По мере того как модели ИИ эволюционируют в сторону мультимодальности, вертикальных сценариев использования и интеллектуальных агентов (Agents), отраслевой консенсус смещается от «больше данных — лучше» к «высокоточные, прослеживаемые и соответствующие требованиям конфиденциальности данные — это дефицитный ресурс». Традиционные централизованные платформы разметки сталкиваются с узкими местами в стоимости, реакции на длиннохвостый спрос и распределении долевого участия. Децентрализованные сети данных для ИИ стремятся изменить производственные отношения в сфере данных через роевой интеллект, токен-координацию и открытые интерфейсы. Понимание того, как работает Alaya AI, требует изучения её технических уровней, конвейера автоматической разметки, логики семплирования и ончейн-экономических механизмов, а не простого обозначения как «аутсорсинга разметки на блокчейне».
С точки зрения промышленной архитектуры, Alaya AI представляет собой конвергенцию Web3 и ИИ на уровне данных: вклад данных может быть стимулирован, права на задачи — токенизированы как NFT, а разработка моделей — профинансирована через сообщество посредством стейкинг-пула AGT, в то время как Открытая платформа данных (ODP) соединяет предложение и спрос. Следующие разделы детально разбирают базовую архитектуру сети, механизмы повышения эффективности, интеграцию с Web3, системы стейкинга и вклада, отличия от традиционных платформ, реальные проблемы и будущие направления, предлагая структурированную основу для оценки её технической осуществимости и ценности экосистемы.
Разбор базовой технической архитектуры Alaya AI
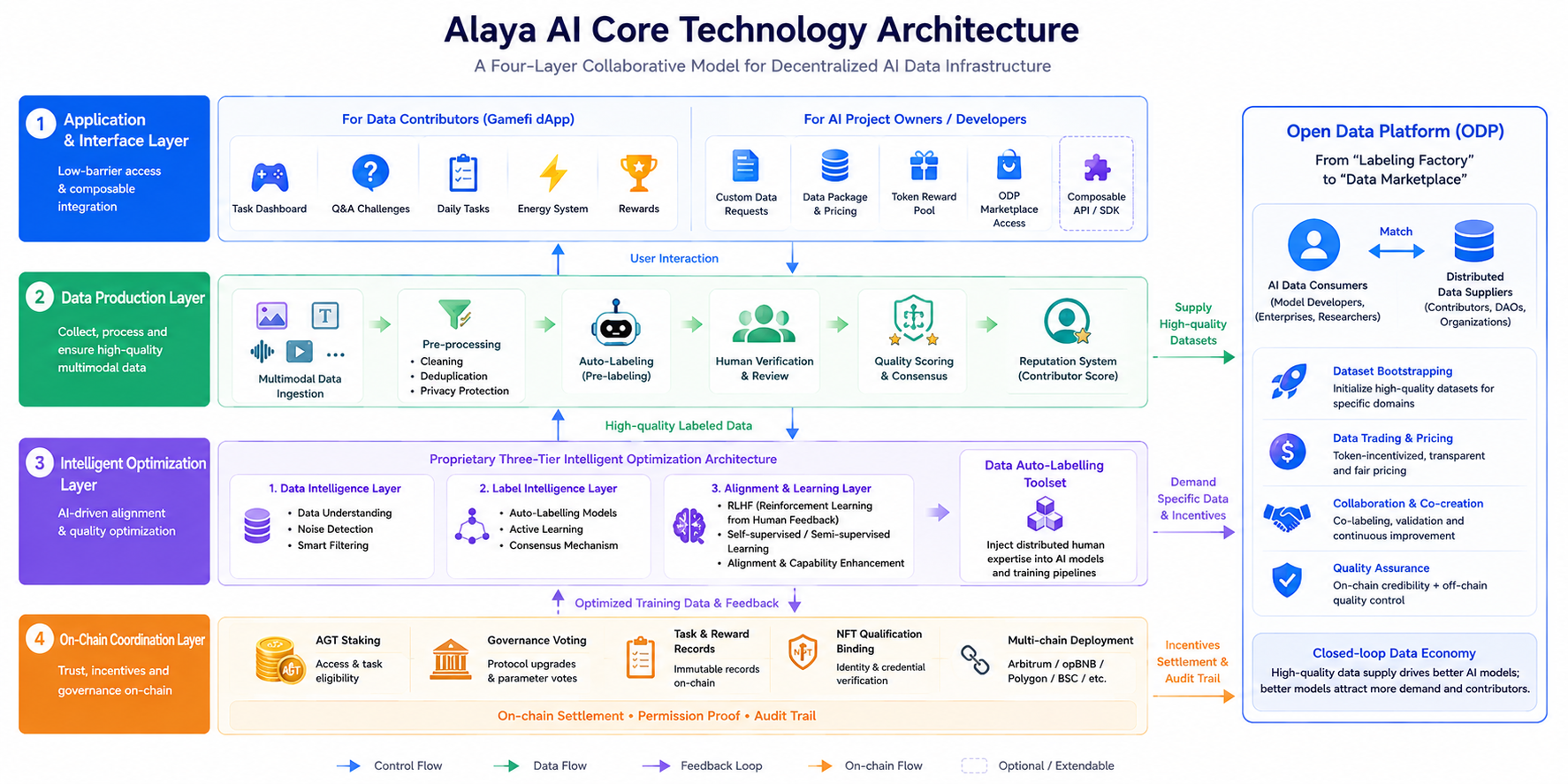
Общую архитектуру Alaya AI можно описать как четырёхуровневую коллаборативную модель, где каждый уровень имеет чётко разделённые обязанности с различными потоками данных и управления, что позволяет избежать накладных расходов на производительность, характерных для «размещения всего на цепочке».
-
Уровень приложений и интерфейсов. Включает геймифицированное dApp для участников, вносящих данные (панели задач, викторины, ежедневные задания и т.д.), а также пользовательские запросы данных, предложения пакетов данных и точку входа на маркетплейс ODP для команд AI-проектов. Этот уровень делает акцент на низком пороге входа и компоновке доступа, позволяя разработчикам публиковать вертикальные потребности в данных через пользовательские пулы токенов-вознаграждений.
