Alors que les modèles d'IA évoluent vers la multimodalité, les cas d'usage verticaux et les agents intelligents (Agents), le consensus du secteur passe de « plus de données, c'est mieux » à « des données à haute fidélité, traçables et respectueuses de la vie privée constituent la ressource rare ». Les plateformes de labellisation centralisées traditionnelles rencontrent des goulets d'étranglement en termes de coûts, de réponse à la demande de longue traîne et de répartition équitable des contributions. Les réseaux de données d'IA décentralisés cherchent à redéfinir les relations de production de données grâce à l'intelligence collective, à la coordination par Tokens et à des interfaces ouvertes. Pour comprendre le fonctionnement d'Alaya AI, il convient d'examiner ses couches techniques, son pipeline d'auto-labellisation, sa logique d'échantillonnage et ses mécanismes économiques on-chain, plutôt que de le réduire à un simple « service d'externalisation de labellisation alimenté par la Blockchain ».
D'un point de vue architectural, Alaya AI incarne la convergence de Web3 et de l'IA au niveau de la couche de données : les contributions peuvent être incitées, les autorisations de tâches sont NFTisées, et le développement de modèles peut être financé par le soutien de la communauté via le pool de staking AGT. La Plateforme de données ouvertes (ODP) fait le pont entre l'offre et la demande. Les sections suivantes détaillent l'architecture centrale du réseau, ses mécanismes d'amélioration de l'efficacité, l'intégration Web3, les systèmes de staking et de contribution, les différences avec les plateformes traditionnelles, les défis concrets et les orientations futures, offrant un cadre structuré pour évaluer sa faisabilité technique et sa valeur écosystémique.
Analyse de l'architecture technique centrale d'Alaya AI
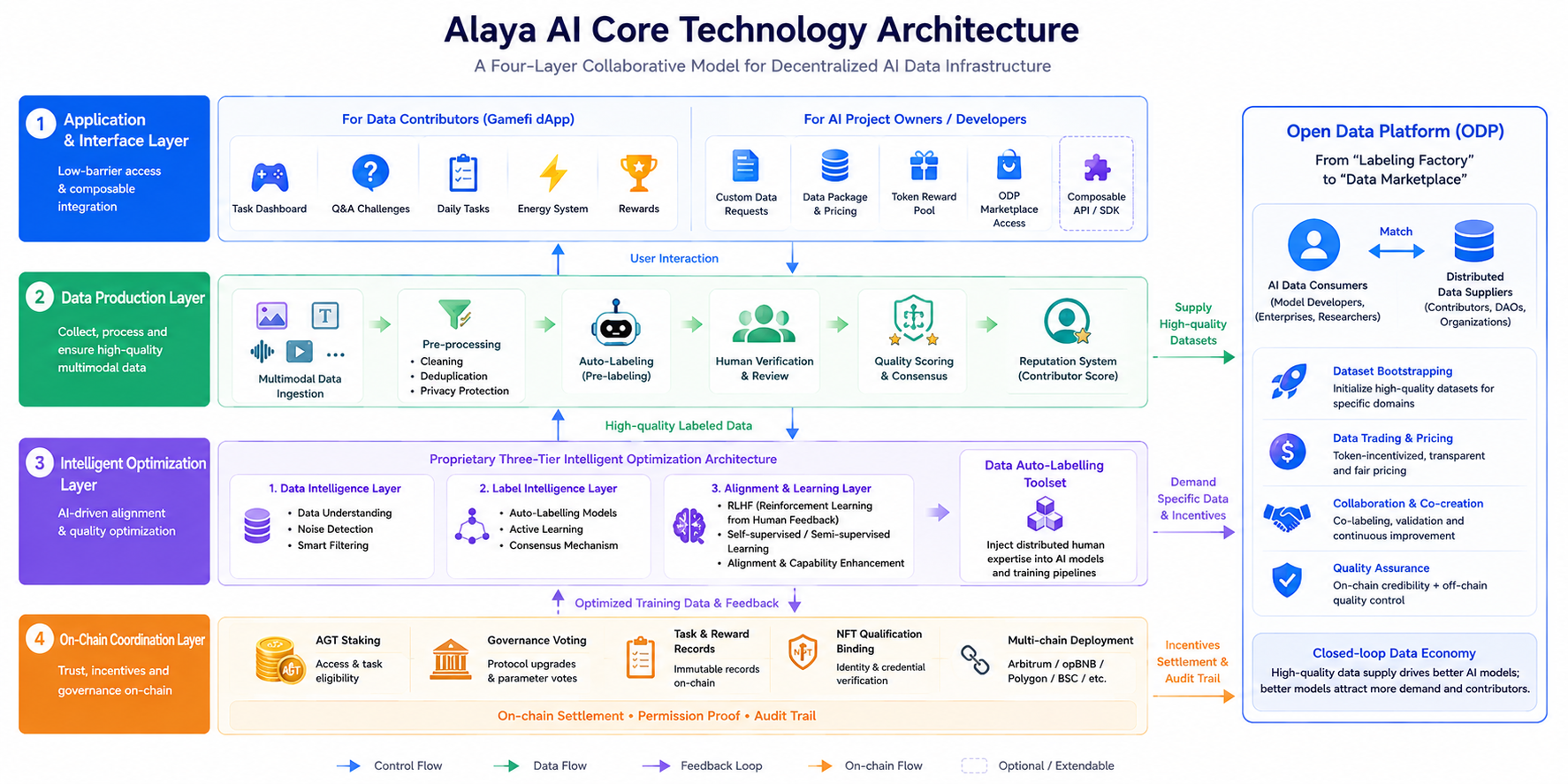
L'architecture globale d'Alaya AI repose sur un modèle collaboratif à quatre couches, où chaque couche assume des responsabilités clairement séparées avec des flux de données et de contrôle distincts, évitant ainsi la surcharge de performance liée au fait de « tout mettre sur la chaîne ».
-
Couche d'application et d'interface. Elle comprend une dApp gamifiée pour les contributeurs de données (panneaux de tâches, défis, tâches quotidiennes, etc.), ainsi que des demandes de données personnalisées, des offres de packages de données et l'accès au marché ODP pour les équipes de projet d'IA. Cette couche privilégie une participation à faible barrière et un accès modulable, permettant aux développeurs de publier des besoins de données verticaux via des pools de récompenses tokenisés personnalisés.
