приймайте обережні рішення, виходячи з вашого фінансового становища та толерантності до ризику. Для отримання детальної інформації, будь ласка, зверніться до
Застереження.