-
Уровень производства данных. Отвечает за мультимодальный сбор данных (текст, изображения, видео, аудио), предварительную обработку (очистка, дедупликация, защита конфиденциальности), автоматическую разметку, ручную верификацию и оценку качества. Alaya AI опирается на принципы роевого интеллекта: одна и та же задача может быть подвергнута перекрёстной разметке несколькими участниками с использованием консенсуса или механизма большинства для повышения согласованности меток, при этом историческая точность формирует репутацию участника, влияющую на будущее распределение задач.
-
Уровень интеллектуальной оптимизации. Ключевой компонент — инструментарий автоматической разметки данных, основанный на собственной трёхуровневой архитектуре интеллектуальной оптимизации. В сочетании с тонкой настройкой RLHF (Обучение с подкреплением на основе человеческой обратной связи) он внедряет распределённый человеческий опыт в процессы самоконтролируемого и полуконтролируемого обучения, поддерживая согласование (alignment) и улучшение возможностей модели.
-
Уровень ончейн-координации. Ключевая координационная информация, такая как стейкинг AGT, голосование по управлению, записи статуса задач и вознаграждений, а также привязка квалификаций NFT, полагается на блокчейн (развёртывания экосистемы охватывают несколько цепочек, включая Arbitrum, opBNB, Polygon и BSC; подробности см. в официальных объявлениях). Цепочка не хранит большие объёмы необработанных данных, но обрабатывает расчёты по стимулам, подтверждение разрешений и привязку аудиторского следа, следуя распространённой парадигме проектирования Web3 AI: «вычисления вне цепочки, доверие на цепочке».
Открытая платформа данных (ODP), запущенная в ноябре 2024 года, расширяет сеть от «фабрики разметки» до «маркетплейса данных»: потребители данных ИИ и распределённые поставщики напрямую соединяются через настраиваемые токен-стимулы, поддерживая начальную загрузку наборов данных, торговлю и сотрудничество для создания замкнутого цикла спроса и предложения.