-
Couche de production de données. Elle gère l'absorption de données multimodales (texte, images, vidéo, audio), le prétraitement (nettoyage, déduplication, protection de la vie privée), l'auto-labellisation, la vérification manuelle et la notation de qualité. Alaya AI s'appuie sur les principes de l'intelligence collective : une même tâche peut être étiquetée de manière croisée par plusieurs contributeurs, utilisant des mécanismes de consensus ou de majorité pour améliorer la cohérence des étiquettes, tandis que la précision historique construit une réputation de contributeur qui influence l'attribution future des tâches.
-
Couche d'optimisation intelligente. Le composant central est l'ensemble d'outils d'auto-labellisation des données, piloté par une architecture d'optimisation intelligente propriétaire à trois couches. Combiné au réglage fin RLHF (apprentissage par renforcement à partir du feedback humain), il injecte une expertise humaine distribuée dans les processus auto-supervisés et semi-supervisés, soutenant l'alignement et l'amélioration des capacités du modèle.
-
Couche de coordination on-chain. Les informations de coordination clés—staking d'AGT, vote de gouvernance, statut des tâches et des récompenses, liaison des qualifications NFT—reposent sur la blockchain (les déploiements couvrent plusieurs chaînes, notamment Arbitrum, opBNB, Polygon et BSC ; se référer aux annonces officielles). La chaîne ne stocke pas de gros volumes de données brutes, mais gère le règlement des incitations, la preuve d'autorisation et l'ancrage de la piste d'audit, suivant le paradigme courant de conception Web3 IA : « calcul off-chain, confiance on-chain ».
Lancée en novembre 2024, la Plateforme de données ouvertes (ODP) transforme le réseau d'une « usine d'étiquetage » en un « marché de données » : les consommateurs de données d'IA et les fournisseurs distribués se connectent directement via des incitations tokenisées personnalisables, prenant en charge l'amorçage, le commerce et la collaboration de jeux de données pour créer une boucle fermée offre-demande.
L'auto-labellisation est un module central permettant à Alaya AI de réduire les coûts marginaux et de raccourcir les cycles de livraison. Le projet le positionne comme la prochaine phase de l'évolution de l'IA auto-supervisée : les machines génèrent d'abord des étiquettes candidates, puis les humains se concentrent sur les échantillons ambigus et les jugements spécifiques au domaine, plutôt que d'étiqueter manuellement chaque donnée à partir de zéro.
