Perusahaan keamanan BlockSec telah melakukan pengujian ulang standar penilaian audit kontrak pintar menggunakan AI bernama EVMBench, yang dikembangkan oleh OpenAI dan Paradigm. Hasilnya menunjukkan bahwa bot AI kurang efektif secara signifikan ketika menghadapi skenario eksploitasi nyata.
Tim peneliti telah memperluas lingkungan pengujian dengan lebih banyak konfigurasi model, sekaligus menambahkan insiden keamanan baru yang terjadi belakangan ini — data yang belum pernah muncul dalam data pelatihan model AI.
Meskipun AI belum mampu menggantikan para ahli keamanan, laporan menekankan bahwa kecerdasan mesin dapat berperan sebagai pelengkap alami dalam proses pemeriksaan kode manusia.
Hasil awal EVMBench mungkin terlalu optimistis
EVMBench sebelumnya menilai tugas keamanan kontrak pintar seperti deteksi, patch bug, dan eksploitasi kerentanan, dengan hasil yang dianggap sangat mengesankan. Menurut laporan, AI dapat mengeksploitasi 72% dan mendeteksi sekitar 45% kerentanan, berdasarkan 120 sampel yang dipilih dari audit Code4rena.
Namun, BlockSec berpendapat bahwa kondisi pengujian awal mungkin telah menyebabkan hasil yang menyesatkan. Co-founder Yajin Zhou mengatakan bahwa ketika timnya mengulang pengujian dengan lebih banyak konfigurasi dan 22 insiden serangan nyata, tingkat keberhasilan eksploitasi AI adalah 0%.
Memperluas konfigurasi dan menghilangkan “kontaminasi data”
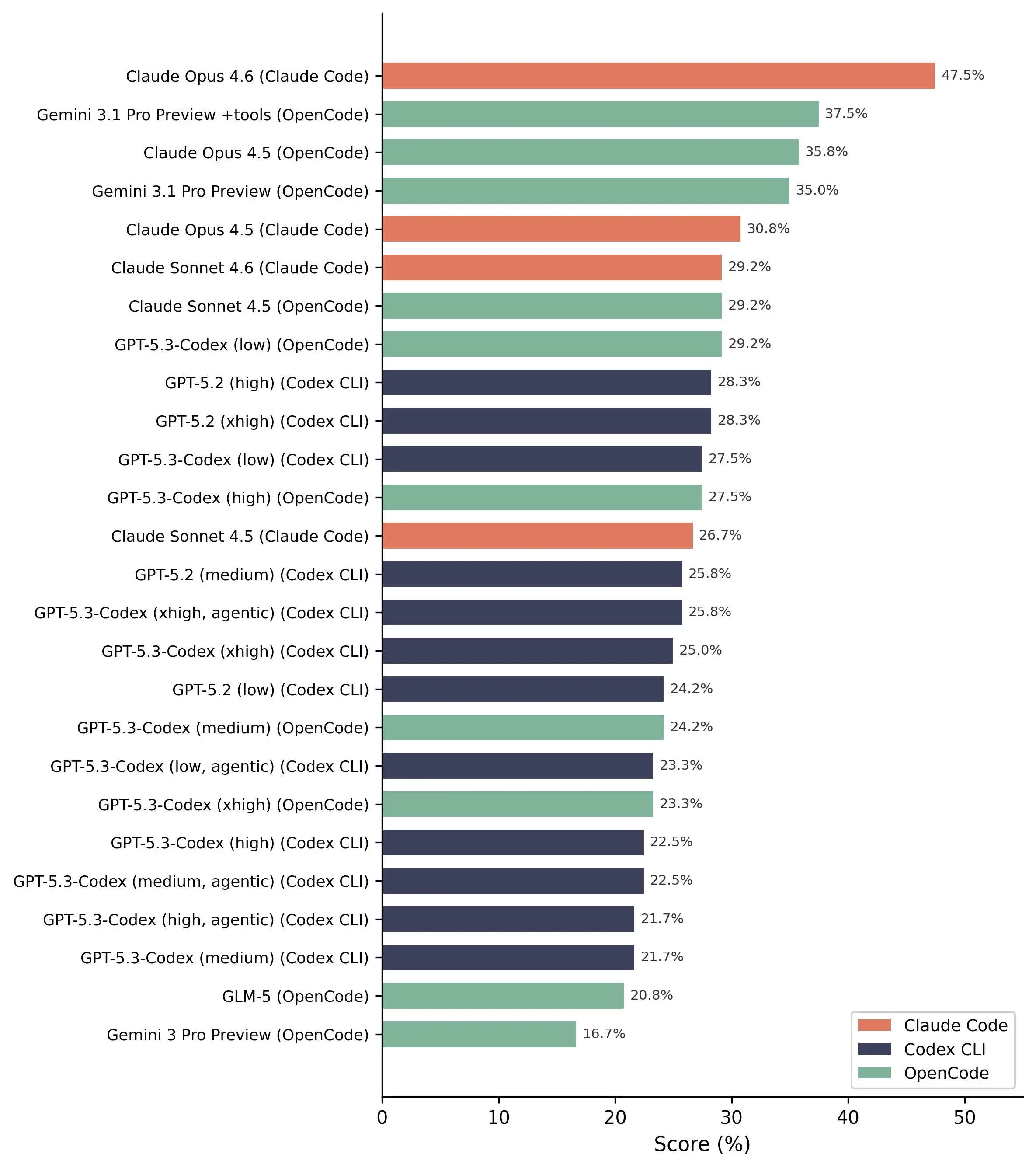
Penelitian ini meningkatkan jumlah konfigurasi model dari 14 menjadi 26 dengan menggabungkan bot secara fleksibel dengan berbagai “scaffold”, bukan hanya terbatas dalam ekosistem masing-masing penyedia. Menurut tim peneliti, pendekatan lama membuat sulit membedakan performa yang berasal dari kemampuan model atau keunggulan arsitektur.
Selain itu, BlockSec juga meragukan fenomena “kontaminasi data”, ketika EVMBench menggunakan kerentanan yang sudah dipublikasikan sebelumnya — yang berpotensi sudah termasuk dalam data pelatihan AI. Untuk mengatasi hal ini, tim melakukan pengujian terhadap 22 insiden keamanan yang terjadi setelah Februari 2026, di luar “jendela pengetahuan” model.
