Tras el avance acelerado de las capacidades de los modelos grandes, las empresas ya no se preocupan principalmente por “si un modelo está disponible”, sino por “si puede funcionar de manera fiable y sostenible en entornos empresariales reales”. Aunque los clústeres de entrenamiento pueden reunir potencia de hash, los sistemas de producción deben gestionar solicitudes continuas, latencia final, iteración de versiones, permisos de datos y responsabilidad ante incidentes. En definitiva, el campo de batalla central de la IA empresarial se desplaza hacia la inferencia y los frameworks operativos. Los agentes amplían los retos, pasando de “preguntas y respuestas de un solo turno” a “tareas de varios pasos, invocación de herramientas y gestión de estados”, elevando considerablemente el nivel de exigencia para la infraestructura y la gobernanza.
Si ves la infraestructura de IA como una cadena continua que va desde chips hasta centros de datos, servicios y gobernanza, este artículo se centra en el extremo final de la cadena: servicios de inferencia, acceso a datos y gobernanza organizacional. Los temas aguas arriba, como HBM, energía y centros de datos, se abordan mejor en discusiones sobre la oferta; este artículo asume que los lectores ya tienen conocimientos básicos sobre arquitecturas por capas.
Por qué “inferencia en producción” y “potencia de hash para entrenamiento” son retos diferentes
Aunque entrenamiento e inferencia comparten componentes de hardware como GPU, redes y almacenamiento, sus objetivos de optimización son distintos. El entrenamiento busca rendimiento y paralelismo de larga duración; la inferencia prioriza concurrencia, latencia final, coste por solicitud y el ritmo de lanzamientos y reversión de versiones. Para las empresas, estas diferencias impactan directamente en las decisiones arquitectónicas y los límites de adquisición:
-
Estructura de costes: El entrenamiento suele ser un gasto de capital por fases, mientras que los costes de inferencia escalan linealmente con el volumen de negocio y son más sensibles al caché, procesamiento por lotes, enrutamiento y selección de modelos.
-
Definición de disponibilidad: Las tareas de entrenamiento pueden ponerse en cola y reintentarse; la inferencia online suele estar sujeta a SLA, requiriendo limitación de tasa, degradación y estrategias de réplicas múltiples.
-
Frecuencia de cambios: Las actualizaciones de modelos, prompts, políticas de herramientas y bases de conocimiento ocurren con mayor frecuencia, lo que exige procesos de liberación auditables en lugar de despliegues únicos.
-
Límites de datos: Los datos de entrenamiento suelen estar en entornos controlados, mientras que la inferencia accede a datos de clientes, documentos internos e interfaces de sistemas empresariales, exigiendo permisos más estrictos y políticas de ocultación de datos.
Por tanto, al evaluar la infraestructura de IA empresarial, es más eficaz centrarse en las capacidades de la capa de servicios—como gateways, enrutamiento, observabilidad, liberación, permisos y auditoría—en vez de comparar simplemente el tamaño de los clústeres de entrenamiento.
Stack de inferencia de grado producción: desde la entrada hasta la observabilidad
Un stack de inferencia sólido suele incluir al menos los siguientes módulos. Aunque los proveedores pueden usar nombres de productos diferentes, las funciones centrales son consistentes.
Gateway de API y gobernanza de tráfico
Un punto de entrada unificado para autenticación, cuotas, limitación de tasa y terminación TLS; al exponer capacidades de modelos externamente, el gateway es la primera línea de defensa para la seguridad y la estrategia empresarial.
Enrutamiento de modelos y gestión de versiones
Las empresas suelen ejecutar varios modelos simultáneamente (para tareas, costes y niveles de cumplimiento diversos). El enrutamiento debe admitir desvíos por arrendatario, escenario y nivel de riesgo, así como lanzamientos grises y reversión, para evitar fallos por reemplazos “de golpe”.
Serialización, procesamiento por lotes y caché
Bajo alta concurrencia, la serialización/deserialización, las estrategias de procesamiento por lotes y el diseño de caché KV o semántico afectan significativamente la latencia final y el coste. El caché también introduce riesgos de consistencia, exigiendo políticas claras de invalidación y datos sensibles.
Recuperación vectorial e integración RAG (si aplica)
La generación aumentada por recuperación vincula la inferencia con los sistemas de datos: actualización de índices, filtrado de permisos, visualización de fragmentos de referencia y control de riesgo de alucinación son parte integral del framework operativo, no “extras” fuera del modelo.