Le processus technique comprend généralement ces étapes :
-
Absorption multimodale : La chaîne d'outils accepte les données visuelles statiques et dynamiques, le texte et les entrées de capteurs, qui entrent toutes dans un pipeline de prétraitement unifié.
-
Prétraitement algorithmique : Un nettoyage et une déduplication automatiques sont effectués. Un chiffrement à connaissance nulle (chiffrement ZK) est appliqué aux chemins de données sensibles, permettant le calcul tout en minimisant l'exposition en texte clair, répondant aux exigences des clients entreprises en matière de confidentialité et de conformité.
-
Pré-étiquetage par modèle : Un modèle d'auto-labellisation propriétaire génère des étiquettes initiales. Pour les catégories de données d'IA courantes, le projet revendique un taux de vérification supérieur à 80 %, avec un traitement en temps réel des flux visuels dynamiques—essentiel pour des cas comme l'étiquetage d'images de conduite autonome ou les vidéos d'inspection qualité industrielle.
-
Boucle d'optimisation RLHF : Les résultats de vérification des contributeurs sont réinjectés dans le modèle, réduisant continuellement la proportion de révision manuelle. La pratique du secteur montre que dans une boucle RLHF, l'intervention humaine peut être concentrée sur environ 20 % des échantillons à haute difficulté, réduisant considérablement les coûts globaux et les délais (les proportions exactes varient selon le type de tâche).
-
Couche de vérité experte : Pour les commandes de haute fidélité de niveau entreprise, la plateforme peut déployer une équipe interne d'experts du domaine (ingénieurs, linguistes, spécialistes visuels, etc.) comme couche d'arbitrage finale, créant une structure à double voie « débit automatisé + précision experte » parallèlement aux résultats crowdsourcés. Les documents de 2026 soulignent également que les données massives et bruyantes deviennent un goulot d'étranglement opérationnel, et que les données verticales à haute fidélité constituent le carburant indispensable pour les modèles et agents de nouvelle génération.
La valeur de cette architecture hybride réside dans le fait que le réseau public offre échelle et rapidité, tandis que le pipeline expert fermé maintient des bases de qualité dans les industries sensibles aux risques, évitant que la décentralisation ne soit perçue comme un « crowdsourcing de faible qualité ».
Contrairement au « scraping aléatoire complet », Alaya AI mise sur l'optimisation intelligente et l'échantillonnage ciblé : sélectionner des échantillons à haute densité d'information en fonction des objectifs du modèle, atténuant le problème du « grand jeu de données, faible signal efficace ».
Le mécanisme d'échantillonnage peut se comprendre sous trois angles :
-
Piloté par la demande : Les clients IA soumettent des demandes personnalisées (par exemple, dialectes spécifiques, images médicales spécialisées, conditions de circulation régionales). La plateforme achemine les unités de travail vers des pools de contributeurs correspondant au niveau NFT requis, à la langue ou au bagage professionnel, réalisant un alignement grossier entre la main-d'œuvre et les tâches.
-
Échantillonnage par redondance de groupe : Plusieurs personnes étiquettent indépendamment le même lot de données. La détection de cohérence identifie les étiquettes aberrantes ; les échantillons de faible cohérence entrent automatiquement dans une file de révision ou un canal expert. Cela remplace la supervision complète d'un seul inspecteur qualité par une redondance distribuée.
-
Diversion dynamique et statique : Les tâches d'images statiques et les tâches de flux vidéo dynamiques utilisent des stratégies de débit différentes. La vision dynamique peut intégrer la segmentation automatique et l'étiquetage au niveau de l'image pour réduire les coûts manuels par image.
-
Échantillonnage temporel et scénariel : Les scénarios officiels incluent l'utilisation de temps fragmenté (par exemple, les trajets) pour participer à des tâches légères, convertissant la main-d'œuvre inactive en capacité de production de données. Une interface utilisateur gamifiée (points d'expérience, valeurs d'énergie) maintient la rétention à long terme, rendant le pool d'échantillonnage continu plutôt qu'un sprint de crowdsourcing ponctuel.