Как система автоматической разметки повышает эффективность данных для ИИ
Автоматическая разметка — это базовый модуль для Alaya AI, позволяющий снизить предельные издержки и сократить циклы поставки. Проект позиционирует её как следующий этап эволюции самоконтролируемого ИИ: машины сначала генерируют кандидатные метки, затем люди сосредотачиваются на неоднозначных образцах и предметных суждениях, вместо того чтобы вручную размечать каждую часть данных с нуля.
Технический процесс обычно включает следующие шаги:
-
Мультимодальный сбор: Инструментарий принимает статические и динамические визуальные данные, текст и сенсорные входы, которые все поступают в единый конвейер предварительной обработки.
-
Алгоритмическая предобработка: Выполняются автоматическая очистка и дедупликация. К конфиденциальным путям данных применяется шифрование с нулевым разглашением (ZK-шифрование), позволяющее выполнять вычисления при минимизации раскрытия открытого текста, что отвечает требованиям корпоративных клиентов к конфиденциальности и соответствию.
-
Предварительная разметка моделью: Собственная модель автоматической разметки генерирует начальные метки. Для распространённых категорий данных ИИ проект заявляет уровень верификации, превышающий 80%, с обработкой динамических видеопотоков в реальном времени, что критически важно для сценариев, таких как покадровая разметка автономного вождения и видео промышленного контроля качества.
-
Оптимизационный цикл RLHF: Результаты верификации от участников подаются обратно в модель, постоянно снижая долю ручной проверки. Отраслевая практика показывает, что в цикле RLHF человеческое вмешательство можно сосредоточить примерно на 20% образцов высокой сложности, значительно снижая общие затраты и сроки (точные пропорции варьируются в зависимости от типа задачи).
-
Экспертный уровень истины: Для корпоративных заказов с высокой точностью платформа может развернуть внутреннюю команду предметных экспертов (инженеры, лингвисты, специалисты по визуализации и т.д.) в качестве финального арбитражного уровня, создавая двухдорожечную структуру «автоматизированная пропускная способность + экспертная точность» наряду с краудсорсинговыми результатами. Материалы 2026 года также подчёркивают, что массовые зашумлённые данные становятся операционным узким местом, а высококачественные вертикальные данные — это необходимое топливо для моделей и агентов следующего поколения.
Ценность этой гибридной архитектуры заключается в следующем: открытая сеть обеспечивает масштаб и скорость, в то время как закрытый экспертный конвейер поддерживает базовый уровень качества в отраслях, чувствительных к рискам, предотвращая неправильное понимание децентрализации как «низкокачественного краудсорсинга».
Как работает распределённый механизм семплирования данных
В отличие от «полного случайного сбора», Alaya AI делает акцент на интеллектуальную оптимизацию и целевой семплинг: отбор образцов с высокой информационной плотностью на основе целей модели, смягчая проблему «большого набора данных с низким эффективным сигналом».
Механизм семплинга можно понять с трёх точек зрения:
-
Ориентация на спрос: Клиенты ИИ отправляют пользовательские запросы (например, определённые диалекты, специализированные медицинские изображения, региональные дорожные условия). Платформа направляет рабочие единицы в пулы участников, соответствующих требуемому уровню NFT, языку или профессиональному опыту, достигая грубого соответствия между исполнителями и задачами.
-
Групповой избыточный семплинг: Несколько человек независимо размечают один и тот же пакет данных. Детекция согласованности выявляет метки-выбросы; образцы с низкой согласованностью автоматически поступают в очередь на проверку или в канал экспертов. Это заменяет полный надзор одного инспектора качества распределённой избыточностью.
-
Динамическое и статическое разделение: Задачи со статическими изображениями и задачи с динамическими видеопотоками используют разные стратегии пропускной способности. Динамическое зрение может интегрировать автоматическую сегментацию и покадровую разметку для снижения ручных затрат на кадр.
-
Временной и сценарный семплинг: Официальные сценарии включают использование фрагментированного времени (например, в дороге) для участия в лёгких задачах, превращая простаивающие человеческие ресурсы в производственный потенциал данных. Геймифицированный интерфейс (очки опыта, значения энергии) поддерживает долгосрочное удержание, делая пул семплинга непрерывным, а не разовым краудсорсинговым спринтом.