AI sepenuhnya gagal dalam eksploitasi nyata
Hasil yang paling mencolok: dari 110 pasangan pengujian antara agen dan insiden (5 agen dari 22 situasi), tidak ada satu pun kasus eksploitasi lengkap yang berhasil. Ini menunjukkan bahwa bahkan AI paling canggih saat ini masih sangat jauh dari mampu melakukan serangan nyata.
Namun, dalam hal deteksi kerentanan, hasilnya cukup positif. Model Claude Opus 4.6 mencapai performa terbaik dengan mendeteksi 13 dari 20 kerentanan yang terjadi secara nyata.
Kerentanan yang umum dan familiar biasanya mudah dideteksi AI, tetapi kasus yang lebih kompleks hampir selalu terlewatkan sepenuhnya.
Masa depan adalah kolaborasi antara AI dan manusia
Penelitian menyimpulkan bahwa AI belum mampu menggantikan manusia dalam audit keamanan, dan pertanyaan yang lebih penting adalah bagaimana kedua pihak dapat bekerja sama secara efektif.
AI memiliki keunggulan dalam cakupan luas dan kemampuan untuk memindai sistem secara besar-besaran, sementara manusia unggul dalam analisis mendalam, pemahaman protokol, dan penalaran kontra-argumentasi. Kedua faktor ini saling melengkapi.
Menurut BlockSec, pendekatan yang tepat bukanlah menggantikan manusia dengan AI, melainkan membangun model kolaborasi antara keduanya untuk mencapai efektivitas audit yang lebih menyeluruh.
Thach Sanh
Penafian: Informasi di halaman ini dapat berasal dari pihak ketiga dan tidak mewakili pandangan atau opini Gate. Konten yang ditampilkan hanya untuk tujuan referensi dan bukan merupakan nasihat keuangan, investasi, atau hukum. Gate tidak menjamin keakuratan maupun kelengkapan informasi dan tidak bertanggung jawab atas kerugian apa pun yang timbul akibat penggunaan informasi ini. Investasi aset virtual memiliki risiko tinggi dan rentan terhadap volatilitas harga yang signifikan. Anda dapat kehilangan seluruh modal yang diinvestasikan. Harap pahami sepenuhnya risiko yang terkait dan buat keputusan secara bijak berdasarkan kondisi keuangan serta toleransi risiko Anda sendiri. Untuk detail lebih lanjut, silakan merujuk ke
Penafian.
