المؤلف: CJ_Blockchain
في 3 فبراير 2025، تم إطلاق نموذج DeepSeek-R1 بشكل سري على منصة الإنترنت للحوسبة الفائقة الوطنية.
وفي الشهر التالي، وبفضل أدائه الذي يقارن مباشرة بأفضل النماذج المغلقة، وتكاليف تدريبه التي تكاد تكون “رخيصة جدًا”، اجتاح العالم بأسره.
مما أدى إلى هبوط حاد في أسهم شركات الذكاء الاصطناعي في السوق الأمريكية وفتح لحظة “DeepSeek” الخاصة بالصين في مجال الذكاء الاصطناعي.
في 10 مارس 2026، أعلن شبكة Templar التابعة لـ Bittensor، عن إكمال أكبر عملية تدريب لنموذج لغة كبير (LLM) لامركزية في التاريخ — Covenant-72B
وهذا هو أكبر تدريب لنموذج لغة كبير لامركزي في التاريخ:
72 مليار معلمة، على مجموعة بيانات تتكون من حوالي 1.1 تريليون رمز، تم تنفيذه بالكامل عبر شبكة Templar التابعة لـ Bittensor، بدون إذن، بمشاركة أكثر من 70 عقدة مستقلة بحرية.
لقد شهدت Bittensor لحظة DeepSeek الخاصة بها.
1. Templar (SN3): تحول في نموذج جمع البيانات والتدريب الأساسي
كان Templar سابقًا يُعرف بـ SN3، الذي تديره Omega Labs، وتركز في البداية على جمع واستكشاف البيانات متعددة الوسائط. ومع تطور آلية Bittensor، حققت هذه الشبكة قفزة استراتيجية من “عامل نقل البيانات” إلى “صانع نماذج”.
حاليًا، يُعتبر Templar البنية التحتية للتدريب المسبق للنماذج الكبيرة الموزعة عالميًا. يجمع بين الحوافز العالمية لتوحيد قدرات الحوسبة غير المتجانسة، بهدف حل مشكلة التكاليف الحسابية الباهظة والمراجعة المركزية أثناء تدريب النماذج الكبيرة. نجاح تسليم Covenant-72B يثبت نضج هذا النموذج الإنتاجي اللامركزي.
2. Covenant-72B: كسر حاجز حجم التدريب اللامركزي
Covenant-72B هو إنجاز تاريخي من إنتاج Templar، وهو أكبر نموذج تدريب كثيف في شبكة لامركزية حتى الآن.
- المعلمات الأساسية: 720 مليار معلمة، تم تدريبه على مجموعة بيانات عالية الأداء DCLM.
- الأداء المقارن: يتساوى أداؤه مع نموذج Meta Llama-2-70B في تقييمات النماذج الأساسية.
- تحسين الأوامر: بعد التخصيص الدقيق، أظهر Covenant-72B-Chat قوة تنافسية عالية في مجالي IFEval (اتباع الأوامر) و MATH (الاستنتاج الرياضي)، وتفوق على نماذج مغلقة من نفس الحجم في بعض المقاييس.
- كفاءة الاستدلال: حقق معدل معالجة يصل إلى 450 رمز/ثانية، مما يعالج مشكلة التأخير في استجابة النماذج الكبيرة في التطبيقات العملية.
3. خوارزمية SparseLoCo: المحرك الأساسي للتدريب اللامركزي
في بيئة الإنترنت العادية، التحدي الأكبر في تدريب نموذج بحجم 72B هو عنق الزجاجة في عرض النطاق الترددي بين العقد. استخدمت Templar خوارزمية SparseLoCo لتحقيق قفزة نوعية:
- ضغط شديد: تختار الخوارزمية فقط 1%-3% من مكونات التدرج الأساسية للنقل، وتقوم بتكميم البيانات إلى 2-bit، مما يقلل بشكل كبير من الحاجة إلى عرض النطاق الترددي.
- تزامن منخفض التكرار: على عكس التزامن في كل خطوة في التجمعات التقليدية، يسمح SparseLoCo للعقد بالتكرار محليًا بين 15 و250 خطوة قبل التزامن العالمي.
- تعويض الخطأ: من خلال آلية تراكم التدرجات المحلية، تضمن أن دقة تقارب النموذج لا تتأثر حتى مع فقدان أكثر من 97% من المعلومات.