Очистка и дедупликация на этапе предобработки снижают смещение семплинга в источнике: если дубликаты образцов, повреждённые файлы или некорректные метаданные попадают в обучающий набор, они усиливают галлюцинации и смещения модели. Таким образом, семплинг — это не просто «сколько семплировать», но и системная инженерная работа, включающая «что семплировать, кто это делает и как верифицировать».
Как объединяются сети Web3 и ИИ
Атрибуты Web3 в Alaya AI не ограничиваются «оплатой токенами»; они включают токенизацию, превращение в NFT и управление ключевыми элементами координации сети данных.
-
Токен-координация: Родной токен AGT служит порогом для стейкинга, голосования по управлению, разблокировки продвинутых задач, апгрейда NFT и входа в пул стейкинга моделей. Дизайн стейкинга подчёркивает невозвратные затраты и безопасность. Проект явно заявляет, что стейкинг AGT сам по себе не обеспечивает пассивную доходность, предотвращая воздействие спекулятивного капитала на стимулы качества разметки.
-
Разрешения NFT: Alaya NFT и Medallion NFT формируют двухдорожечную систему идентификации, определяющую тип доступных задач, уровневые ограничения и системы достижений. Апгрейды высоких уровней потребляют AGT в определённых узлах, связывая ончейн-идентичность с офчейн-результатами труда.
-
Открытые комбинации стимулов: Проекты могут использовать AGT или собственные токены для создания пользовательских пулов данных, удовлетворяя предпочтения в расчётах Web3-ориентированных команд ИИ. Малые и средние разработчики могут начать загрузку наборов данных с меньшими денежными затратами через ODP.
-
Ончейн-аудит и происхождение: Для корпоративных клиентов платформа подчёркивает сквозную криптографическую целостность и неизменяемые аудиторские следы, делая происхождение данных прослеживаемым для поддержки проверок соответствия.
-
Геймификация и социальный рост: Механизмы, такие как ежедневные задания, реферальные комиссии и ежемесячный выкуп AGT (Redemption) (пользователи обменивают кредиты AIA, заработанные за задачи, на AGT в пуле выкупа с фиксированным временем), периодически переносят офчейн-активность в распределение ценности на цепочке.
-
Мультичейн-развёртывание: Снижает трения для пользователей в разных экосистемах. Одна и та же сеть данных может достигать групп пользователей на Arbitrum, opBNB и т.д. Дорожная карта также упоминает расширение на BNB Chain, Optimism и другие, чтобы адаптироваться к различиям в комиссиях и скорости.
Нарратив экосистемы 2026 года дополнительно позиционирует Alaya AI как основу данных для AI-агентов: агенты требуют непрерывной человеческой обратной связи и нишевых знаний, в то время как Web3-краудсорсинг в сочетании с автоматической разметкой обеспечивает масштабируемый конвейер обратной связи. Синергия с фреймворками интерактивных агентов в реальном времени (такими как обсуждаемые внешне возможности, похожие на OpenClaw) указывает на будущее с двойным циклом «обучение на лету + масштабные верифицированные наборы данных».
Анализ систем стейкинга моделей ИИ и вклада данных
Токенизация моделей ИИ — это ключевой механизм, отличающий Alaya AI от обычных платформ разметки: сообщество может финансировать и предоставлять трудовые вклады в данные для разработки и тонкой настройки конкретных моделей через стейкинг-пул AGT, упрощая согласование: «те, кто вносит данные, получают выгоду от улучшений модели».
-
Путь участника: Регистрация в dApp → Выполнение базовых задач для построения репутации → Стейкинг AGT для разблокировки задач более высокого уровня (верификация, калибровка, коллаборация по автоматической разметке) → Получение более высоких множителей вознаграждения; одновременно зарабатывание кредитов AIA для участия в ежемесячном выкупе на AGT.
-
Путь проекта: Публикация пользовательских запросов данных на платформе → Настройка пулов вознаграждений в AGT или сторонних токенах → Платформа назначает задачи соответствующим участникам → После автоматической разметки и ручного контроля качества — поставка набора данных → Опционально листинг или торговля на ODP.