Le nettoyage et la déduplication dans le prétraitement réduisent le biais d'échantillonnage à la source : si des échantillons en double, des fichiers corrompus ou des métadonnées incorrectes intègrent l'ensemble d'entraînement, ils amplifient les hallucinations et les biais du modèle. Par conséquent, l'échantillonnage ne se limite pas au « combien échantillonner », mais constitue un effort d'ingénierie systématique impliquant « quoi échantillonner, qui le fait et comment vérifier ».
Les attributs Web3 d'Alaya AI ne se résument pas à « payer avec des jetons », mais impliquent la tokenisation, la NFTisation et la gouvernance des éléments de coordination clés du réseau de données.
-
Coordination par Token : Le jeton natif AGT sert de seuil de staking, de vote de gouvernance, de déverrouillage de tâches avancées, de mise à niveau NFT et d'entrée de financement du pool de staking de modèles. La conception du staking met l'accent sur le coût irrécupérable et la sécurité. Le projet précise que le staking d'AGT lui-même ne génère pas de rendement passif, empêchant ainsi le capital spéculatif de perturber les incitations à la qualité de l'étiquetage.
-
Permissions NFT : Le NFT Alaya et le NFT Medallion forment un système d'identité à double voie, déterminant le type de tâches accessibles, les plafonds de niveau et les systèmes de réalisations. Les mises à niveau de haut niveau consomment de l'AGT à des nœuds spécifiques, liant l'identité on-chain à la production de travail hors ligne.
-
Combinaisons d'incitations ouvertes : Les projets peuvent utiliser AGT ou leurs propres jetons pour créer des pools de données personnalisés, répondant aux préférences de règlement des équipes d'IA natives Web3. Les petits et moyens développeurs peuvent amorcer des jeux de données avec des coûts en espèces plus faibles via l'ODP.
-
Audit et lignée on-chain : Pour les clients entreprises, la plateforme met l'accent sur l'intégrité cryptographique de bout en bout et des pistes d'audit immuables, rendant la lignée des données traçable pour soutenir les examens de conformité.
-
Gamification et croissance sociale : Les mécanismes comme les tâches quotidiennes, les commissions de parrainage et le rachat mensuel d'AGT (les utilisateurs échangent des crédits AIA gagnés via des tâches contre de l'AGT dans un pool de rachat à durée déterminée) cartographient périodiquement l'activité hors ligne vers la distribution de valeur on-chain.
-
Déploiement multi-chaîne : Il réduit les frictions pour les utilisateurs de différents écosystèmes. Le même réseau de données peut atteindre des groupes d'utilisateurs sur Arbitrum, opBNB, etc. La feuille de route mentionne également l'expansion vers BNB Chain, Optimism, etc., pour s'adapter aux différences de frais et de vitesse.
Le récit écosystémique de 2026 positionne Alaya AI comme l'épine dorsale des données pour les Agents IA : les agents nécessitent un retour humain continu et des connaissances de niche, tandis que le crowdsourcing Web3 combiné à l'auto-labellisation fournit un pipeline de retour évolutif. La synergie avec les frameworks d'agents interactifs en temps réel (tels que les capacités de type OpenClaw discutées en externe) pointe vers un avenir de double boucle « apprentissage à la volée + jeux de données vérifiés à grande échelle ».
Analyse des systèmes de staking de modèles d'IA et de contribution de données
La tokenisation des modèles d'IA est un mécanisme clé qui distingue Alaya AI des plateformes d'étiquetage généralistes : la communauté peut financer et fournir du travail de données pour le développement et le réglage fin de modèles spécifiques via le pool de staking AGT, facilitant ainsi l'alignement entre « ceux qui contribuent aux données bénéficient des améliorations du modèle ».
-
Parcours du contributeur : S'inscrire à la dApp → Effectuer des tâches de base pour construire une réputation → Stake des AGT pour débloquer des tâches de niveau supérieur (vérification, calibrage, collaboration d'auto-labellisation) → Obtenir des multiplicateurs de récompense plus élevés ; gagner simultanément des crédits AIA pour participer au rachat mensuel d'AGT.
-
Parcours du projet : Publier des demandes de données personnalisées sur la plateforme → Configurer des pools de récompenses en AGT ou en jetons tiers → La plateforme attribue des tâches aux contributeurs correspondants → Après auto-labellisation et contrôle qualité manuel, livrer le jeu de données → Optionnellement lister ou échanger sur l'ODP.