Observabilidad, registro y contabilidad de costes
Como mínimo, el uso de tokens, los percentiles de latencia y los tipos de error deben desglosarse por arrendatario, versión de modelo y política de enrutamiento. Sin esto, la planificación de capacidad es difícil y las revisiones post-incidente no pueden identificar con precisión si el origen del problema está en el modelo, los datos o el gateway.
Estos módulos determinan si la experiencia online es estable, los costes son controlables y los problemas son rastreables. La ausencia de cualquier componente suele producir sistemas que funcionan bien en demos de baja carga pero revelan defectos bajo cargas máximas o cambios.
Despliegue multimodelo e híbrido: enrutamiento, costes y soberanía de datos
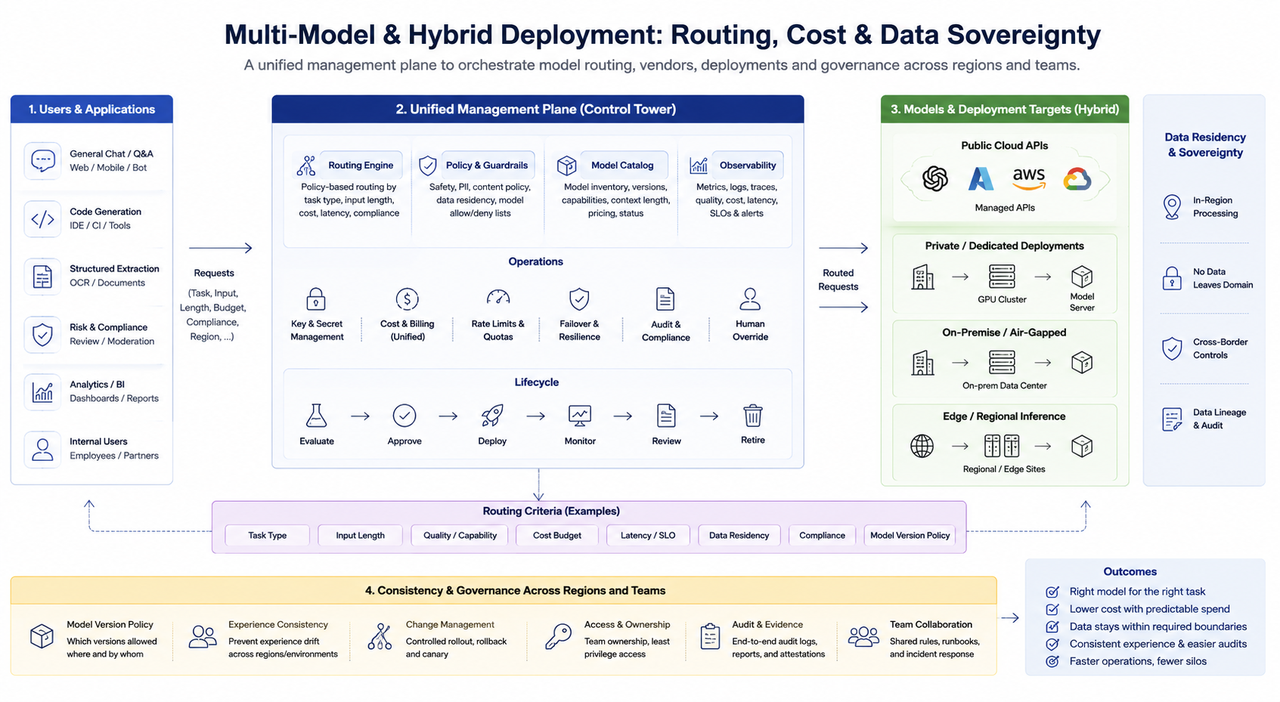
En entornos empresariales es común la coexistencia de varios modelos: tareas como conversación general, código, extracción estructurada y revisión de control de riesgos no se adaptan a un solo modelo o estrategia de parámetros. Los principales retos de ingeniería en configuraciones multimodelo incluyen:
-
Estrategia de enrutamiento: Selección de modelos según tipo de tarea, longitud de entrada, restricciones de coste y requisitos de cumplimiento; requiere estrategias por defecto interpretables y sobrescritura manual operativa.
-
Mezcla de proveedores: APIs de nube pública, despliegues locales y clústeres dedicados pueden coexistir; la gestión unificada de claves, los estándares de facturación y el failover son esenciales para evitar que “varios proveedores sean silos aislados”.
-
Nube híbrida y residencia de datos: Operaciones financieras, gubernamentales y transfronterizas suelen exigir que los datos permanezcan en un dominio o jurisdicción; el despliegue de inferencia define la arquitectura de red y la ubicación del caché, interactuando con infraestructura de tercer nivel como centros de datos, energía y redes regionales.