-
Логика безопасности стейкинга: AGT служит инструментом координации Proof-of-Stake, повышая экономическую стоимость злонамеренной разметки и накрутки объёмов. В сочетании с Medallion NFT это дополнительно ограничивает доступ к задачам высокого уровня, защищая заказы на ценные данные.
-
Обратный поток ценности: Официальный план — использовать доход от услуг по обработке данных платформы для выкупа AGT и вливания его в пул пользовательских вознаграждений, пытаясь замкнуть бизнес-маховик «спрос клиентов → доход → повторное стимулирование → больше качественных данных». Его фактический эффект зависит от объёма корпоративных заказов и прозрачности выкупа.
Эта система трансформирует вклад данных из разовой работы в сетевую коллаборацию с участием: участники, стейкеры и проекты конкурируют и сотрудничают по одним и тем же правилам — структура Web3, которую традиционные SaaS-платформы разметки не могут поддерживать нативно.
Отличия Alaya AI от традиционных платформ данных для ИИ
| Измерение |
Alaya AI |
Традиционные платформы (например, Scale AI, Labelbox) |
| Организационная форма |
Распределённое сообщество + Открытая платформа |
Централизованные операции и корпоративные контракты |
| Стимулирование |
AGT, AIA, NFT, Геймификация |
В основном фиатная компенсация |
| Кастомизация данных |
Пользовательские пулы токенов, P2P-запросы |
Стандартные SLA и закупочные процессы |
| Выражение прав собственности |
NFT и ончейн-записи подчёркивают долю вклада |
Определяется контрактными условиями |
| Автоматизация |
Трёхуровневая авторазметка + RLHF + Экспертная проверка |
Зрелые конвейеры, много глубоких вертикальных кейсов (напр., авто) |
| Тип клиентов |
Web3-нативные и малые/средние AI-команды, расширение на предприятия продолжается |
Крупные технологические компании, преобладают госпроекты |
Преимущества Alaya AI лежат в длинном хвосте, кросc-граничности, быстром формировании пулов и прозрачности стимулов. Традиционные платформы превосходят в определённости поставок, юридической зрелости, отраслевых сертификациях и опыте работы с масштабными проектами. Децентрализованные сети не заменяют централизованных поставщиков во всех сценариях, но создают дифференциацию на пересечении «чувствительный к бюджету, вертикальная ниша, крипто-нативный».
Кроме того, Alaya делает акцент на высокоточные вертикальные данные, а не на бесконечное накопление объёмов, что отличается от традиционной логики конкуренции «больших наборов данных». Это более благоприятно для параметрически эффективных малых моделей и агентов, но также требует от клиентов принятия модели ценообразования и поставок гибридного конвейера (авто + эксперт).
Проблемы, стоящие перед децентрализованными сетями данных для ИИ
Несмотря на полную архитектуру, децентрализованные сети данных для ИИ сталкиваются с реальными ограничениями.
-
Баланс качества и масштаба: Среди миллионов зарегистрированных пользователей долю стабильно высококачественных разметчиков трудно проверить извне. Если стимулы способствуют накрутке объёмов, это навредит продлениям клиентов ИИ и репутации сети.
-
Барьеры внедрения на предприятиях: Юридические аспекты, SOC2, выделенные менеджеры проектов, компенсация инцидентов и т.д. — это стандартные требования корпоративных закупок. Одной лишь ончейн-прозрачности недостаточно для подписания крупных контрактов; требуется непрерывное накопление проверяемых кейсов.
-
Сложность пользовательского опыта: Кошельки, NFT, дуальные токены (AGT/AIA), правила стейкинга и выкупа увеличивают стоимость обучения для новых пользователей, потенциально ограничивая приток участников не из Web3.
-
Регуляторная неопределённость: Трансграничные данные, труд, стимулируемый токенами, и соответствие требованиям для чувствительных данных, таких как медицинские, различаются по странам. Изменения политики могут повлиять на регионы деятельности и дизайн токенов.