يثبت هذا النهج التكنولوجي أنه حتى بدون شبكات خاصة مكلفة مثل InfiniBand، يمكن الاعتماد على الشبكة العالمية العادية لتحقيق ذكاء من الطراز العالمي.
4. تقييم الصناعة ورد فعل السوق
أثارت إنجازات Templar اهتمام المجتمع الرئيسي للذكاء الاصطناعي وأسواق رأس المال:
قال جاك كلارك، أحد المؤسسين المشاركين لشركة Anthropic، في تقريره إن Templar يُصنف كأكبر شبكة تدريب لامركزية نشطة في العالم، وأشار إلى أن وتيرة تطوره فاقت توقعات الصناعة.
قال جايسون كالاكانيس (مقدم بودكاست All-In ومستثمر وادي السيليكون المعروف) في مدونته الأخيرة إنه شرح آلية عمل Bittensor بعمق، وألمح إلى أن الجميع يجب أن يشتروا.
تواصل شركة Grayscale زيادة حيازتها لـ TAO، وتعتبرها مركزًا رئيسيًا في مسار الذكاء الاصطناعي اللامركزي.
أسست DCG شركة Yuma، التي تركز على تسريع تطوير نظام Bittensor (TAO)، وتُعتبر أكبر وأوضح استثمار في الذكاء الاصطناعي اللامركزي.
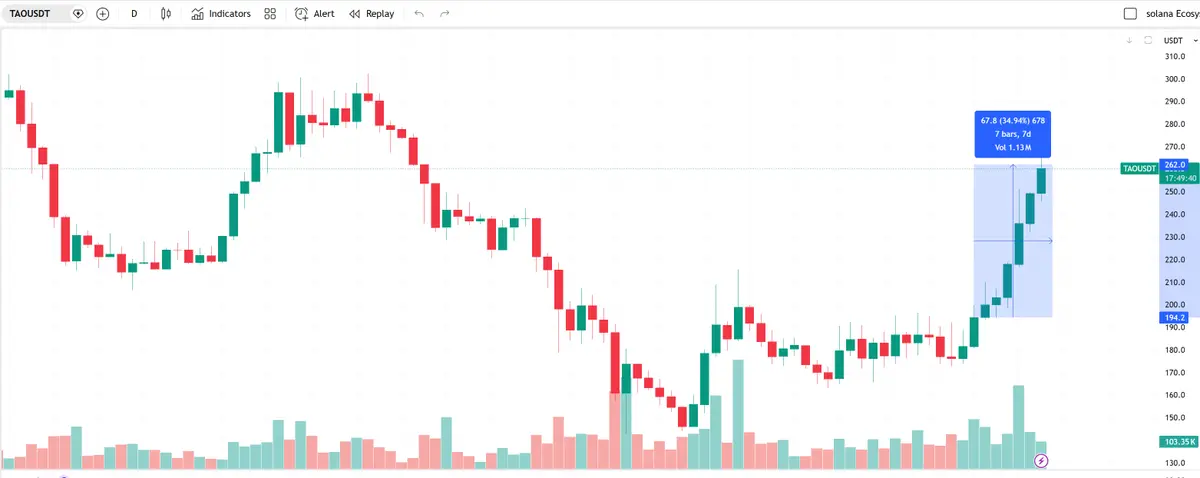
$TAO: بعد إعلان Templar عن إكمال تدريب النموذج الكبير 72B، ارتفع سعر TAO بأكثر من 30%، وأظهر قوة واضحة خلال تقلبات البيتكوين.
$Templar (SN-3): ارتفع Templar بنسبة 75% خلال 7 أيام، ويُعتبر الآن أحد أكبر الرابحين في إصدار Bittensor. القيمة السوقية الحالية فقط 70 مليون دولار.