-
Logique de sécurité du staking : AGT sert d'outil de coordination Proof-of-Stake, augmentant le coût économique de l'étiquetage malveillant et de la génération de volume. Combiné au Medallion NFT, il restreint davantage l'accès aux tâches de haut niveau, protégeant les commandes de données de grande valeur.
-
Retour de valeur : Le plan officiel consiste à utiliser les revenus des services de données de la plateforme pour racheter de l'AGT et l'injecter dans le pool de récompenses des utilisateurs, tentant de fermer la boucle commerciale « demande client → revenus → ré-incitation → plus de données de haute qualité ». Son efficacité réelle dépend du volume de commandes des entreprises et de la transparence du rachat.
Ce système transforme la contribution de données d'un travail ponctuel en une collaboration réseau avec participation : les contributeurs, les stakeurs et les projets rivalisent et coopèrent sous le même ensemble de règles—une structure Web3 que les plateformes d'étiquetage SaaS traditionnelles ne peuvent pas prendre en charge nativement.
| Dimension |
Alaya AI |
Plateformes traditionnelles (ex. Scale AI, Labelbox) |
| Forme organisationnelle |
Communauté distribuée + Plateforme ouverte |
Opérations centralisées et contrats entreprises |
| Incitation |
AGT, AIA, NFT, Gamification |
Rémunération principalement en Fiat |
| Personnalisation des données |
Pools de jetons personnalisés, demandes P2P |
SLA standard et processus d'approvisionnement |
| Expression de la propriété |
NFT et enregistrements on-chain mettent l'accent sur l'équité des contributions |
Termes contractuels définissent |
| Automatisation |
Auto-labellisation à trois couches + RLHF + Révision experte |
Pipelines matures, nombreux cas verticaux approfondis (ex. automobile) |
| Type de client |
Natifs Web3 et petites/moyennes équipes d'IA, expansion entreprises en cours |
Grandes entreprises technologiques, projets gouvernementaux dominent |
Les atouts d'Alaya AI résident dans la longue traîne, le transfrontalier, la formation rapide de pools et les incitations transparentes. Les plateformes traditionnelles excellent dans la certitude de livraison, la maturité juridique, les certifications sectorielles et l'expérience des projets à très grande échelle. Les réseaux décentralisés ne remplacent pas les fournisseurs centralisés dans tous les scénarios, mais établissent une différenciation dans l'intersection de « sensible au budget, niche verticale, crypto-natif ».
De plus, Alaya privilégie les données verticales à haute fidélité plutôt que l'empilement de volume infini, différant de la logique de compétition traditionnelle des « grands ensembles de données ». Cela favorise les petits modèles et agents efficaces en paramètres, mais exige également des clients qu'ils acceptent le modèle de tarification et de livraison d'un pipeline hybride (automatique + expert).
Défis auxquels sont confrontés les réseaux de données d'IA décentralisés
Malgré l'architecture complète, les réseaux de données d'IA décentralisés font face à des contraintes bien réelles.
-
Équilibre qualité et échelle : Parmi des millions d'utilisateurs enregistrés, la proportion d'étiqueteurs de haute qualité constante est difficile à vérifier en externe. Si les incitations favorisent la génération de volume, cela nuira au renouvellement des clients IA et à la réputation du réseau.
-
Obstacles à l'adoption par les entreprises : Juridique, SOC2, chefs de projet dédiés, indemnisation des accidents, etc., sont des exigences d'approvisionnement standard pour les entreprises. La transparence on-chain seule ne suffit pas pour signer de gros contrats ; une accumulation continue de cas audités est nécessaire.
-
Complexité de l'expérience utilisateur : Les portefeuilles, les NFT, les doubles jetons (AGT/AIA), le staking et les règles de rachat augmentent le coût d'apprentissage pour les nouveaux utilisateurs, limitant potentiellement l'afflux de contributeurs non Web3.
-
Incertitude réglementaire : Les données transfrontalières, le travail incité par jetons et la conformité pour les données sensibles comme la santé varient selon les pays. Les changements de politique peuvent affecter les régions d'exploitation et la conception des jetons.
-
Durabilité des liquidités et des incitations : La capitalisation boursière et le volume de transactions d'AGT sont encore faibles par rapport au marché global. Si les revenus de la plateforme et les rachats ne peuvent pas suivre le rythme des déverrouillages et de l'offre de rachat, les incitations pourraient reposer sur de nouveaux utilisateurs plutôt que sur des flux de trésorerie internes.