-
Gobernanza de consistencia: Se necesitan políticas claras para determinar si la misma empresa en distintas regiones o entornos puede usar diferentes versiones de modelo; de lo contrario, se producirán desviaciones de experiencia y desafíos de auditoría.
Desde una perspectiva organizacional, la dificultad de los sistemas multimodelo suele radicar no en el “número de modelos”, sino en la ausencia de un plano de gestión unificado. Cuando las reglas de enrutamiento, claves, monitorización y procesos de liberación están dispersos entre equipos, los costes de resolución de problemas y cumplimiento aumentan rápidamente.
Agente: orquestación, límites de herramientas y auditabilidad
Los agentes extienden la inferencia a tareas de varios pasos: planificación, invocación de herramientas, operaciones de memoria y generación de acciones siguientes. Para sistemas empresariales, esto implica que la superficie de riesgo se amplía de “salida de texto” a impactos ejecutables en sistemas externos.
Las áreas clave de enfoque en la práctica incluyen:
-
Lista blanca de herramientas y privilegio mínimo: Cada herramienta debe tener ámbitos de permisos claramente definidos (bases de datos de solo lectura, APIs restringidas, rutas de archivos limitadas, etc.) para evitar invocaciones de herramientas “omnipotentes” demasiado amplias.
-
Colaboración humano-máquina y puntos de confirmación: Para acciones de alto riesgo como transferencias de fondos, cambios de permisos o exportaciones masivas de datos, hay que imponer flujos de confirmación o aprobación obligatorios en vez de automatización total.
-
Estado de sesión y límites de memoria: La memoria a largo plazo implica ciclos de privacidad y retención; el contexto a corto plazo afecta el coste y las estrategias de truncado. La jerarquización y limpieza de datos deben alinearse con los requisitos de cumplimiento.
-
Rastro auditable: Registrar “cuándo el modelo, con qué contexto, invocó qué herramientas y qué se devolvió”; las revisiones de incidentes y las consultas regulatorias suelen depender de esto, no solo de la respuesta final.
-
Sandbox y aislamiento: La ejecución de código y la carga de plugins requieren entornos de ejecución aislados para evitar que la inyección de prompts escale a ataques a nivel de ejecución.
Los agentes aportan valor mediante la automatización, pero solo cuando los límites están claramente definidos. Si los límites son difusos, la complejidad del sistema puede aumentar exponencialmente y los costes operativos y legales pueden desbordarse antes de obtener cualquier beneficio empresarial.
Seguridad y cumplimiento: el “conjunto mínimo” para lanzamiento y operación
Los requisitos de cumplimiento varían según el sector, pero los sistemas de producción empresariales deben al menos cumplir el siguiente “conjunto mínimo”, ampliándose según las demandas regulatorias.
-
Identidad y acceso: Cuentas de servicio, cuentas de usuario, rotación de claves API y principio de privilegio mínimo; distinguir entre credenciales de “desarrollo/pruebas” y de “invocación en producción”.
-
Datos y privacidad: Ocultación de campos sensibles, ocultación en registros, separación de datos de entrenamiento e inferencia; definir y conservar claramente los acuerdos de procesamiento de datos con proveedores de modelos de terceros.
-
Cadena de suministro de modelos: Trazabilidad de fuentes de modelos, hashes de versión, dependencias e imágenes de contenedores; evitar que “pesos desconocidos” entren en el camino de producción.
-
Seguridad de contenido y prevención de abusos
-
Aplicar filtrado de políticas a entradas/salidas según sea necesario; implementar limitación de tasa y detección de anomalías para llamadas automáticas por lotes.
-
Respuesta ante incidentes: Reversión de modelos, cambio de enrutamiento, revocación de claves, procedimientos de notificación a clientes; especificar claramente responsables y vías de escalada.
Estas capacidades no sustituyen la defensa en profundidad del equipo de seguridad, pero son esenciales para integrar los servicios de IA en el marco de gestión de riesgos existente de la empresa, en vez de dejarlos como “excepciones de innovación” a largo plazo.
Conclusión
La ventaja competitiva en la IA empresarial está migrando de “si se puede integrar el último modelo” a “si se pueden operar varios modelos y agentes con costes controlables y límites seguros”. Esto exige fortalecer tanto los stacks de ingeniería como de gobernanza: el enrutamiento y la liberación, la observabilidad y la gestión de costes, los permisos de herramientas y los rastros de auditoría deben considerarse esenciales de producción al mismo nivel que los propios modelos.