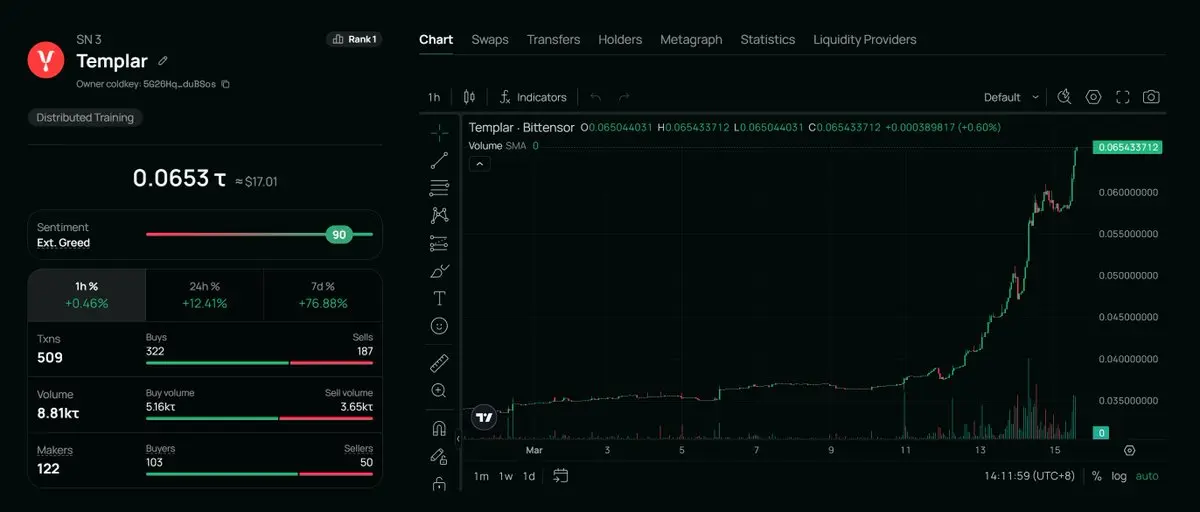
5. إمكانات استثمار الشبكات وعتبة النظام البيئي
نجاح Templar يفتح آفاقًا جديدة لنظام Bittensor البيئي:
- توسيع قيمة العتبة: لطالما شكك الآخرون في أن Bittensor مجرد “تحفيز هوائي”. أثبت Templar أن البروتوكول قادر على إنتاج أدوات إنتاجية ذات قدرة تنافسية تجارية، مما يحول منطق تقييم TAO من “السرد القصصي” إلى “المنتج”.
- إمكانات الحوسبة غير المتجانسة: مع تطوير “SparseLoCo غير المتجانس”، ستتمكن بطاقات الرسوميات الاستهلاكية (مثل RTX 4090) من المشاركة مباشرة في تدريب نماذج تتجاوز مئات المليارات من المعلمات، مما يحقق المساواة في الموارد الحسابية.
- فرص الشبكة المحددة: في ظل آلية dTAO، فإن الشبكات التي تمتلك تقنيات متقدمة وتستطيع إنتاج نماذج عالية الأداء، مثل Templar، تمتلك قيمة طويلة الأمد عالية جدًا.
Templar حاليًا بقيمة سوقية قدرها 75 مليون دولار، وقيمة سوقية كاملة مقدرة بـ 350 مليون دولار.
بينما تقدر قيمة الشركات الكبرى في النماذج الكبيرة مثل OpenAI بـ 840 مليار دولار، وAnthropic بـ 350 مليار دولار، وMinimax بـ 45 مليار دولار.
لا يعني ذلك أن Templar يمكن أن يُقارن مباشرة بهذه الشركات، لكن في ظل غياب السرد القصصي وغياب الثقة في اللامركزية، فإن ظهور Templar بلا شك يعزز الثقة في الذكاء الاصطناعي اللامركزي.
الختام
ثبت أن البيئة اللامركزية لا تقتصر على تخزين البيانات فحسب، بل يمكنها أيضًا إنتاج الذكاء. Covenant-72B هو مجرد بداية، ومع التكامل الأفقي بين SN3 (التدريب المسبق)، وSN39 (الحوسبة)، وSN81 (التعلم المعزز)، يظهر الآن نموذج لذكاء اصطناعي لامركزي يعمل على البلوكشين.
منذ نشأة صناعة العملات الرقمية وحتى اليوم، تم دحض العديد من السرديات، وتبدو مشاريع التخزين اللامركزي، والحوسبة اللامركزية، والحواسيب اللامركزية قد تم دحضها، لكن من الرائع أن هناك مشاريع تواصل السير على طريق اللامركزية وتحقق إنجازات.
نجاح Templar ليس فقط لحظة DeepSeek لـ Bittensor، بل ربما يكون أيضًا لحظة DeepSeek للعملات الرقمية.
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