-
Risques techniques : Vulnérabilités des Smart Contracts, erreurs de liaison de portefeuille empêchant la collecte des rachats, amplification des erreurs du modèle d'auto-labellisation sur les catégories de longue traîne—nécessitent un investissement d'ingénierie continu.
-
Pression concurrentielle : Les géants centralisés disposent de moyens financiers importants et d'une forte fidélité client. D'autres projets de données Web3 rivalisent également pour le même récit, et la différenciation doit être prouvée avec des données livrées.
Orientations futures du développement technologique d'Alaya AI
Combinant la feuille de route officielle et la dynamique 2025–2026, l'évolution technique se concentrera probablement sur les axes suivants.
-
Intégration approfondie de l'auto-labellisation et du RLHF : Améliorer les capacités de traitement en temps réel pour la vision dynamique, le multilinguisme et les données de retour des agents, raccourcissant le cycle « collecter → étiqueter → redéployer vers le modèle ».
-
ODP et collaboration de données socialisée : Passer de l'amorçage de jeux de données à des fonctionnalités plus actives de trading, de partage et de collaboration, renforçant les effets de réseau.
-
DAO et amélioration de la gouvernance : Soumettre plus de décisions (par exemple, priorités des fonctionnalités d'auto-labellisation, paramètres économiques) au vote des stakeurs AGT, augmentant la crédibilité des récits de souveraineté communautaire.
-
Synergie multi-chaîne et écosystème de calcul : Intégration avec DePIN, le calcul décentralisé (par exemple, Akash, Golem) et les protocoles de marché de modèles (par exemple, Bittensor), explorant la pile ouverte « données → entraînement → inférence » pour réduire le verrouillage sur une seule plateforme.
-
Positionnement à l'ère des agents : Renforcer continuellement les données à haute fidélité avec intervention humaine comme colonne vertébrale de raisonnement pour les agents ; collaborer avec les frameworks d'apprentissage d'agents en temps réel pour former des doubles boucles rapide-lent.
-
Amélioration de la conformité entreprises : Étendre le chiffrement ZK, l'audit de lignée et la couverture de révision experte pour remporter des commandes dans les industries hautement réglementées comme la santé et la finance.
Des mécanismes comme le rachat mensuel d'AGT en 2026 indiquent que le côté opérationnel utilise un rythme fixe pour maintenir les attentes des contributeurs. Que le côté technique corresponde au rythme opérationnel dépend d'un investissement soutenu dans la précision de l'auto-labellisation, les algorithmes de routage des tâches et la couche experte.
Résumé
Le réseau de données d'IA décentralisé d'Alaya AI repose essentiellement sur un système de collaboration en couches : la couche d'application abaisse les barrières à la participation, la couche de production de données améliore l'efficacité avec l'auto-labellisation et l'échantillonnage distribué, la couche d'optimisation intelligente absorbe les connaissances humaines via le RLHF, et la couche de coordination on-chain aligne les incitations et la sécurité avec AGT, NFT et les règles de gouvernance. La Plateforme de données ouvertes fait passer le réseau d'une plateforme de tâches à un marché de données modulable, tandis que le pool de staking de modèles introduit le capital et le travail de la communauté dans la boucle de réglage fin des modèles.
L'importance de sa logique opérationnelle pour l'industrie de l'IA est la suivante : lorsque les données verticales de haute qualité deviennent un goulot d'étranglement, l'approvisionnement centralisé seul ne peut pas couvrir la main-d'œuvre fragmentée de longue traîne et mondiale ; l'architecture Web3 offre une courbe d'offre alternative. En même temps, les défis sont bien réels—vérification de la qualité, SLA des entreprises, réglementation et durabilité des incitations détermineront si cette architecture technique peut passer de « démontrable » à « commercialement évolutive ».
Pour les observateurs techniques, évaluer Alaya AI ne devrait pas se limiter aux volumes de transactions on-chain ou aux inscriptions d'utilisateurs, mais aussi suivre des indicateurs durs tels que les taux de vérification d'auto-labellisation, les transactions ODP, les renouvellements de clients entreprises et l'exécution des rachats. Ces indicateurs répondent collectivement à une question : un réseau de données d'IA décentralisé peut-il simultanément surpasser les atouts des plateformes traditionnelles en matière d'efficacité et de fiabilité ?