-
Ликвидность и устойчивость стимулов: Рыночная капитализация AGT и объём торгов всё ещё малы по сравнению с более широким рынком. Если доходы платформы и выкупы не будут поспевать за объёмами разблокировки и выкупа, стимулы могут зависеть от новых пользователей, а не от внутреннего денежного потока.
-
Технические риски: Уязвимости смарт-контрактов, ошибки привязки кошельков, препятствующие получению выкупа, и усиление ошибок модели автоматической разметки на категориях длинного хвоста требуют постоянных инженерных инвестиций.
-
Конкурентное давление: Централизованные гиганты обладают глубокими карманами и высокой привязанностью клиентов. Другие Web3-проекты данных также конкурируют за тот же нарратив, и дифференциация должна быть подтверждена поставленными данными.
Будущие направления развития технологий Alaya AI
Объединяя официальную дорожную карту и динамику 2025–2026 годов, техническая эволюция, вероятно, сосредоточится на следующих направлениях.
-
Глубокая интеграция авторазметки и RLHF: Повышение возможностей обработки в реальном времени для динамического зрения, многоязычных данных и данных обратной связи от агентов, сокращение цикла «собрать → разметить → развернуть обратно в модель».
-
ODP и социализированное сотрудничество по данным: Расширение от начальной загрузки наборов данных до более активных функций торговли, обмена и совместной работы, усиление сетевых эффектов.
-
DAO и улучшение управления: Передача большего числа решений (например, приоритеты функций авторазметки, экономические параметры) на голосование стейкеров AGT, повышение доверия к нарративам суверенитета сообщества.
-
Мультичейн и синергия вычислительной экосистемы: Интеграция с DePIN, децентрализованными вычислениями (например, Akash, Golem) и протоколами рынков моделей (например, Bittensor), исследование открытого стека «данные → обучение → инференс» для снижения привязки к одной платформе.
-
Позиционирование в эпоху агентов: Постоянное укрепление высокоточных данных с участием человека в цикле как основы рассуждений для агентов; сотрудничество с фреймворками обучения агентов в реальном времени для формирования быстрых и медленных двойных циклов.
-
Повышение корпоративного соответствия: Расширение ZK-шифрования, аудита происхождения и охвата экспертных проверок для выигрыша заказов в строго регулируемых отраслях, таких как здравоохранение и финансы.
Такие механизмы, как ежемесячный выкуп AGT в 2026 году, указывают на то, что операционная сторона использует фиксированный ритм для поддержания ожиданий участников. Соответствие технической стороны операционному ритму зависит от устойчивых инвестиций в точность авторазметки, алгоритмы маршрутизации задач и экспертный уровень.
Заключение
Децентрализованная сеть данных для ИИ Alaya AI по сути является многоуровневой системой сотрудничества: уровень приложений снижает барьеры для участия, уровень производства данных повышает эффективность с помощью авторазметки и распределённого семплинга, уровень интеллектуальной оптимизации поглощает человеческие знания через RLHF, а уровень ончейн-координации согласовывает стимулы и безопасность с помощью AGT, NFT и правил управления. Открытая платформа данных обновляет сеть с платформы задач до компонуемого маркетплейса данных, в то время как пул стейкинга моделей вводит капитал и труд сообщества в цикл тонкой настройки модели.
Значение её операционной логики для индустрии ИИ заключается в следующем: когда высококачественные вертикальные данные становятся узким местом, одной централизованной закупки недостаточно для охвата длиннохвостой и глобально фрагментированной рабочей силы; архитектура Web3 предлагает альтернативную кривую предложения. В то же время проблемы реальны — верификация качества, корпоративные SLA, регулирование и устойчивость стимулов определят, сможет ли эта техническая архитектура перейти от «демонстрируемой» к «масштабируемо коммерческой».
Для технических наблюдателей оценка Alaya AI не должна ограничиваться ончейн-объёмами транзакций или регистрациями пользователей; необходимо отслеживать жёсткие показатели, такие как уровень верификации авторазметки, транзакции ODP, продления корпоративных клиентов и исполнение выкупов. Эти показатели в совокупности отвечают на один вопрос: может ли децентрализованная сеть данных для ИИ одновременно превзойти основные преимущества традиционных платформ в эффективности и надёжности?








